Un ami qui dirige une agence de contenu m'a dit autour d'un café la semaine dernière : "on a essayé tous les détecteurs d'IA du marché et c'est que du vent." Je lui ai dit que je pensais pouvoir en construire un meilleur. Il a ri. C'est de bonne guerre.
Le AI Content Detector que j'ai construit fonctionne entièrement dans le navigateur. Pas d'uploads, pas d'abonnements, pas d'API cloud qui te facture au scan. Il utilisé dix métriques statistiques et dix-huit signaux au niveau de la phrase pour déterminer si un texte a été écrit par un humain ou généré par ChatGPT, Claude, Gemini, ou n'importe quel LLM que les gens utilisent cette semaine. Je veux expliquer comment ça marche vraiment, parce que la plupart des pages marketing de "détecteurs d'IA" sont délibérément vagues sur leur méthodologie.
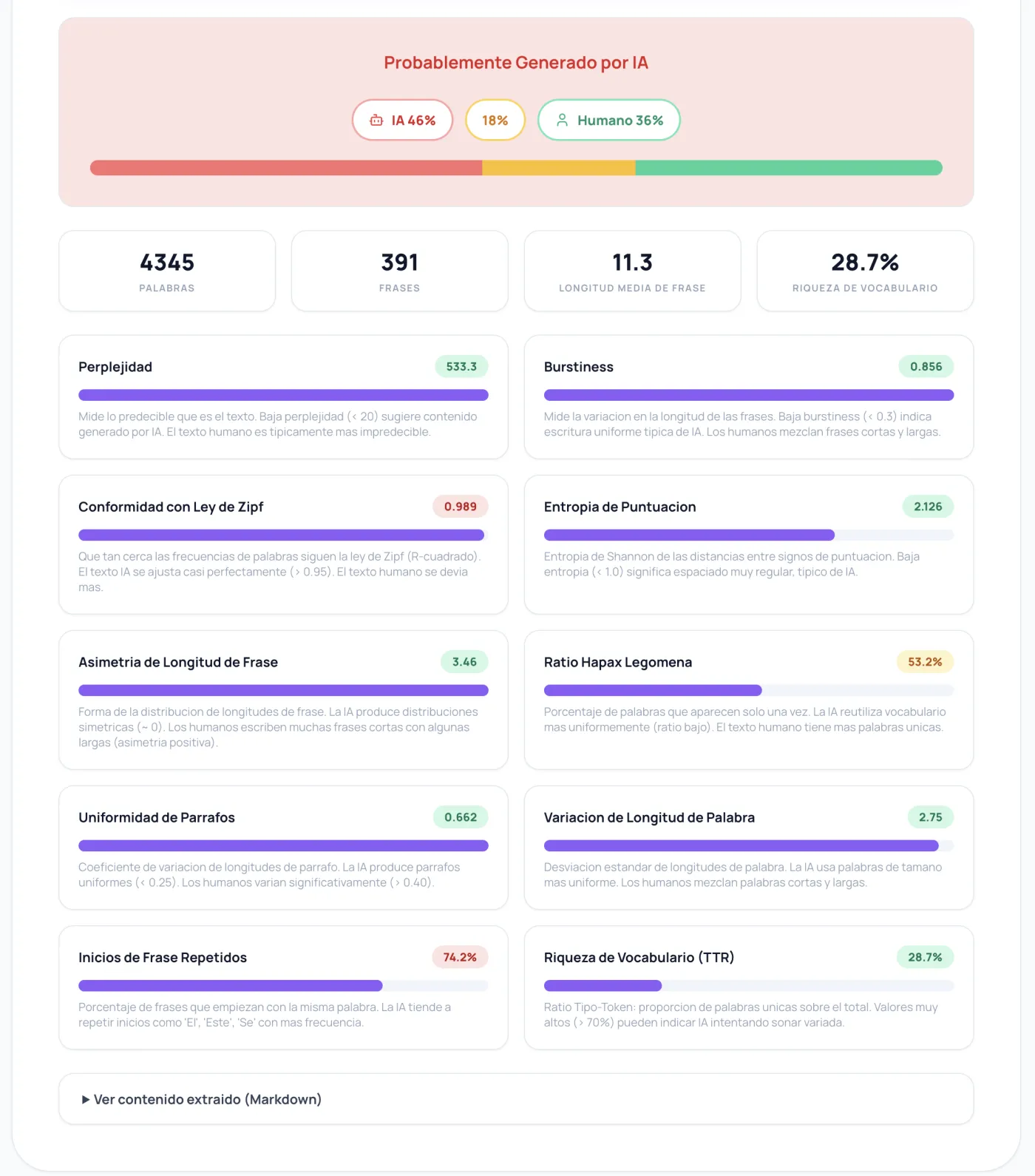
Pourquoi la perplexité et la burstiness seules ne suffisent pas
Tous les articles sur la détection d'IA mentionnent la perplexité et la burstiness. Ce sont de vraies métriques, elles mesurent quelque chose d'utile, mais voici la vérité inconfortable que j'ai découverte après des semaines de tests : les modèles d'IA modernes comme GPT-4 et Claude produisent du texte avec une haute perplexité et une haute burstiness. Ils ont été entraînés pour avoir l'air humain. Se fier uniquement à ces deux métriques, c'est comme essayer d'attraper un cambrioleur en vérifiant s'il a utilisé la porte d'entrée.
