
Am letzten Mittwoch habe ich 176 Millionen Anthropic-Tokens verbrannt. Den Ausschlag sehen Sie im Screenshot weiter unten. Das meiste war produktive Arbeit mit Claude Code, aber als ich der Anomalie nachging, fand ich einen Batch-Job, der still und leise rohes HTML an Claude Sonnet 4.5 zur Zusammenfassung schickte. Die Prompts funktionierten; das Token-Budget nicht. Als ich schließlich ansah, was mein Scraper dem Modell tatsächlich gab, waren rund 70% jeder Anfrage <div class="css-1f2x">-Suppe. Der eigentliche Artikel, der Teil, der mich interessierte, war vielleicht 25% des Payloads.
Der Fix war eine Fünf-Zeilen-Änderung: HTML in Markdown umwandeln, bevor es ans Modell geht. Der Token-Count fiel um 60%. Gleiche Ausgabequalität. Ich hätte das gern früher gewusst.
Dieser Beitrag handelt davon, warum das funktioniert, wann es wichtig ist und welche verwandten Probleme derselbe Trick löst.
Warum HTML ein Token-Desaster ist
LLMs tokenisieren Text. Anthropic stellt einen Endpoint zum Token-Zählen in der Claude-API bereit, und OpenAIs Open-Source-tiktoken liefert eine vergleichbare Sicht: Englische Prosa zerfällt in etwa einen Token pro 3-4 Zeichen. Aber HTML ist keine Prosa. Es ist ein verschachtelter Baum aus Tags, Klassennamen, Inline-Styles, SVG-Attributen und JSON-Blobs, die moderne Frameworks in data-*-Attribute kippen.
Sie können das selbst prüfen. Fügen Sie einen Absatz Klartext in Anthropics Token-Counter ein und notieren Sie die Zahl. Dann wickeln Sie ihn in ein typisches React-generiertes <div class="prose dark:prose-invert max-w-none sm:px-6 lg:px-8"> und zählen erneut. Allein dieser Wrapper, diese eine Zeile, kann 30-40 Tokens kosten. Multipliziert mit einer gescrapten Seite mit 500 verschachtelten Divs sehen Sie, wohin das Geld fließt.
Markdown dagegen ist für einen Tokenizer fast unsichtbar. Eine Überschrift sind zwei Zeichen: # . Fettdruck vier: **x**. Ein Link ist [text](url), und das Modell versteht das nativ, weil sein Trainingskorpus mit Markdown aus GitHub, Stack Overflow und Reddit gesättigt ist.
Ich habe einen schnellen Test mit dem Wikipedia-Artikel zum HTTP-Protokoll gemacht:
- Rohes HTML (aus dem Browser gespeichert): ~48.000 Tokens
- Bereinigtes HTML (Boilerpipe-Stil): ~22.000 Tokens
- Markdown-Konvertierung: ~8.900 Tokens
Das sind 81% Reduktion gegenüber roh und 60% gegenüber bereits bereinigtem HTML-Payload. Bei einem Modell, das pro Eingabe-Token abrechnet, ist das keine Mikro-Optimierung. Es ist der Unterschied zwischen einem tragfähigen Produkt und einem Stripe-Chargeback.
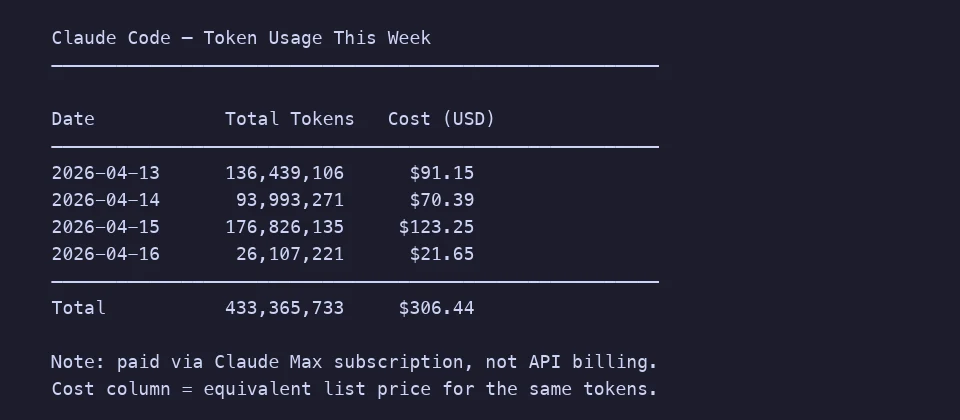
Zur Einordnung, hier eine Woche meiner tatsächlichen Claude-Code-Nutzung. Vier Tage, 433 Millionen Tokens, etwa 306 $ zu Listenpreisen (ich bin auf einem Max-Abo, aber der entsprechende Pay-as-you-go-Preis macht die Größenordnung greifbar). Das meiste davon ist produktives Coden. Stellen Sie sich vor, was 10-15% weniger strukturelles Rauschen über ein Jahr einspart.
