
Quemé 176 millones de tokens de Anthropic el miércoles pasado. Puedes ver el pico en la captura un poco más abajo. La mayor parte era código productivo con Claude Code, pero al rastrear la anomalía encontré un job por lotes metiendo HTML crudo a Claude Sonnet 4.5 para resumirlo. Los prompts funcionaban; el presupuesto de tokens, no. Cuando por fin miré lo que mi scraper le estaba dando al modelo, alrededor del 70% de cada petición era sopa de <div class="css-1f2x">. El artículo real, la parte que me importaba, era quizá un 25% del payload.
El arreglo fue un cambio de cinco líneas: convertir HTML a Markdown antes de mandarlo al modelo. El conteo de tokens cayó un 60%. Misma calidad de salida. Ojalá lo hubiera aprendido antes.
Este post va de por qué funciona, cuándo importa y varios problemas colindantes que ese mismo truco resuelve.
Por qué el HTML es un desastre de tokens
Los LLM tokenizan texto. Anthropic expone un endpoint de conteo de tokens en la Claude API, y el tiktoken open-source de OpenAI da una vista similar: la prosa inglesa parte en aproximadamente un token cada 3-4 caracteres. Pero el HTML no es prosa. Es un árbol anidado de etiquetas, nombres de clase, estilos inline, atributos SVG y bloques JSON volcados en atributos data-* por cada framework moderno.
Puedes comprobarlo tú mismo. Pega un párrafo de texto plano en el contador de tokens de Anthropic y apunta el número. Luego envuélvelo en un típico <div class="prose dark:prose-invert max-w-none sm:px-6 lg:px-8"> generado por React y vuelve a contar. Solo ese wrapper, esa única línea, puede costarte 30-40 tokens. Multiplícalo por una página scrapeada con 500 divs anidados y ves por dónde se va el dinero.
El Markdown, en cambió, es casi invisible para un tokenizador. Un encabezado son dos caracteres: # . Una negrita cuatro: **x**. Un enlace es [texto](url), y el modelo lo maneja de forma nativa porque su corpus de entrenamiento está saturado de Markdown de GitHub, Stack Overflow y Reddit.
Hice una prueba rápida con el artículo de Wikipedia sobre el protocolo HTTP:
- HTML crudo (guardado desde el navegador): ~48.000 tokens
- HTML limpio (estilo boilerpipe): ~22.000 tokens
- Conversión a Markdown: ~8.900 tokens
Es una reducción del 81% frente al crudo, y del 60% frente incluso a un payload HTML ya limpió. En un modelo que cobra por token de entrada esto no es una micro-optimización. Es la diferencia entre un producto viable y un chargeback de Stripe.
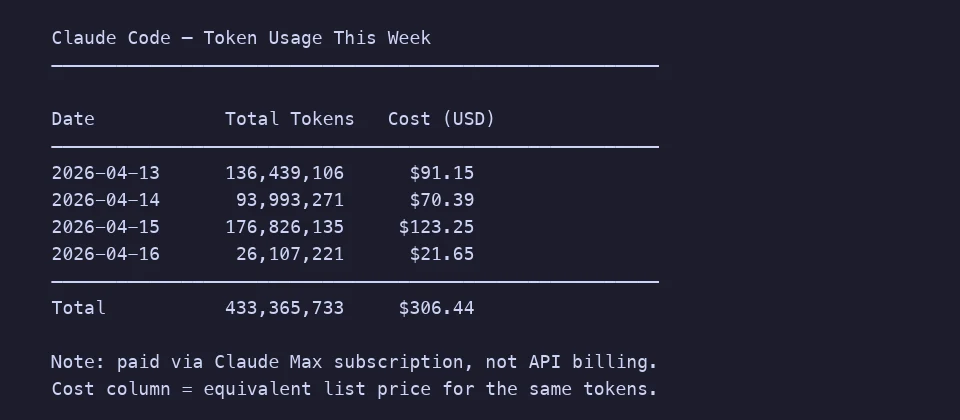
Aquí tienes una semana de mi uso real de Claude Code como referencia. Cuatro días, 433 millones de tokens, alrededor de 306 $ a precios de lista (estoy en una suscripción Max, pero el equivalente en pagó por uso hace legible la escala). La mayoría es código productivo. Imagina qué te compraría recortar un 10-15% no enviando ruido estructural a lo largo de un año.
