Ein Freund, der eine Content-Agentur leitet, sagte mir letzte Woche beim Kaffee: "Wir haben jeden KI-Detektor da draußen ausprobiert und die sind alle Schlangenöl." Ich sagte ihm, ich dachte, ich könnte einen besseren bauen. Er hat gelacht. Verständlich.
Der AI Content Detector, den ich gebaut habe, läuft komplett im Browser. Keine Uploads, keine Abonnements, keine Cloud-API, die pro Scan abrechnet. Er nutzt zehn statistische Metriken und achtzehn Signale auf Satzebene, um herauszufinden, ob ein Text von einem Menschen geschrieben oder von ChatGPT, Claude, Gemini oder welchem LLM auch immer die Leute diese Woche benutzen, generiert würde. Ich möchte erklären, wie es wirklich funktioniert, weil die meisten Marketing-Seiten von "KI-Detektoren" absichtlich vage über ihre Methodik sind.
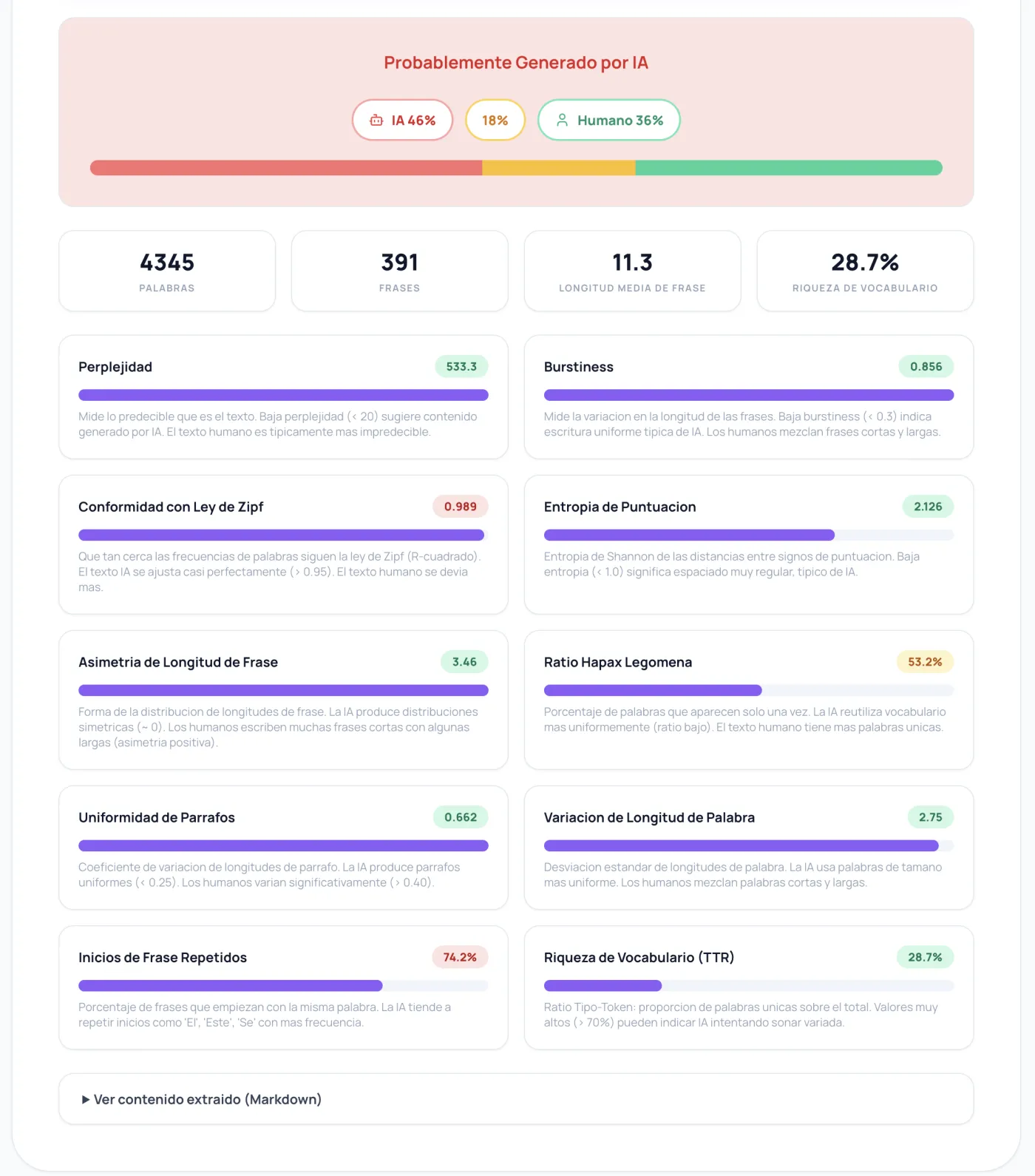
Warum Perplexität und Burstiness allein nicht reichen
Jeder Blogartikel über KI-Erkennung erwähnt Perplexität und Burstiness. Das sind echte Metriken, sie messen etwas Nützliches, aber hier ist die unbequeme Wahrheit, die ich nach Wochen des Testens entdeckt habe: Moderne KI-Modelle wie GPT-4 und Claude produzieren Text mit höher Perplexität und höher Burstiness. Sie würden trainiert, menschlich zu klingen. Sich nur auf diese beiden Metriken zu verlassen, ist wie zu versuchen, einen Einbrecher zu fangen, indem man prüft, ob er die Haustür benutzt hat.