Der RAG-Pipeline-Fall
Wer Retrieval-Augmented Generation baut, den betrifft das noch stärker. Ein typisches RAG-System:
- Crawlt oder scraped Quelldokumente
- Zerlegt sie in Chunks, die ins Kontextfenster des Embedding-Modells passen
- Embeddet jeden Chunk in eine Vektor-Datenbank
- Holt zur Query-Zeit die Top-K-Chunks und injiziert sie in den LLM-Prompt
Jeder dieser Schritte wird mit HTML im Spiel schlechter. Embeddings driften, weil das Modell CSS-Klassennamen neben tatsächlicher Bedeutung kodieren muss. Das Chunking wird ungleichmäßig; entweder trennen Sie mitten im Tag und verwirren den Retriever, oder Sie machen einen naiven Split nach Zeichen und schneiden einen Satz in der Mitte durch. Die Retrieval-Latenz wächst, weil der Vektorraum mit strukturellem Rauschen verschmutzt ist.
Die Umwandlung in Markdown vor dem Chunking löst alle drei. Die hervorragende LangChain-Dokumentation empfiehlt das leise: nützen Sie MarkdownHeaderTextSplitter oder RecursiveCharacterTextSplitter mit Markdown-Trennzeichen. Deren eigene Beispiele gehen erst durch HTML nach Markdown. Es gibt einen Grund.
Wenn Sie kein Python auf dem Server laufen lassen können
Viel HTML-zu-Markdown-Literatur setzt voraus, dass Sie ein Backend mit BeautifulSoup und markdownify haben. Schön, wenn Sie eine Pipeline bauen. Schmerzhaft, wenn Sie Content-Writer sind, Journalist beim Archivieren von Quellen oder Entwickler bei einer One-Off-Migration um 23 Uhr.
Ich habe Kitmul HTML to Markdown gebaut, weil ich immer wieder genau diesen Workflow brauchte und jede Option hasste. Das Tool läuft im Browser. HTML-Quelle einfügen, Markdown erhalten. Nichts wird hochgeladen, nichts telefoniert nach Hause. Die Konvertierung passiert per JavaScript auf Ihrer Maschine, das heißt Sie können interne Wiki-Exports, juristische Entwürfe oder Kundeninhalte ohne Hintergedanken einfügen.
Wer noch nie das HTML hinter einer Seite inspiziert hat: öffnen Sie einen Artikel, Rechtsklick, "Seitenquelltext anzeigen", kopieren Sie den Artikel-Body. Ins Tool einfügen. Was herauskommt, ist etwas, das Sie in einen Prompt, in Notion oder in ein Git-Repo packen können.
Sieben Stellen, wo das wirklich hilft
Ich habe lange gebraucht, um zu erkennen, wie viele meiner Probleme sich auf "Ich habe HTML und wünschte, es wäre Markdown" reduzieren. Eine unvollständige Liste:
Einen langen Artikel an ein LLM füttern. Die größten Gewinne kommen beim Zusammenfassen, Entitäten-Extrahieren oder Fragen über eine lange Webseite. Markdown wirft das Chrom weg und lässt die Substanz. Prompt-Kosten sinken, und ironischerweise wird das Modell auf der saubereren Eingabe besser, weil es nicht mehr von CSS abgelenkt wird.
Einen Blog von WordPress oder Ghost migrieren. Wer auf einen Static Site Generator wie Astro, Hugo oder Jekyll umzieht, braucht jeden Post als .md-Datei. Exportieren Sie das WordPress-XML, jagen Sie jeden <content:encoded>-Block durch den Konverter, legen Sie das Ergebnis in content/posts/ ab. Ich habe 84 Posts so an einem Abend umgezogen.
Recherche archivieren. Ich führe ein persönliches Wiki von Engineering-Artikeln, die ich oft referenziere. Seiten verschwinden ständig aus dem Web; die durchschnittliche Lebensdauer einer Webseite liegt unter 100 Tagen. Markdown-Snapshots lesen sich in Millisekunden, diffen sauber in Git und überleben Formatwechsel besser als Screenshots oder PDFs.
Trainingsdaten oder Few-Shot-Beispiele vorbereiten. Wer Beispiele fürs Fine-Tuning oder In-Context Learning kuratiert, will Konsistenz. Markdown ist die konsistente Form. Jede gescrapte Quelle endet in derselben Gestalt, mit derselben Überschriftenhierarchie und ohne zufällige <span>-Wrapper, die das Template verwirren.
Inhalte nach visuellen Editoren säubern. Tools wie Notion, Medium oder CKEditor exportieren technisch korrektes HTML, das aber voller <p><strong><em><u>-Verschachtelungen ist, die niemand will. Ein Zwischenschritt über Markdown kollabiert das auf die minimale semantische Form, und Sie bekommen eine portable, diffbare Quelle heraus.
Dokumentation aus gescrapten API-Referenzen schreiben. Ich habe das für drei SDKs gemacht. Gerendertes HTML der Anbieter-Docs holen (viele laufen auf MkDocs oder Docusaurus ohne verfügbare Markdown-Quelle), konvertieren, und Sie haben einen editier- und commitfähigen Ausgangspunkt. Schneller, als jeden Codeblock von Hand zu kopieren.
Kosten auf der Claude-API und der Gemini-API senken. Jedes Frontier-Modell berechnet Input-Tokens. Anthropics Prompt Caching hilft, aber 48K HTML zu cachen ist immer noch schlechter, als 9K Markdown zu cachen. Caches werden auch geräumt. Der günstigste Token ist der, den Sie nie senden.
Was bei der Konvertierung verloren geht
Seien Sie ehrlich bei den Trade-offs. Ein paar Dinge überleben nicht:
- Visuelle Gestaltung. Farben, Schriftarten, Custom-CSS. Wenn das Layout der Inhalt ist (Infografiken, Landingpages), ist Markdown das falsche Ziel.
- Interaktive Komponenten. Eingebettete Formulare, iframes, JavaScript-Widgets. Die werden zu einfachen Links oder verschwinden.
- Exakte Tabellenlayouts. Markdown-Tabellen bewältigen Zeilen und Spalten, aber verschmolzene Zellen, Colspans und verschachtelte Tabellen vereinfachen oder brechen. Für datenreiche Tabellen ist CSV-Export meist besser; unser CSV-zu-JSON-Tool deckt den Nachbarfall ab.
- Bildpositionierung. Markdown-Bilder sind inline, von oben nach unten. Float-Layouts übersetzen sich nicht.
Für 90% der textgetriebenen Webseiten spielt nichts davon eine Rolle. Für die restlichen 10% wollen Sie ohnehin das HTML.
Ein konkreter Workflow
Das ist die Routine, bei der ich für LLM-Arbeit gelandet bin:
- Seite mit
fetchoder Playwright scrapen und den innerHTML des Artikel-Bodys holen, nicht das ganze Dokument. Ein ordentlicher CSS-Selektor erledigt die halbe Reinigung. - Einmalig? Ins HTML-zu-Markdown-Tool einfügen. Batch? Eine Library wie
turndown(auf GitHub) odermarkdownifyin Python nützen. - Boilerplate entfernen (Cookie-Banner, "verwandte Posts", Newsletter-CTAs). Markdown macht das einfach: Rauschen ballt sich meist oben und unten.
- Ans Modell schicken. Länge Dokumente entlang Markdown-Überschriften chunken, nicht nach Zeichenzahl.
- Die Markdown-Version lokal cachen. Der nächste Lauf sollte Schritt 1 nicht wiederholen.
Das Ganze dauert meistens länger zu beschreiben als auszuführen.
Der größere Punkt
Formatkonvertierung klingt langweilig. Ist es auch, bis die API-Rechnung um 60% schrumpft, weil Sie aufgehört haben, strukturellen ASCII-Müll an ein Modell mit einer Billion Parametern zu schicken. LLMs sind nicht absolut teuer, sondern pro Million Tokens, und die Zahl der Pipelines, in denen jemand rohes HTML in ein Kontextfenster schaufelt, ist ehrlich gesagt peinlich.
Markdown ist die Lingua Franca der KI-Trainingsdaten. Das ist eine Tatsache über die Welt, keine Meinung. In Markdown zu arbeiten richtet Ihre Eingaben an dem aus, wofür das Modell trainiert würde, und eine Klartext-Zwischenform gibt Ihnen auch eine Version, die Ihr Git-Verlauf sinnvoll diffen kann, was Sie in sechs Monaten schätzen werden, wenn Sie sich fragen, wie der Prompt im Q3 eigentlich aussah.
Ausprobieren
Öffnen Sie den HTML-zu-Markdown-Konverter, fügen Sie beliebiges HTML ein und sehen Sie zu, wie der Token-Count fällt. Alles läuft im Browser, das heißt Ihre Kundenentwürfe, gescrapten Quellen und internen Docs verlassen Ihre Maschine nie. Der Code ist im Network-Tab der DevTools inspizierbar; während der Konvertierung geht keine einzige Anfrage raus.
Wenn Sie das Markdown irgendwo visuell veröffentlichen wollen, liefert der Markdown-zu-Medium-Konverter veröffentlichungsreife Ausgabe für den Medium-Editor.
Verwandte Lektüre: Wie man Markdown auf Medium veröffentlicht, ohne die Formatierung zu verlieren · Warum Client-Side-Tools privater sind als die Cloud · AVIF in 2026: der komplette Leitfaden
Verwandte Tools: JSON-Formatter · CSV zu JSON · Wortzähler · Text-Diff-Checker · Bildkompressor