La perplexité mesure à quel point les séquences de mots sont prévisibles (basse = robotique, haute = créatif). La burstiness mesure la variation de longueur des phrases (basse = uniforme, haute = variée). L'IA old-school de 2022 échouait aux deux tests de façon spectaculaire. Mais les modèles de 2025-2026 ? Ils les passent haut la main.
Alors, qu'est-ce qui marche vraiment ?
Les dix métriques qui comptent
Après avoir fait des benchmarks contre des articles que je savais générés par IA et des articles que je savais humains (j'ai utilisé un ensemble de dix vraies URLs allant du MIT Technology Review à des blogs SEO génériques sur le café), j'ai trouvé que ces signaux, combinés, produisent des résultats réellement utiles :
La conformité à la loi de Zipf s'est avérée être la métrique individuelle la plus fiable. Tout langage naturel suit la loi de Zipf : le deuxième mot le plus courant apparaît deux fois moins souvent que le premier, le troisième trois fois moins souvent, et ainsi de suite. Le texte humain dévie de cette courbe parce qu'on se fixe sur certains mots, on part en digressions, on fait des choix de mots bizarres. Le texte IA suit la loi de Zipf presque parfaitement parce qu'il échantillonne des distributions de probabilité qui produisent intrinsèquement des sorties zipfiennes. Je calcule le R-carré de log-rang vs log-fréquence et tout ce qui dépasse 0.96 est suspect.
Les débuts de phrase répétés, c'est d'une simplicité gênante mais ça attrape énormément d'IA. Comptez quel pourcentage de phrases commencent par le même mot. L'IA adore commencer ses phrases par "The", "This", "It", "In". J'ai vu des articles IA où 70%+ des phrases commençaient par un de quatre mots. Les humains sont plus bordéliques sans même essayer.
L'entropie de ponctuation mesure l'entropie de Shannon des distances entre les signes de ponctuation. L'IA place les virgules et les points à des intervalles remarquablement réguliers. Les humains sont chaotiques ; parfois on écrit trois phrases courtes d'affilée, puis une longue avec cinq virgules, puis un fragment.
L'asymétrie de longueur de phrase capture la forme de la distribution des longueurs de phrase. L'IA produit des distributions quasi symétriques (courbe en cloche). Les humains écrivent avec une asymétrie positive : beaucoup de phrases courtes, quelques moyennes, et l'occasionnelle phrase monstre qui nous échappe complètement.
Le ratio d'hapax legomena compte quel pourcentage de mots n'apparaissent qu'une seule fois dans le texte. Le texte humain contient plus de mots uniques parce qu'on utilisé un vocabulaire spécifique et contextuel. L'IA réutilise les mots plus uniformément dans tout le texte.
L'uniformité des paragraphes est le coefficient de variation des longueurs de paragraphe. L'IA produit des paragraphes remarquablement uniformes. Les humains écrivent un paragraphe de deux phrases suivi d'un de douze sans y penser.
Les quatre métriques restantes (perplexité, burstiness, richesse du vocabulaire, écart-type de longueur de mot) contribuent avec des poids plus faibles. Elles aident à départager mais ne sont plus les vedettes de l'équipe.
Le vrai truc : la notation multiplicative des signaux
C'est là que ça devient intéressant. Les signaux individuels se chevauchent entre texte IA et humain tout le temps. Un humain peut utiliser des tirets (signal IA) ou avoir des paragraphes uniformes (signal IA). Mais les humains n'ont presque jamais des tirets ET des paragraphes uniformes ET des mots de transition ET pas de contractions ET une structure formulaire ET des débuts répétés, le tout dans la même phrase.
Le texte IA a des clusters de signaux co-occurrents. Quand trois signaux IA ou plus apparaissent dans la même phrase, le score ne s'additionne pas simplement ; il se multiplie. Une phrase avec deux signaux IA score normalement. Trois signaux ? Score multiplié par 1.5x. Quatre ou plus ? Multiplié par 2x. Cette approche multiplicative capture quelque chose que la notation linéaire rate : la différence entre "ressemble parfois à de l'IA" et "c'est manifestement un pattern."
Le classificateur au niveau de la phrase traque dix-huit signaux séparés par phrase : uniformité de longueur, usage de tirets, mots de transition, phrases de remplissage ("il est important de noter", "joue un rôle crucial"), vocabulaire surutilisé ("leverage", "comprehensive", "facilitate"), patterns gras-puis-explication, accroches type "Here's what/why/how", densité de noms propres, contractions, parenthèses, questions, langage informel, voix passive, répétition de début, fins avec deux-points, points-virgules, listes numérotées et patterns de conclusion.
Mode URL et extraction de contenu
Vous pouvez coller du texte directement ou entrer une URL. En mode URL, l'outil récupère le HTML, élimine la navigation, les barres latérales, les pieds de page, les images, les scripts et tous les éléments non textuels, puis convertit le contenu restant en Markdown avec Turndown. Vous pouvez dérouler le contenu extrait sous les résultats pour vérifier ce que l'outil a réellement analysé. Certains sites chargent le contenu via JavaScript (rendu côté client), que le fetcher ne peut pas capturer ; pour ceux-là, l'onglet texte marche mieux.
La récupération d'URL essaie d'abord votre navigateur (pas de serveur impliqué). Si CORS bloque, un proxy Edge léger prend le relais avec une limite de cinq requêtes par minute.
Là où ça pèche
Je ne vais pas prétendre que c'est parfait.
La plus grande faiblesse : du texte IA bien écrit qui a été légèrement édité par un humain. Si quelqu'un génère un brouillon avec ChatGPT puis réécrit un tiers des phrases, ajoute une anecdote personnelle et supprimé les mots de transition, notre détecteur (et tous les autres détecteurs) aura du mal. C'est une limitation fondamentale des approches statistiques.
La deuxième faiblesse : certains textes humains sont genuinement formulaires. Les communiqués de presse corporate, les documents juridiques, les abstracts académiques. Ceux-ci déclenchent des signaux IA parce qu'ils manquent du désordre que les détecteurs statistiques recherchent. Ce n'est pas exactement un bug, mais ça produit des faux positifs sur une catégorie de texte que personne n'appellerait de l'écriture créative.
La troisième faiblesse : les textes très courts. En dessous d'environ 200 mots, il n'y a pas assez de signal statistique pour qu'aucune des métriques soit fiable.
Comparé à GPTZero, Originality.ai, Copyleaks
Ces services utilisent des classificateurs ML entraînés (des réseaux de neurones entraînés sur des millions d'échantillons étiquetés IA/humain). En théorie, ils devraient être plus précis que des heuristiques statistiques comme la mienne. En pratique, l'écart est plus petit qu'on ne le pense, surtout sur les textes longs. Leurs modèles ont été entraînés sur des sorties IA spécifiques et peinent quand de nouveaux modèles apparaissent ; les patterns statistiques sont plus agnostiques au modèle.
Le vrai avantage de l'approche navigateur : votre texte ne quitte jamais votre appareil, c'est gratuit et c'est instantané. Si vous scannez une centaine d'articles de blog pour un audit de contenu, ça compte plus que quelques points de pourcentage de précision.
Essayez-le
Le AI Content Detector est sur Kitmul. Gratuit, sans inscription, fonctionne dans votre navigateur. Testez-le sur quelque chose que vous savez généré par IA, testez-le sur quelque chose que vous avez écrit vous-même, et voyez si les résultats correspondent à votre intuition.
Prochaine étape : un scanner de sitemap qui explorera chaque URL de votre sitemap.xml et produira un rapport indiquant quelles pages semblent générées par IA. Celui-là devrait être amusant.
Outils connexes : Text Readability Scorer · Sentiment Analyzer · Keyword Extractor · Text Tone Analyzer · Syllable Counter
Références :