Perplexität misst, wie vorhersagbar Wortsequenzen sind (niedrig = robotisch, hoch = kreativ). Burstiness misst die Variation der Satzlänge (niedrig = gleichförmig, hoch = variiert). Die Old-School-KI von 2022 versagte bei beiden Tests auf spektakuläre Weise. Aber die Modelle von 2025-2026? Die bestehen mit Bravour.
Was funktioniert also wirklich?
Die zehn Metriken, die zählen
Nachdem ich Benchmarks gegen Artikel durchgeführt hatte, von denen ich wusste, dass sie KI-generiert waren, und Artikel, von denen ich wusste, dass sie von Menschen stammten (ich benutzte ein Set von zehn echten URLs, von MIT Technology Review bis zu generischen SEO-Kaffeeblogs), stellte ich fest, dass diese Signale, kombiniert, Ergebnisse produzieren, die tatsächlich nützlich sind:
Die Konformität mit dem Zipfschen Gesetz erwies sich als die zuverlässigste einzelne Metrik. Jede natürliche Sprache folgt dem Zipfschen Gesetz: Das zweithäufigste Wort erscheint halb so oft wie das erste, das dritthäufigste ein Drittel so oft, und so weiter. Menschlicher Text weicht von dieser Kurve ab, weil wir uns auf bestimmte Wörter fixieren, auf Tangenten abweichen, seltsame Wortwahlen treffen. KI-Text folgt dem Zipfschen Gesetz fast perfekt, weil er aus Wahrscheinlichkeitsverteilungen sampelt, die inhärent Zipf-artige Ausgaben produzieren. Ich berechne das R-Quadrat von Log-Rang vs. Log-Frequenz, und alles über 0,96 ist verdächtig.
Wiederholte Satzanfänge sind peinlich einfach, fangen aber eine Menge KI. Zähle, welcher Prozentsatz der Sätze mit dem gleichen Wort beginnt. KI liebt es, Sätze mit "The", "This", "It", "In" zu beginnen. Ich habe KI-Blogartikel gesehen, wo 70%+ der Sätze mit einem von vier Wörtern anfangen. Menschen sind da chaotischer, ohne es auch nur zu versuchen.
Die Interpunktions-Entropie misst die Shannon-Entropie der Abstände zwischen Satzzeichen. KI platziert Kommas und Punkte in bemerkenswert regelmäßigen Abständen. Menschen sind chaotisch; manchmal schreiben wir drei kurze Sätze hintereinander, dann einen langen mit fünf Kommas, dann ein Fragment.
Die Satzlängen-Schiefe erfasst die Form der Satzlängenverteilung. KI produziert nahezu symmetrische Verteilungen (Glockenkurve). Menschen schreiben mit positiver Schiefe: viele kurze Sätze, einige mittlere und der gelegentliche Monstersatz, der einem davonläuft.
Die Hapax-Legomena-Quote zählt, welcher Prozentsatz der Wörter nur einmal im Text vorkommt. Menschlicher Text hat mehr Einmalwörter, weil wir spezifisches, kontextbezogenes Vokabular verwenden. KI verwendet Wörter gleichmäßiger über den gesamten Text.
Die Absatzuniformität ist der Variationskoeffizient der Absatzlängen. KI produziert bemerkenswert gleichförmige Absätze. Menschen schreiben einen Zwei-Satz-Absatz gefolgt von einem Zwölf-Satz-Absatz, ohne darüber nachzudenken.
Die verbleibenden vier Metriken (Perplexität, Burstiness, Vokabelreichtum, Standardabweichung der Wortlänge) tragen mit geringeren Gewichten bei. Sie helfen bei Gleichständen, aber sie sind nicht mehr die Hauptakteure.
Der eigentliche Trick: multiplikative Signal-Bewertung
Hier wird es interessant. Einzelne Signale überlappen sich zwischen KI- und menschlichem Text ständig. Ein Mensch könnte Gedankenstriche verwenden (KI-Signal) oder gleichförmige Absätze haben (KI-Signal). Aber Menschen haben fast nie Gedankenstriche UND gleichförmige Absätze UND Übergangswörter UND keine Kontraktionen UND formelhafte Struktur UND wiederholte Anfänge, alles im selben Satz.
KI-Text hat Cluster von gemeinsam auftretenden Signalen. Wenn drei oder mehr KI-Signale im selben Satz erscheinen, addiert sich der Score nicht nur; er multipliziert sich. Ein Satz mit zwei KI-Signalen wird normal bewertet. Drei Signale? Score multipliziert mit 1,5x. Vier oder mehr? Multipliziert mit 2x. Dieser multiplikative Ansatz erfasst etwas, das lineare Bewertung verfehlt: den Unterschied zwischen "sieht gelegentlich KI-mäßig aus" und "das ist offensichtlich ein Muster."
Der Klassifikator auf Satzebene verfolgt achtzehn separate Signale pro Satz: Längenuniformität, Gedankenstrich-Nutzung, Übergangswörter, Füllphrasen ("es ist wichtig zu beachten", "spielt eine entscheidende Rolle"), überstrapaziertes Vokabular ("leverage", "comprehensive", "facilitate"), Fett-dann-Erklärung-Muster, "Here's what/why/how"-Hooks, Eigennamendichte, Kontraktionen, Klammerbemerkungen, Fragen, informelle Sprache, Passiv, Anfangswiederholung, Doppelpunkt-Enden, Semikolons, nummerierte Listen und Schlussmuster.
URL-Modus und Inhaltsextraktion
Man kann Text direkt einfügen oder eine URL eingeben. Im URL-Modus holt das Tool das HTML, entfernt Navigation, Seitenleisten, Fußzeilen, Bilder, Skripte und alle Nicht-Text-Elemente und konvertiert dann den verbleibenden Inhalt mit Turndown in Markdown. Man kann den extrahierten Inhalt unter den Ergebnissen aufklappen, um zu überprüfen, was das Tool tatsächlich analysiert hat. Einige Seiten laden Inhalte über JavaScript (Client-Side-Rendering), was der Fetcher nicht erfassen kann; für die funktioniert der Text-Tab besser.
Der URL-Fetch versucht zuerst den eigenen Browser (kein Server beteiligt). Wenn CORS blockiert, springt ein leichtgewichtiger Edge-Proxy mit einem Limit von fünf Anfragen pro Minute ein.
Wo es schwächelt
Ich werde nicht so tun, als wäre das perfekt.
Die größte Schwäche: gut geschriebener KI-Text, der leicht von einem Menschen bearbeitet würde. Wenn jemand einen Entwurf mit ChatGPT generiert und dann ein Drittel der Sätze umschreibt, eine persönliche Anekdote hinzufügt und die Übergangswörter entfernt, wird unser Detektor (und jeder andere Detektor) Probleme haben. Das ist eine fundamentale Einschränkung statistischer Ansätze.
Die zweite Schwäche: Manches menschliche Schreiben ist genuinformelhaft. Firmenpressemitteilungen, juristische Dokumente, akademische Abstracts. Diese lösen KI-Signale aus, weil ihnen die Unordnung fehlt, nach der statistische Detektoren suchen. Das ist nicht direkt ein Bug, aber es produziert Falsch-Positive bei einer Textkategorie, die niemand als kreatives Schreiben bezeichnen würde.
Die dritte Schwäche: sehr kurzer Text. Unter etwa 200 Wörtern gibt es nicht genug statistisches Signal, damit irgendeine der Metriken zuverlässig wäre.
Im Vergleich zu GPTZero, Originality.ai, Copyleaks
Diese Dienste verwenden trainierte ML-Klassifikatoren (neuronale Netze, trainiert auf Millionen von gelabelten KI/Mensch-Samples). Theoretisch sollten sie genauer sein als statistische Heuristiken wie meine. In der Praxis ist der Abstand geringer, als man denken würde, besonders bei längeren Texten. Ihre Modelle würden auf spezifische KI-Ausgaben trainiert und haben Schwierigkeiten, wenn neue Modelle auftauchen; statistische Muster sind modellagnostischer.
Der echte Vorteil des browserbasierten Ansätzes: Dein Text verlässt nie dein Gerät, es ist kostenlos und es ist sofort. Wenn du hundert Blogartikel für ein Content-Audit scannst, zählt das mehr als ein paar Prozentpunkte Genauigkeit.
Probier es aus
Der AI Content Detector ist auf Kitmul. Kostenlos, keine Anmeldung, läuft im Browser. Teste ihn mit etwas, von dem du weißt, dass es KI-generiert ist, teste ihn mit etwas, das du selbst geschrieben hast, und schau, ob die Ergebnisse zu deiner Intuition passen.
Als Nächstes: ein Sitemap-Scanner, der jede URL in deiner sitemap.xml durchgeht und einen Bericht erstellt, welche Seiten KI-generiert aussehen. Das wird spaßig.
Verwandte Tools: Text Readability Scorer · Sentiment Analyzer · Keyword Extractor · Text Töne Analyzer · Syllable Counter
Referenzen: