Un amigo que dirige una agencia de contenido me dijo la semana pasada mientras tomábamos café: "oye, hemos probado todos los detectores de IA que existen y son todos humo." Le dije que creía que podía construir uno mejor. Se rió. Bueno, vale, totalmente justo.
El AI Content Detector que construí funciona completamente en el navegador. Sin subidas, sin suscripciones, sin APIs en la nube cobrándote por escaneo. Usa diez métricas estadísticas y dieciocho señales a nivel de oración para determinar si un texto fue escrito por un humano o generado por ChatGPT, Claude, Gemini, o cualquier LLM que la gente esté usando está semana. Quiero explicar cómo funciona realmente, porque la mayoría de las páginas de marketing de "detectores de IA" son deliberadamente vagas sobre su metodología.
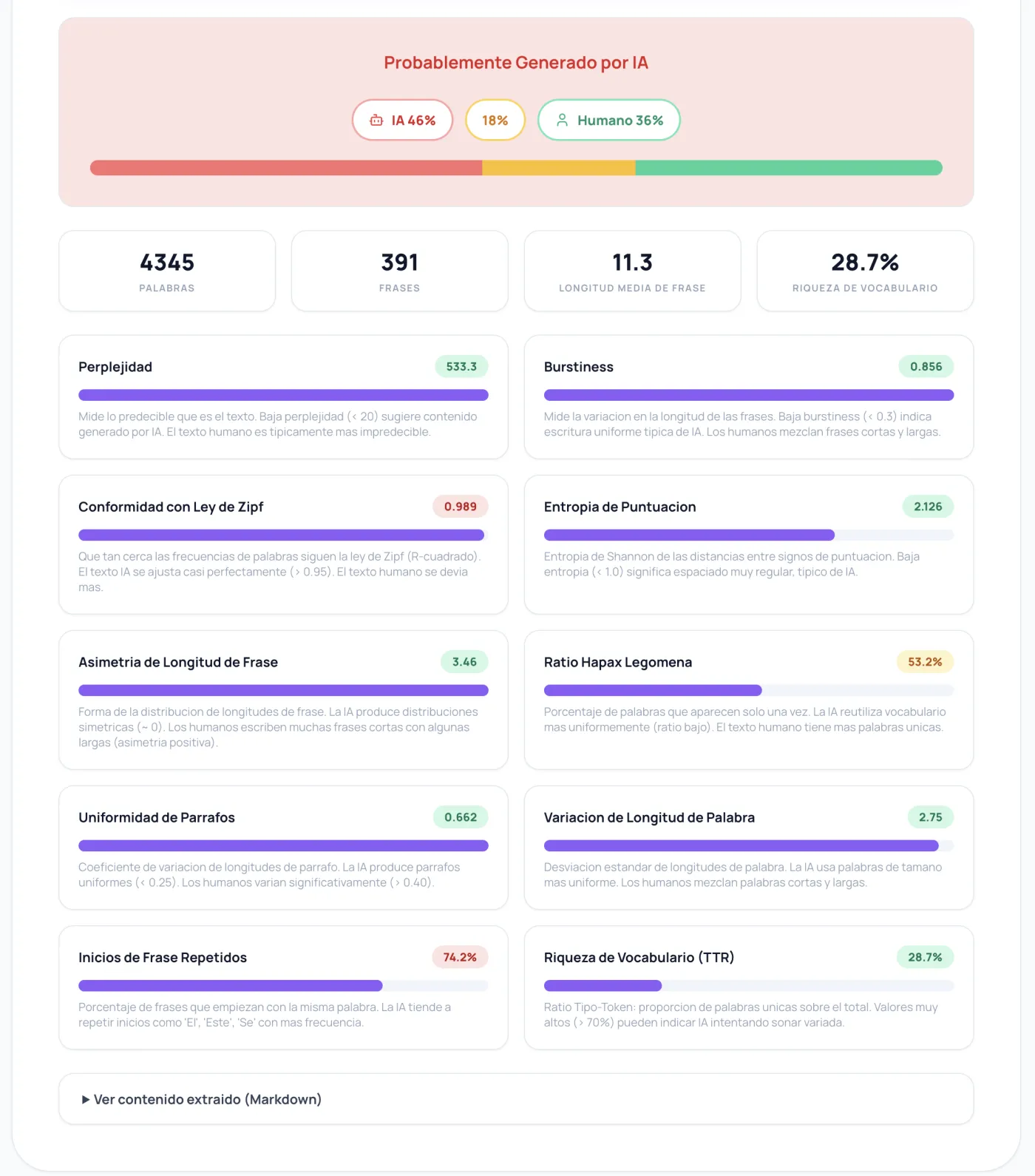
Por qué la perplejidad y la burstiness solas no son suficientes
Todos los artículos sobre detección de IA mencionan la perplejidad y la burstiness. Son métricas reales, miden algo útil, pero está es la verdad incómoda que descubrí tras semanas de pruebas: los modelos de IA modernos como GPT-4 y Claude producen texto con alta perplejidad y alta burstiness. Han sido entrenados para sonar humanos. Depender solo de estas dos métricas es como intentar atrapar a un ladrón comprobando si usó la puerta principal.