El caso del pipeline RAG
Si estás construyendo retrieval-augmented generation, esto importa aún más. Un sistema RAG típicamente:
- Crawlea o scrapea documentos fuente
- Los trocea en chunks que caben en la ventana de contexto del modelo de embeddings
- Convierte cada chunk en vector y lo guarda en una base vectorial
- En tiempo de consulta, recupera los top-K chunks y los inyecta en el prompt del LLM
Cada uno de esos pasos empeora con HTML por el medio. Los embeddings se desvían porque el modelo intenta codificar nombres de clase CSS juntó al significado real. El troceado queda desigual; o partes a media etiqueta y confundes al retriever, o usas un split por caracteres y partes una frase por la mitad. La latencia de recuperación crece porque el espacio vectorial está contaminado con ruido estructural.
Convertir a Markdown antes del chunking resuelve las tres cosas. La excelente documentación de LangChain lo recomienda en voz baja: usa MarkdownHeaderTextSplitter o RecursiveCharacterTextSplitter con separadores Markdown. Sus propios ejemplos pasan por HTML a Markdown primero. Hay un motivo.
Cuando no puedes correr Python en un servidor
Mucha de la literatura sobre HTML-a-Markdown asume que tienes un backend con BeautifulSoup y markdownify instalados. Genial si estás construyendo un pipeline. Doloroso si eres redactor, periodista archivando fuentes, o programador haciendo una migración puntual a las 11 de la noche.
Construí Kitmul HTML to Markdown porque seguía buscando justo ese flujo y odiando todas las opciones. La herramienta corre en el navegador. Pegas el HTML fuente, obtienes el Markdown. Nada se sube, nada llama a casa. La conversión ocurre con JavaScript en tu máquina, lo que significa que puedes pegar exports de wikis internas, borradores legales o contenido de cliente sin pensártelo.
Si nunca has inspeccionado el HTML detrás de una página, abre cualquier artículo, clic derecho, "Ver código fuente", copia el cuerpo del artículo. Mételo en la herramienta. Lo que sale es algo que puedes poner en un prompt, pegar en Notion o commitear a Git.
Siete sitios donde esto sí sirve
Me costó un tiempo darme cuenta de cuántos de mis problemas se reducen a "tengo HTML y ojalá fuera Markdown". Una lista parcial:
Alimentar un artículo largo a un LLM. Las mayores ganancias aparecen cuando resumes, extraes entidades o haces preguntas sobre una página web larga. Markdown elimina el cromo y deja la sustancia. El coste del prompt baja, y paradójicamente el modelo lo hace mejor sobre entrada más limpia porque deja de distraerse con CSS.
Migrar un blog de WordPress o Ghost. Si te mudas a un generador estático como Astro, Hugo o Jekyll, cada post necesita ser un archivo .md. Exporta el XML de WordPress, pasa cada bloque <content:encoded> por el conversor, deja el resultado en content/posts/. Yo moví 84 posts así en una tarde.
Archivar investigación. Mantengo una wiki personal de artículos de ingeniería que consulto a menudo. Las páginas desaparecen de la web todo el tiempo; la vida media de una página web es inferior a 100 días. Los snapshots en Markdown se leen en milisegundos, hacen diff limpió en Git y sobreviven al vaivén de formatos de una manera que los screenshots o PDFs no.
Preparar datos de entrenamiento o ejemplos few-shot. Si curas ejemplos para fine-tuning o in-context learning, los quieres consistentes. Markdown es la forma consistente. Cada fuente scrapeada acaba con la misma forma, la misma jerarquía de encabezados y sin wrappers <span> raros que confundan tu plantilla.
Limpiar contenido salido de editores visuales. Herramientas como Notion, Medium o CKEditor exportan HTML técnicamente correcto pero lleno de anidamientos <p><strong><em><u> que nadie quiere. Un viaje por Markdown colapsa eso a la forma semántica mínima, y encima te queda una fuente portable y diffeable.
Escribir documentación a partir de referencias de API scrapeadas. Lo he hecho con tres SDKs. Coges el HTML renderizado de los docs del proveedor (muchos están en MkDocs o Docusaurus sin fuente Markdown disponible), lo conviertes y tienes un punto de partida editable y commiteable. Es más rápido que copiar-pegar cada bloque de código a mano.
Reducir costes en la API de Claude y la API de Gemini. Todo modelo frontera cobra tokens de entrada. El prompt caching de Anthropic ayuda, pero cachear 48K de HTML sigue siendo peor que cachear 9K de Markdown. Los caches también expulsan entradas. El token más barato es el que nunca envías.
Qué se pierde en la conversión
Sé honesto con los trade-offs. Algunas cosas no sobreviven:
- Estilos visuales. Colores, tipografías, CSS personalizado. Si el layout visual es el contenido (infografías, landings), Markdown es el objetivo equivocado.
- Componentes interactivos. Formularios embebidos, iframes, widgets JavaScript. Se convierten en enlaces planos o desaparecen.
- Layouts exactos de tabla. Las tablas Markdown manejan filas y columnas, pero celdas fusionadas, colspans y tablas anidadas se simplifican o rompen. Para tablas con muchos datos, exportar a CSV suele ser mejor; nuestra herramienta CSV a JSON cubre el caso colindante.
- Posicionamiento de imágenes. Las imágenes en Markdown son inline, de arriba abajo. Los floats no traducen.
Para el 90% de las páginas con contenido textual nada de esto importa. Para el 10% restante probablemente quieras el HTML de todos modos.
Un flujo concreto
Está es la rutina con la que me he quedado para trabajó con LLMs:
- Scrapea la página con
fetcho Playwright y coge el innerHTML del cuerpo del artículo, no el documento entero. Un buen selector CSS te hace la mitad de la limpieza. - Si es algo puntual, pega en el conversor HTML a Markdown. Si es un lote, usa una librería como
turndown(en GitHub) omarkdownifyen Python. - Quita boilerplate (banners de cookies, "posts relacionados", CTAs de newsletter). Markdown lo hace fácil: el ruido tiende a agruparse arriba y abajo.
- Mándalo al modelo. Para documentos largos, trocea por encabezados Markdown, no por conteo de caracteres.
- Cachea la versión Markdown localmente. La próxima vez no deberías repetir el paso 1.
Todo esto suele tardar más en describirse que en ejecutarse.
El punto de fondo
La conversión de formatos suena aburrida. Lo es, hasta que ves tu factura de API encogerse un 60% porque dejaste de mandar ruido estructural ASCII a un modelo de un billón de parámetros. Los LLMs son caros no en absoluto sino por millón de tokens, y el número de pipelines donde alguien está mandando HTML crudo a una ventana de contexto da, sinceramente, vergüenza ajena.
Markdown es la lingua franca de los datos de entrenamiento de IA. Es un hecho sobre el mundo, no una opinión. Trabajar en Markdown alinea tus entradas con lo que el modelo fue entrenado para manejar, y una forma intermedia en texto plano también te da una versión que tu historial de Git puede diffear de verdad, algo que agradecerás en seis meses cuando intentes recordar qué pinta tenía el prompt en el Q3.
Pruébalo
Abre el conversor HTML a Markdown, pega cualquier HTML y ve cómo cae el conteo de tokens. Todo corre en tu navegador, lo que significa que tus borradores de cliente, fuentes scrapeadas y docs internos no salen de tu máquina. El código es inspeccionable desde la pestaña Network de DevTools; no hay ni una petición saliente durante la conversión.
Si quieres publicar el Markdown en algún sitio visual, el conversor Markdown a Medium produce salida lista para el editor de Medium.
Lectura relacionada: Cómo publicar Markdown en Medium sin perder formato · Por qué las herramientas client-side son más privadas que la nube · AVIF en 2026: la guía completa
Herramientas relacionadas: Formateador JSON · CSV a JSON · Contador de palabras · Comparador de texto · Compresor de imágenes