
El otro día tenía un bug en producción. Algo se renderizaba mal en la interfaz y no conseguía localizar de donde venía. Le pasé la URL a Claude, abrió Chrome, inspeccionó el HTML en el navegador, cruzó lo que vio en el DOM con mi código fuente y encontró la línea exacta donde estaba el error. No el archivo; la línea. Navegó entre el output renderizado y el codebase, conectó lo que estaba roto en pantalla con el componente que lo producía y me apuntó directamente al fix.
Ese momento se me quedó grabado. No porque la IA me ahorró tiempo (eso lo hace a diario), sino por lo que reveló sobre la naturaleza de la respuesta. El modelo no sabía donde estaba el bug. Lo infirió. Observó el HTML renderizado, estimó que partes del código podían producir ese output y presentó el origen más probable. Esa inferencia probabilística cruzando dos representaciones distintas del mismo sistema; navegador y codebase; fue más efectiva de lo que mi depuración determinista habría sido.
Estamos viviendo algo más grande de lo que la mayoría percibe. El salto del determinismo al probabilismo no es una mejora técnica. Es un cambio en cómo se genera el conocimiento.
El primer cambio de paradigma: de lo analógico a lo digital

La transición de lo analógico a lo digital fue la transformación tecnológica definitoria del siglo XX. Convirtió señales continuas en datos discretos. De repente podías copiar información sin degradación. Transmitirla globalmente. Almacenarla de forma eficiente. Internet, los sistemas distribuidos, el software moderno; todo desciende de esa única idea: las señales continuas pueden representarse como secuencias de unos y ceros.
Pero hubo algo que esa transición dejó intacto: el proceso de creación en sí mismo.
El software digital es determinista. Dada la misma entrada, produce la misma salida. Cada línea de código, cada sistema, cada producto tenía que ser explícitamente diseñado, escrito y mantenido por un humano. El ordenador ejecutaba instrucciones. No generaba nada que no se le hubiera dicho que generará. Un formateador de SQL formatea SQL porque alguien escribió reglas exactas de cómo se debe formatear. Un generador de contraseñas produce cadenas aleatorias porque alguien implementó algoritmos CSPRNG que definen con precisión cómo se produce la aleatoriedad.
Los sistemas deterministas son predecibles, testeables y fiables. También son fundamentalmente limitados: solo pueden hacer lo que alguien ya ha imaginado y programado.
El segundo cambio de paradigma: del determinismo al probabilismo
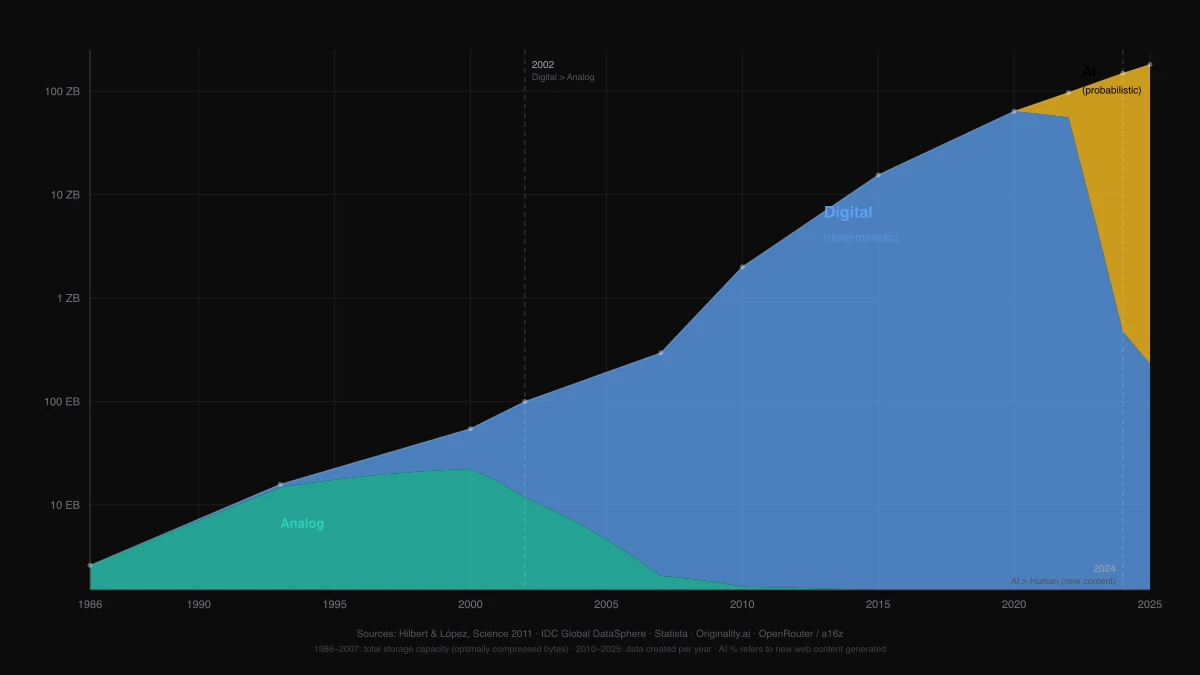
Con los modelos de lenguaje y el deep learning, entramos en una nueva fase. Sistemas que no ejecutan instrucciones rígidas sino que generan resultados basados en distribuciones de probabilidad.
La diferencia es estructural:
- Ya no describimos exactamente qué hacer. Entrenamos modelos para que aprendan cómo hacerlo.
- No generamos información manualmente. La inferimos.
- Producimos respuestas, contenido y decisiones que nunca fueron programadas explícitamente.
Piensa en lo que hace un detector de contenido IA. No tiene una lista de "frases escritas por IA" contra la que comparar. Calcula propiedades estadísticas del texto; conformidad con la ley de Zipf, entropía de puntuación, distribuciones de longitud de oraciones; y estima una probabilidad de que el texto haya sido generado por una máquina. El propio detector es un sistema probabilístico analizando la salida de otro sistema probabilístico. Esa frase habría sido absurda hace diez años.
O piensa en la generación automática de subtítulos. El modelo Whisper de OpenAI no sigue reglas if-then para transcribir el habla. Procesa espectrogramas de audio y predice la secuencia de tokens más probable que corresponde a lo que se dijo. Acierta la mayor parte del tiempo. No todo el tiempo. Ese "la mayor parte del tiempo" es la característica definitoria de los sistemas probabilísticos.
Este cambio tiene un impacto directo en el recurso más valioso que existe: el tiempo. La IA reduce el esfuerzo necesario para crear, analizar y predecir en órdenes de magnitud.
Generación de conocimiento sin precedentes
La diferencia clave es que los sistemas probabilísticos pueden trabajar con lo desconocido. A partir de patrones aprendidos, pueden:
- Generar texto, imágenes o código que nunca han existido.
- Predecir resultados futuros a partir de datos incompletos.
- Encontrar relaciones que nunca fueron definidas explícitamente.
Esto rompe una limitación histórica: ya no necesitamos escribir cada caso posible. El sistema puede generalizar.
Piensa en el forecaster de Monte Carlo. La gestión de proyectos clásica pedía a los equipos que estimaran cuánto tardarían las tareas y luego sumaba los números. La simulación de Monte Carlo hace algo más inteligente: ejecuta miles de escenarios usando datos históricos y te da una distribución de probabilidad de fechas de entrega. "Hay un 85% de probabilidad de que termines para el 15 de marzo" es más útil que "la estimación es el 10 de marzo." Pero aquí hay un matiz que importa: Monte Carlo es código determinista. Fórmulas estadísticas ejecutadas con precisión perfecta. No hay inferencia; hay simulación. Es pensamiento probabilístico implementado sobre infraestructura determinista. Hoy un LLM podría hacer la misma predicción sin necesidad de ese código; le pasas los datos históricos del equipo y te da una estimación razonable. Pero "razonable" no es "fiable". Mientras los modelos no alcancen precisiones del 99.99%, las simulaciones estadísticas escritas a mano siguen siendo la opción segura. Monte Carlo es exactamente el tipo de herramienta que marca la transición: pensamiento probabilístico que todavía necesita muletas deterministas.
El mismo principio aplica en todas partes. Un eliminador de fondo ejecutando una red neuronal en el navegador no tiene reglas sobre qué cuenta como "fondo". Ha aprendido distribuciones de probabilidad sobre millones de imágenes segmentadas y aplica esas distribuciones a tu foto. Un generador de prompts no almacena prompts preescritos; estructura patrones de lenguaje natural que probabilísticamente producen mejores respuestas del modelo.
Incluso las herramientas que parecen puramente deterministas están siendo transformadas. La conversión de HTML a Markdown es determinista; el mismo HTML siempre produce el mismo Markdown. Pero la razón por la que esa herramienta existe es probabilística: la gente necesita Markdown limpio porque alimentar HTML crudo a un LLM desperdicia el 60-80% de los tokens en ruido estructural. Una herramienta determinista al servicio de un ecosistema probabilístico.
Las limitaciones actuales: por qué aún no es perfecto
A pesar del potencial, la IA actual tiene restricciones reales:
Tiempo de inferencia. Generar respuestas implica procesar cantidades enormes de tokens. Una cadena de razonamiento compleja en un modelo frontera puede tardar 30-60 segundos. Es rápido comparado con el análisis humano, pero lento comparado con una consulta a base de datos. La brecha de latencia entre "calcular un hash" (nanosegundos) y "razonar sobre un bug" (segundos) es de seis órdenes de magnitud.
Errores probabilísticos. Los modelos no "saben" en el sentido clásico. Estiman. En abril de 2026, GPT-5.5, Claude Opus 4.7 y Gemini 3.1 Pro puntúan entre el 89% y el 92% en MMLU-Pro; el benchmark más exigente que sustituye al MMLU original. Cada generación sube unos puntos, pero los números siguen siendo estadísticos. Un animador de recorrido de grafos siempre encontrará el camino más corto porque BFS es determinista. Un LLM al que le pidas encontrar el camino más corto probablemente lo encontrará, pero podría alucinar una arista que no existe.
Infraestructura clásica. Estos modelos corren sobre hardware diseñado para computación determinista: CPUs, GPUs, TPUs. La NVIDIA H100 está optimizada para multiplicación masiva de matrices, que es lo que los transformers necesitan, pero la arquitectura subyacente sigue siendo clásica. Estamos resolviendo problemas probabilísticos con máquinas deterministas.
La trayectoria: acercándose al 100% de precisión
La tendencia es clara. Cada nueva generación de modelos mejora en benchmarks, reduce tasas de error y expande la capacidad de generalización. Las familias de Google Gemini, Claude de Anthropic y GPT de OpenAI convergen hacia niveles de precisión que hacen que la distinción entre "correcto" y "altamente probable" sea prácticamente irrelevante para muchas tareas.
Cuando los modelos alcancen un 99.99% de precisión en tareas cognitivas rutinarias:
- La confianza en los sistemas de IA igualará o superará la confianza en el juicio humano.
- La mayoría de tareas intelectuales que siguen patrones aprendibles serán delegadas completamente.
- El coste marginal de generar conocimiento se acercará a cero.
Aún no estamos ahí. Pero la distancia se reduce con cada nueva versión.
El cuello de botella: computación clásica vs. cuántica

Hay una idea que merece reflexión: estamos resolviendo un problema fundamentalmente probabilístico con herramientas deterministas.
Las GPUs y TPUs paralelizan cálculos masivos, pero operan bajo principios clásicos. Esto genera restricciones reales:
- Alto consumo energético. Entrenar modelos de clase GPT-5 requirió decenas de miles de GPUs NVIDIA H100 durante meses, con costes que superan los 100 millones de dólares.
- Escalado costoso. Más parámetros significa más hardware, más refrigeración, más electricidad.
- Latencias significativas en modelos grandes.
La alternativa teórica es la computación cuántica.
Empresas como IBM, Google y D-Wave Systems están explorando QPUs (Unidades de Procesamiento Cuántico) que trabajan directamente con estados probabilísticos mediante superposición y entrelazamiento.
En teoría, esto permitiría:
- Resolver ciertos cálculos exponencialmente más rápido.
- Modelar sistemas probabilísticos de forma nativa en lugar de simularlos sobre hardware determinista.
- Reducir drásticamente el coste computacional de la inferencia de IA.
Si quieres ver cómo son realmente los circuitos cuánticos, el Simulador de Circuitos Cuánticos te permite construir y ejecutar circuitos en el navegador. Dos líneas de código crean un estado de Bell; un par máximamente entrelazado de qubits donde la medición de uno determina instantáneamente el otro. Ese tipo de comportamiento probabilístico nativo es exactamente lo que le falta a la infraestructura actual de IA.
El problema difícil: corrección de errores cuánticos
La computación cuántica aún no está lista para este rol. El principal obstáculo es la Corrección de Errores Cuánticos.
Los sistemas cuánticos son extremadamente sensibles al ruido y las interferencias. Cada interacción con el entorno puede colapsar la superposición de un qubit, corrompiendo la computación. Los procesadores cuánticos actuales tienen tasas de error que los hacen imprácticos para la computación sostenida y fiable que requiere la inferencia de IA.
Para que una QPU sea viable a escala, tienen que ocurrir tres cosas:
- Las tasas de error deben caer dramáticamente. Los qubits físicos actuales tienen tasas de error del 0.1-1%. La computación cuántica útil necesita tasas por debajo del 0.0001%.
- El número de qubits estables debe escalar. La hoja de ruta actual de IBM apunta a 100.000 qubits para 2033. Es ambicioso, pero los desafíos de ingeniería en cada paso son enormes.
- Las arquitecturas tolerantes a fallos deben madurar. Los códigos de superficie y otros esquemas de corrección de errores funcionan en principio pero requieren miles de qubits físicos por qubit lógico. La sobrecarga aún es prohibitiva.
Lo que está en juego no es solo velocidad. Es energía.
Los centros de datos consumieron alrededor de 415 TWh en 2024; el 1.5% de la electricidad global. La IEA estima que superarán los 1.000 TWh en 2026, y la IA es el principal motor de ese crecimiento. Entrenar un modelo frontera consume la electricidad equivalente a miles de hogares durante un año. Cada consulta de inferencia gasta más de 33 Wh en prompts largos; diez veces lo que consume una búsqueda en Google. Y esto escala. Más modelos, más agentes, más robótica con IA integrada; cada capa añade demanda energética.
El día que la corrección de errores cuánticos se resuelva, esa ecuación cambia radicalmente. Las QPUs actuales consumen unos 25 kW, la mayor parte en refrigeración criogénica; no en computación. Pero la computación cuántica trabaja con el problema probabilístico de forma nativa en lugar de simularlo con trillones de multiplicaciones de matrices. Algoritmos de compresión cuántica ya demuestran reducciones del 84% en consumo energético en tareas específicas de IA. Y la corrección parcial de errores está permitiendo que modelos cuánticos mantengan alta precisión con miles de qubits en vez de millones.
Cuando la corrección de errores cuánticos madure, no solo tendremos IA más rápida. Tendremos IA que consume órdenes de magnitud menos energía por inferencia. Eso es lo que convierte la computación cuántica de una curiosidad de laboratorio en infraestructura viable para los miles de millones de agentes que el futuro necesita.
Hasta que eso ocurra, seguiremos ejecutando IA probabilística sobre hardware determinista. Lo cual, siendo honestos, funciona notablemente bien para lo fundamentalmente incompatibles que son los paradigmas.
Qué significa esto en la práctica
Esto no es filosofía abstracta. El paso del determinismo al probabilismo cambia cómo construyes, cómo trabajas y cómo piensas en las herramientas.
Un laboratorio de árboles de búsqueda binaria enseña algoritmos deterministas. Insertas un nodo, recorres el árbol, obtienes el mismo resultado cada vez. Ese tipo de certeza sigue siendo valioso. Las bases de datos siguen necesitando B-trees. El enrutamiento sigue necesitando Dijkstra. Los generadores de ruido azul siguen necesitando algoritmos de muestreo deterministas para producir puntos bien distribuidos.
Pero la capa por encima de esas primitivas deterministas es cada vez más probabilística. La consulta a base de datos es determinista; el agente de IA que decide qué consulta ejecutar es probabilístico. El algoritmo es determinista; el modelo que selecciona qué algoritmo encaja con el problema es probabilístico. El texto es determinista una vez escrito; el sistema que extrae texto de imágenes usando redes neuronales de OCR es probabilístico.
Estamos construyendo un stack donde los sistemas deterministas ejecutan y los sistemas probabilísticos deciden. Eso es nuevo. Y solo va a acelerarse.
El siguiente paso no es mejor IA; es un stack de computación compuesto
Lo que viene después no reemplaza un paradigma por otro. Los compone.
Piensa en cómo funciona ya la infraestructura moderna. Las CPUs ejecutan lógica determinista; transacciones de base de datos, verificaciones criptográficas, el kernel de tu sistema operativo. Las GPUs y TPUs resuelven problemas probabilísticos; entrenan modelos, ejecutan inferencia, procesan distribuciones sobre millones de parámetros. Cada capa hace lo que la otra no puede. Nadie sugiere reemplazar CPUs con GPUs. Se combinan.
Las QPUs completan la tercera capa. Resuelven una clase de problemas que el hardware clásico simula mal: optimización combinatoria, muestreo de distribuciones de alta dimensión, búsqueda en espacios exponenciales. La inferencia de IA no se hace más rápida; se hace viable a escalas que hoy son inabordables.
El stack queda así: lo determinista ejecuta y verifica. Lo probabilístico propone y genera. Lo cuántico optimiza lo que ninguno de los dos puede tocar.
Pero falta una pieza que casi nadie está discutiendo.
Modelos que hablan con máquinas que hablan con modelos
Hasta ahora pensamos en la IA como algo que recibe un prompt y devuelve texto. Eso es como pensar que internet es email. La siguiente capa es la comunicación entre modelos probabilísticos; y entre esos modelos y el hardware determinista que controlan.
Un modelo de lenguaje analiza datos de sensores y decide que necesita más información de una zona específica. Le comunica esa decisión a un modelo de visión que controla un dron. El dron se desplaza, recoge datos, los procesa con otro modelo especializado y devuelve los resultados al primero. Ningún humano intervino en el ciclo. Ningún humano decidió que esa zona era interesante. El sistema lo infirió.
Eso no es automatización. La automatización ejecuta lo que un humano diseñó. Esto es distinto: sistemas probabilísticos decidiendo qué datos recoger, cómo recogerlos y qué hacer con lo que encuentran. Robots con modelos de IA que eligen explorar fuentes de información que a nosotros no se nos habrían ocurrido.
Piensa en un dron marino con sensores químicos y un modelo entrenado en biodiversidad oceánica. No sigue una ruta preprogramada. Detecta una anomalía en la composición del agua, infiere que podría indicar una comunidad microbiana desconocida, ajusta su trayectoria y toma muestras. Encuentra algo que ningún biólogo marino habría buscado porque ninguno habría predicho que estaría ahí. Otro modelo analiza las muestras, identifica compuestos con potencial farmacéutico y le pide al dron que vuelva a la misma zona con sensores distintos.
Eso es conocimiento genuinamente nuevo. No extraído de datos existentes ni inferido de texto humano. Generado por un sistema que decidió ir a buscarlo.
Cuando la predicción tarda nanosegundos
Las limitaciones actuales son reales. La inferencia tarda segundos. La precisión ronda el 86-95% dependiendo del benchmark. Pero esas son las limitaciones de la primera generación de un paradigma que apenas empieza. La trayectoria apunta a modelos con 99.99% de precisión y tiempos de respuesta en nanosegundos.
Cuando eso ocurra, el mundo se reorganiza de formas que cuesta imaginar desde donde estamos ahora.
Un coche autónomo que tarda 30 milisegundos en decidir es un coche que frena tarde. Uno que decide en nanosegundos reacciona antes de que el obstáculo termine de aparecer. Una red de modelos médicos con 99.99% de precisión no asiste al médico; diagnostica con una fiabilidad que un humano no puede igualar. Una cadena de suministro donde cada nodo tiene un modelo predictivo que se comunica con los demás no necesita planificación trimestral; se reoptimiza en tiempo real, cada milisegundo.
Pero lo verdaderamente importante es lo que pasa cuando la inferencia probabilística se vuelve tan rápida y precisa que es funcionalmente indistinguible de la certeza determinista. La distinción entre "calcular" e "inferir" desaparece. Tu sistema operativo no necesita distinguir entre una operación aritmética y una predicción. El compilador no necesita saber si el resultado viene de lógica formal o de un modelo de 400B de parámetros. Todo es computación; parte basada en reglas, parte basada en distribuciones, parte optimizada cuánticamente. Integrada de forma invisible.
La IA deja de ser una herramienta que abres y se convierte en una capa de infraestructura que ni siquiera percibes. Como la electricidad. Como TCP/IP. Está en todas partes y no piensas en ella.
Conocimiento más allá de lo humano
Los robots con modelos de IA no solo automatizan lo que hacíamos. Perciben lo que no podemos.
Un sensor ultrasónico acoplado a un modelo de materiales detecta microfisuras en una turbina eólica que ninguna inspección visual encontraría. Un espectrómetro portátil con un modelo químico identifica contaminantes en concentraciones que los protocolos humanos no miden. Un array de hidrófonos con un modelo acústico clasifica especies marinas por patrones de sonido que ningún biólogo ha catalogado todavía.
Estos no son mejoras incrementales en eficiencia. Son fuentes de conocimiento nuevas. Datos que existían en el mundo físico pero que eran invisibles para nosotros porque no teníamos los sensores correctos acoplados a la inteligencia correcta para interpretarlos.
Y aquí es donde el ciclo se cierra. Esos robots no solo recogen datos; los modelos que llevan dentro deciden qué datos vale la pena recoger. Pero el ciclo va más allá. Una IA analizando anomalías de temperatura oceánica determina que la red de sensores existente es demasiado gruesa; necesita lecturas a profundidades y frecuencias que ningún instrumento actual cubre. Así que diseña la especificación de un nuevo sensor. Un robot de fabricación lo construye. Un robot de despliegue lo instala en una flota de drones submarinos. Esos drones recogen datos que ningún sistema anterior podía capturar, y esos datos entrenan un modelo mejor, que identifica la siguiente brecha en capacidad de medición, y el ciclo comienza de nuevo.
Ningún humano decidió qué medir. Ningún humano diseñó el sensor. Ningún humano eligió dónde desplegarlo. Toda la cadena; desde identificar una brecha de conocimiento hasta rellenarla con hardware físico nuevo; fue impulsada por inferencia probabilística.
Cuando millones de sistemas así operan simultáneamente, cada uno diseñando sensores para los demás, desplegando instrumentos que no existían un ciclo antes, y alimentando los resultados de vuelta a modelos compartidos, la humanidad tiene acceso a una capa de realidad que literalmente no podía percibir antes. No es una mejora en lo que ya sabíamos. Es acceso a lo que no sabíamos que no sabíamos.
El stack completo
Hace treinta años la pregunta era "¿sabes programar?". Hace diez era "¿sabes usar APIs?". Hoy es "¿sabes dirigir modelos?". Mañana será irrelevante; los modelos se dirigen entre ellos.
Lo determinista ejecuta y verifica. Lo probabilístico propone, genera y decide. Lo cuántico optimiza lo inabordable. Los sensores y los robots extienden todo esto al mundo físico. Y la comunicación entre modelos cierra el ciclo: sistemas que descubren qué no saben, deciden cómo averiguarlo y actúan para conseguirlo. Sin intervención humana. Sin que nadie les diga dónde mirar.
Si el salto de lo analógico a lo digital redefinió cómo almacenamos información, y el salto del determinismo al probabilismo está redefiniendo cómo generamos conocimiento, la integración completa; modelos, hardware, sensores, robots, computación cuántica; redefine los límites de lo que es posible percibir y comprender.
No estaremos usando mejores herramientas. Estaremos rodeados de una inteligencia que ve lo que no vemos, busca lo que no buscamos y encuentra lo que no sabíamos que existía.