La perplejidad mide lo predecibles que son las secuencias de palabras (baja = robótico, alta = creativo). La burstiness mide la variación en la longitud de las oraciones (baja = uniforme, alta = variada). La IA de la vieja escuela de 2022 fallaba en ambas pruebas de forma espectacular. Pero los modelos de 2025-2026 las pasan sin despeinarse.
Entonces, ¿qué funciona realmente?
Las diez métricas que importan
Después de hacer benchmarks contra artículos que sabía que eran generados por IA y artículos que sabía que eran humanos (usé un conjunto de diez URLs reales que iban desde MIT Technology Review hasta blogs genéricos de SEO sobre café), descubrí que estas señales, combinadas, producen resultados que son realmente útiles:
La conformidad con la Ley de Zipf resultó ser la métrica individual más fiable. Todo lenguaje natural sigue la ley de Zipf: la segunda palabra más común aparece la mitad de veces que la primera, la tercera aparece un tercio de veces, y así sucesivamente. El texto humano se desvía de está curva porque nos obsesionamos con ciertas palabras, nos vamos por las ramas, hacemos elecciones de palabras raras. El texto de IA sigue la ley de Zipf casi perfectamente porque está muestreando distribuciones de probabilidad que inherentemente producen salidas zipfianas. Cálculo el R-cuadrado de log-rango vs log-frecuencia y cualquier cosa por encima de 0.96 es sospechosa.
Los inicios de oración repetidos son vergonzosamente simples pero detectan un montón de IA. Cuenta qué porcentaje de oraciones empiezan con la misma palabra. A la IA le encanta empezar oraciones con "The", "This", "It", "In". He visto artículos de IA donde el 70%+ de las oraciones empiezan con una de cuatro palabras. Los humanos somos más caóticos en eso sin siquiera intentarlo.
La entropía de puntuación mide la entropía de Shannon de las distancias entré signos de puntuación. La IA coloca comas y puntos a intervalos notablemente regulares. Los humanos somos caóticos; a veces escribimos tres oraciones cortas seguidas, luego una larga con cinco comas, luego un fragmento.
La asimetría de longitud de oración captura la forma de la distribución de longitudes de oración. La IA produce distribuciones casi simétricas (campana de Gauss). Los humanos escribimos con asimetría positiva: muchas oraciones cortas, algunas medianas y la ocasional oración monstruosa que se te escapa de las manos.
La proporción de hapax legomena cuenta qué porcentaje de palabras aparecen una sola vez en el texto. El texto humano tiene más palabras únicas porque usamos vocabulario específico y contextual. La IA reutiliza las palabras de forma más uniforme a lo largo del texto.
La uniformidad de párrafos es el coeficiente de variación de las longitudes de párrafo. La IA produce párrafos notablemente uniformes. Los humanos escribimos un párrafo de dos oraciones seguido de uno de doce sin pensarlo.
Las cuatro métricas restantes (perplejidad, burstiness, riqueza de vocabulario, desviación estándar de longitud de palabra) contribuyen con pesos menores. Ayudan a desempatar pero ya no son las estrellas del equipo.
El truco real: puntuación multiplicativa de señales
Aquí es donde se pone interesante. Las señales individuales se solapan entré texto de IA y humano todo el tiempo. Un humano puede usar guiones (señal de IA) o tener párrafos uniformes (señal de IA). Pero los humanos casi nunca tienen guiones Y párrafos uniformes Y palabras de transición Y sin contracciones Y estructura formulista Y inicios repetidos, todo en la misma oración.
El texto de IA tiene clusters de señales co-ocurrentes. Cuando tres o más señales de IA aparecen en la misma oración, la puntuación no solo se suma; se multiplica. Una oración con dos señales de IA puntúa normalmente. ¿Tres señales? Puntuación multiplicada por 1.5x. ¿Cuatro o más? Multiplicada por 2x. Este enfoque multiplicativo captura algo que la puntuación lineal no detecta: la diferencia entre "ocasionalmente parece IA" y "esto es obviamente un patrón."
El clasificador a nivel de oración rastrea dieciocho señales separadas por oración: uniformidad de longitud, uso de guiones, palabras de transición, frases de rellenó ("es importante notar", "juega un papel crucial"), vocabulario sobreutilizado ("leverage", "comprehensive", "facilitate"), patrones de negrita-luego-explicación, ganchos tipo "Here's what/why/how", densidad de nombres propios, contracciones, paréntesis, preguntas, lenguaje informal, voz pasiva, repetición de inició, finales con dos puntos, punto y coma, listas numeradas y patrones de conclusión.
Modo URL y extracción de contenido
Puedes pegar texto directamente o introducir una URL. En modo URL, la herramienta obtiene el HTML, elimina navegación, barras laterales, pies de página, imágenes, scripts y todos los elementos no textuales, y luego convierte el contenido restante a Markdown usando Turndown. Puedes expandir el contenido extraído debajo de los resultados para verificar qué analizó realmente la herramienta. Algunos sitios cargan contenido mediante JavaScript (renderizado del lado del cliente), que el fetcher no puede capturar; para esos, la pestaña de texto funciona mejor.
La obtención de URL primero intenta tu navegador (sin servidor involucrado). Si CORS lo bloquea, un proxy Edge ligero interviene con un límite de cinco peticiones por minuto.
Dónde se queda cortó
No voy a pretender que esto es perfecto.
La mayor debilidad: texto de IA bien escrito que ha sido ligeramente editado por un humano. Si alguien genera un borrador con ChatGPT y luego reescribe un tercio de las oraciones, añade una anécdota personal y elimina las palabras de transición, nuestro detector (y cualquier otro detector) tendrá problemas. Es una limitación fundamental de los enfoques estadísticos.
La segunda debilidad: alguna escritura humana es genuinamente formulista. Comunicados de prensa corporativos, documentos legales, abstracts académicos. Estos activan señales de IA porque carecen del desorden que los detectores estadísticos buscan. No es exactamente un bug, pero sí produce falsos positivos en una categoría de texto que nadie llamaría escritura creativa.
La tercera debilidad: texto muy cortó. Por debajo de unas 200 palabras, no hay suficiente señal estadística para que ninguna de las métricas sea fiable.
Comparado con GPTZero, Originality.ai, Copyleaks
Esos servicios usan clasificadores ML entrenados (redes neuronales entrenadas con millones de muestras etiquetadas IA/humano). En teoría, deberían ser más precisos que las heurísticas estadísticas como la mía. En la práctica, la brecha es menor de lo que pensarías, especialmente en textos largos. Sus modelos fueron entrenados con salidas de IA específicas y tienen problemas cuando aparecen modelos nuevos; los patrones estadísticos son más agnósticos al modelo.
Pues la verdadera ventaja del enfoque basado en navegador es sencilla: tu texto nunca sale de tu dispositivo, es gratis y va como un tiro. Si estás escaneando cien artículos de blog para una auditoría de contenido, eso mola más que unos pocos puntos porcentuales de precisión.
Pruébalo, vamos
El AI Content Detector está en Kitmul. Gratis, sin registró, funciona en tu navegador. Mira, pruébalo con algo que sepas que es generado por IA, pruébalo con algo que hayas escrito tú, y dime si los resultados coinciden con tu intuición.
Próximamente: un escáner de sitemap que rastreará cada URL en tu sitemap.xml y te dirá qué páginas parecen generadas por IA. Ese va a ser divertido, oye.
Herramientas relacionadas: Text Readability Scorer · Sentiment Analyzer · Keyword Extractor · Text Tone Analyzer · Syllable Counter
Referencias: