
Neulich hatte ich einen Bug in Produktion. Irgendetwas wurde in der Oberflaeche falsch gerendert und ich konnte nicht herausfinden, woher es kam. Ich gab Claude die URL, es oeffnete Chrome, inspizierte das HTML im Browser, verglich das, was es im DOM sah, mit meinem Quellcode und fand die exakte Zeile, in der der Fehler lag. Nicht die Datei; die Zeile. Es navigierte zwischen dem gerenderten Output und der Codebase, ordnete das, was auf dem Bildschirm kaputt war, der Komponente zu, die es erzeugt hatte, und zeigte mir den Fix.
Dieser Moment blieb haengen. Nicht weil KI mir Zeit gespart hat (das tut sie taeglich), sondern wegen dem, was es ueber die Natur der Antwort offenbarte. Das Modell wusste nicht, wo der Bug war. Es hat ihn abgeleitet. Es beobachtete das gerenderte HTML, schaetzte, welche Teile des Codes diesen Output erzeugen koennten, und brachte den wahrscheinlichsten Ursprung ans Licht. Diese probabilistische Inferenz ueber zwei verschiedene Repraesentationen desselben Systems; Browser und Codebase; war effektiver als mein deterministisches Debugging gewesen waere.
Wir erleben gerade etwas Groesseres, als die meisten erkennen. Der Wechsel von deterministischem zu probabilistischem Computing ist nicht nur ein technisches Upgrade. Es ist ein Wandel in der Art, wie Wissen entsteht.
Der erste Paradigmenwechsel: von analog zu digital

Der Uebergang von analog zu digital war die praegendste technologische Transformation des spaeten 20. Jahrhunderts. Er wandelte kontinuierliche Signale in diskrete Daten um. Ploetzlich konnte man Information ohne Verschlechterung kopieren. Sie global uebertragen. Sie effizient speichern. Das Internet, verteilte Systeme, moderne Software; all das stammt von dieser einzigen Erkenntnis ab: Kontinuierliche Signale lassen sich als Folgen von Einsen und Nullen darstellen.
Aber es gab etwas, das diese Transition unberuehrt liess: den Prozess der Kreation selbst.
Digitale Software ist deterministisch. Bei gleicher Eingabe erzeugt sie die gleiche Ausgabe. Jede Codezeile, jedes System, jedes Produkt musste explizit entworfen, geschrieben und von einem Menschen gewartet werden. Der Computer fuehrte Anweisungen aus. Er generierte nichts, was man ihm nicht gesagt hatte zu generieren. Ein SQL-Formatierer formatiert SQL, weil jemand exakte Regeln geschrieben hat, wie SQL formatiert werden soll. Ein Passwort-Generator erzeugt zufaellige Zeichenketten, weil jemand CSPRNG-Algorithmen implementiert hat, die praezise definieren, wie Zufall erzeugt wird.
Deterministische Systeme sind vorhersagbar, testbar und zuverlaessig. Sie sind aber auch grundlegend begrenzt: Sie koennen nur das tun, was sich jemand bereits vorgestellt und programmiert hat.
Der zweite Paradigmenwechsel: vom Determinismus zum Probabilismus
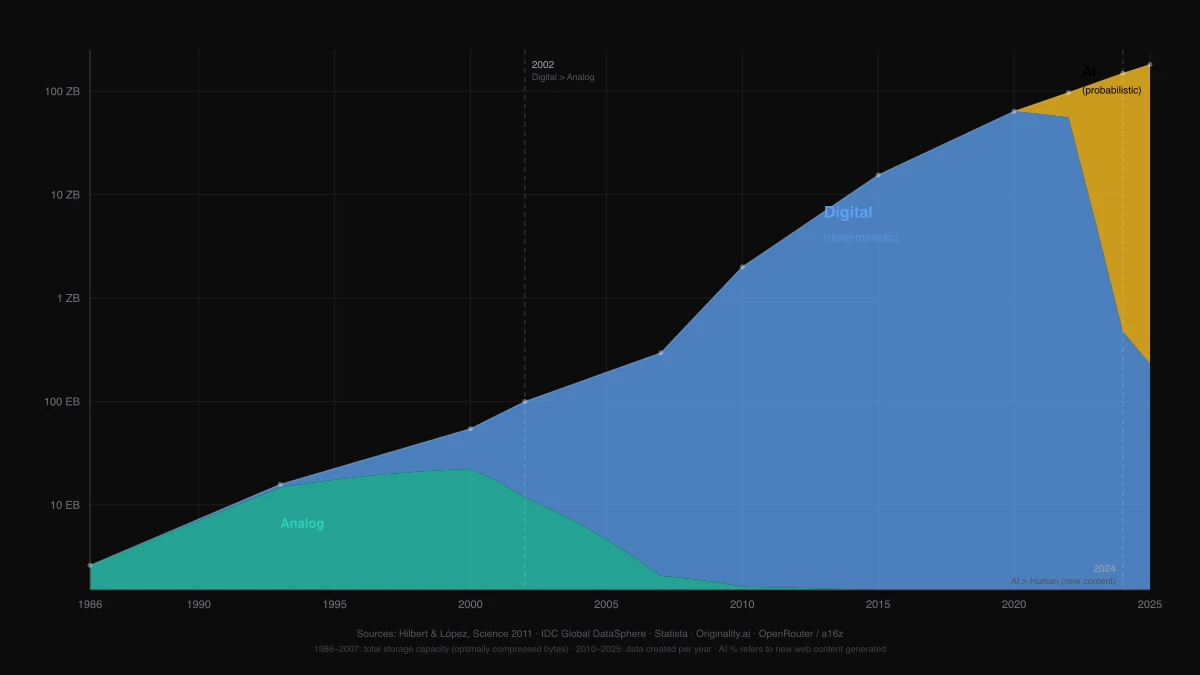
Mit grossen Sprachmodellen und Deep Learning sind wir in eine neue Phase eingetreten. Systeme, die keine starren Anweisungen ausfuehren, sondern Ergebnisse basierend auf Wahrscheinlichkeitsverteilungen generieren.
Der Unterschied ist strukturell:
- Wir beschreiben nicht mehr genau, was zu tun ist. Wir trainieren Modelle, um zu lernen, wie es geht.
- Wir generieren Information nicht mehr manuell. Wir leiten sie ab.
- Wir erzeugen Antworten, Inhalte und Entscheidungen, die nie explizit programmiert wurden.
Denken Sie daran, was ein KI-Inhaltsdetektor tut. Er hat keine Liste von "KI-geschriebenen Saetzen" zum Abgleich. Er berechnet statistische Eigenschaften des Textes; Konformitaet mit dem Zipfschen Gesetz, Interpunktions-Entropie, Satzlaengenverteilungen; und schaetzt eine Wahrscheinlichkeit, dass der Text maschinell erzeugt wurde. Der Detektor selbst ist ein probabilistisches System, das die Ausgabe eines anderen probabilistischen Systems analysiert. Dieser Satz waere vor zehn Jahren bedeutungslos gewesen.
Oder denken Sie an die automatische Untertitel-Generierung. OpenAIs Whisper-Modell folgt keinen if-then-Regeln, um Sprache zu transkribieren. Es verarbeitet Audio-Spektrogramme und sagt die wahrscheinlichste Token-Sequenz voraus, die dem Gesagten entspricht. Es liegt meistens richtig. Nicht immer. Dieses "meistens" ist das definierende Merkmal probabilistischer Systeme.
Dieser Wandel hat einen direkten Einfluss auf die wertvollste Ressource: Zeit. KI reduziert den Aufwand fuer Erstellung, Analyse und Vorhersage um Groessenordnungen.
Wissensgenerierung ohne Praezedenzfall
Der entscheidende Unterschied ist, dass probabilistische Systeme mit dem Unbekannten arbeiten koennen. Aus gelernten Mustern koennen sie:
- Text, Bilder oder Code generieren, die noch nie existiert haben.
- Zukuenftige Ergebnisse aus unvollstaendigen Daten vorhersagen.
- Beziehungen finden, die nie explizit definiert wurden.
Das durchbricht eine historische Beschraenkung: Wir muessen nicht mehr jeden moeglichen Fall schreiben. Das System kann generalisieren.
Nehmen Sie den Monte-Carlo-Forecaster. Klassisches Projektmanagement bat Teams, zu schaetzen, wie lange Aufgaben dauern, und addierte dann die Zahlen. Monte-Carlo-Simulation macht etwas Klügeres: Sie fuehrt Tausende von Szenarien mit historischen Daten durch und gibt Ihnen eine Wahrscheinlichkeitsverteilung der Liefertermine. "Es gibt eine 85%-ige Chance, dass Sie bis zum 15. Maerz fertig sind" ist nuetzlicher als "die Schaetzung ist der 10. Maerz." Aber es gibt eine wichtige Nuance: Monte Carlo ist deterministischer Code. Statistische Formeln, die mit perfekter Praezision ausgefuehrt werden. Es gibt keine Inferenz; es gibt Simulation. Es ist probabilistisches Denken, implementiert auf deterministischer Infrastruktur. Heute koennte ein LLM dieselbe Vorhersage ohne all diesen Code machen; Sie uebergeben die historischen Daten des Teams und es gibt eine vernuenftige Schaetzung. Aber "vernuenftig" ist nicht "zuverlaessig". Bis Modelle 99,99% Genauigkeit erreichen, bleiben handcodierte statistische Simulationen die sichere Wahl. Monte Carlo ist genau die Art von Werkzeug, das den Uebergang markiert: probabilistisches Denken, das noch deterministische Kruecken braucht.
Dasselbe Prinzip gilt ueberall. Ein Hintergrund-Entferner, der ein neuronales Netzwerk im Browser ausfuehrt, hat keine Regeln darueber, was als "Hintergrund" zaehlt. Er hat Wahrscheinlichkeitsverteilungen ueber Millionen segmentierter Bilder gelernt und wendet diese Verteilungen auf Ihr Foto an. Ein Prompt-Generator speichert keine vorgeschriebenen Prompts; er strukturiert natuerliche Sprachmuster, die probabilistisch bessere Modell-Outputs erzeugen.
Selbst Werkzeuge, die rein deterministisch erscheinen, werden umgestaltet. Die HTML-zu-Markdown-Konvertierung ist deterministisch; dasselbe HTML erzeugt immer dasselbe Markdown. Aber der Grund, warum dieses Werkzeug existiert, ist probabilistisch: Leute brauchen sauberes Markdown, weil das Fuettern von rohem HTML an ein LLM 60-80% der Token an strukturellem Rauschen verschwendet. Ein deterministisches Werkzeug im Dienst eines probabilistischen Oekosystems.
Die aktuellen Einschraenkungen: warum es noch nicht perfekt ist
Trotz des Potenzials hat die aktuelle KI echte Einschraenkungen:
Inferenzzeit. Antworten zu generieren bedeutet, enorme Mengen an Token zu verarbeiten. Eine komplexe Schlussfolgerungskette in einem Spitzenmodell kann 30-60 Sekunden dauern. Das ist schnell im Vergleich zur menschlichen Analyse, aber langsam im Vergleich zu einer Datenbankabfrage. Die Latenzluecke zwischen "einen Hash berechnen" (Nanosekunden) und "ueber einen Bug nachdenken" (Sekunden) betraegt sechs Groessenordnungen.
Probabilistische Fehler. Modelle "wissen" nicht im klassischen Sinne. Sie schaetzen. Im April 2026 erreichen GPT-5.5, Claude Opus 4.7 und Gemini 3.1 Pro zwischen 89% und 92% auf MMLU-Pro; dem anspruchsvolleren Benchmark, der das urspruengliche MMLU ersetzt. Jede Generation klettert ein paar Punkte, aber die Zahlen bleiben statistisch. Ein Graph-Traversierungs-Animator wird immer den kuerzesten Pfad finden, weil BFS deterministisch ist. Ein LLM, das gebeten wird, den kuerzesten Pfad zu finden, wird ihn wahrscheinlich finden, aber es koennte eine Kante halluzinieren, die nicht existiert.
Klassische Infrastruktur. Diese Modelle laufen auf Hardware, die fuer deterministische Berechnung entworfen wurde: CPUs, GPUs, TPUs. Die NVIDIA H100 ist fuer massive Matrixmultiplikation optimiert, was Transformer brauchen, aber die zugrunde liegende Architektur bleibt klassisch. Wir loesen probabilistische Probleme mit deterministischen Maschinen.
Die Trajektorie: Annaeherung an 100% Genauigkeit
Der Trend ist klar. Jede neue Modellgeneration verbessert sich in Benchmarks, reduziert Fehlerquoten und erweitert die Generalisierungsfaehigkeit. Die Gemini-Familie von Google, Anthropics Claude und OpenAIs GPT konvergieren auf Genauigkeitsniveaus, die die Unterscheidung zwischen "korrekt" und "hochwahrscheinlich" fuer viele Aufgaben praktisch bedeutungslos machen.
Wenn Modelle 99,99% Genauigkeit bei routinemaessigen kognitiven Aufgaben erreichen:
- Das Vertrauen in KI-Systeme wird dem menschlichen Urteilsvermoegen entsprechen oder es uebertreffen.
- Die meisten intellektuellen Aufgaben, die lernbaren Mustern folgen, werden vollstaendig delegiert.
- Die Grenzkosten der Wissensgenerierung naehern sich Null.
Wir sind noch nicht da. Aber der Abstand schrumpft mit jeder neuen Version.
Der Flaschenhals: klassisches Rechnen vs. Quantenrechnen

Hier ist eine Idee, die es wert ist, darueber nachzudenken: Wir loesen ein grundlegend probabilistisches Problem mit deterministischen Werkzeugen.
GPUs und TPUs parallelisieren massive Berechnungen, aber sie arbeiten nach klassischen Prinzipien. Das schafft echte Einschraenkungen:
- Hoher Energieverbrauch. Das Training von GPT-5-Klasse-Modellen erforderte Zehntausende NVIDIA H100 GPUs ueber Monate, bei Kosten von ueber 100 Millionen Dollar.
- Teure Skalierung. Mehr Parameter bedeutet mehr Hardware, mehr Kuehlung, mehr Strom.
- Signifikante Latenzen bei grossen Modellen.
Die theoretische Alternative ist Quantencomputing.
Unternehmen wie IBM, Google und D-Wave Systems erforschen QPUs (Quantum Processing Units), die direkt mit probabilistischen Zustaenden durch Superposition und Verschraenkung arbeiten.
Theoretisch wuerde das erlauben:
- Bestimmte Berechnungen exponentiell schneller zu loesen.
- Probabilistische Systeme nativ zu modellieren, anstatt sie auf deterministischer Hardware zu simulieren.
- Die Rechenkosten der KI-Inferenz drastisch zu senken.
Wenn Sie sehen wollen, wie Quantenschaltkreise tatsaechlich aussehen, koennen Sie mit dem Quantenschaltkreis-Simulator Schaltkreise im Browser bauen und ausfuehren. Zwei Codezeilen erzeugen einen Bell-Zustand; ein maximal verschraenktes Qubit-Paar, bei dem die Messung des einen sofort das andere bestimmt. Diese Art von nativem probabilistischem Verhalten ist genau das, was der aktuellen KI-Infrastruktur fehlt.
Das schwere Problem: Quanten-Fehlerkorrektur
Quantencomputing ist fuer diese Rolle noch nicht bereit. Das Haupthindernis ist die Quanten-Fehlerkorrektur.
Quantensysteme sind extrem empfindlich gegenueber Rauschen und Interferenzen. Jede Interaktion mit der Umgebung kann die Superposition eines Qubits kollabieren und die Berechnung korrumpieren. Aktuelle Quantenprozessoren haben Fehlerquoten, die sie fuer die nachhaltige, zuverlaessige Berechnung, die KI-Inferenz erfordert, unpraktisch machen.
Damit eine QPU im grossen Massstab tragfaehig ist, muessen drei Dinge passieren:
- Fehlerquoten muessen drastisch sinken. Aktuelle physische Qubits haben Fehlerquoten um 0,1-1%. Nuetzliches Quantenrechnen braucht Raten unter 0,0001%.
- Stabile Qubit-Zahlen muessen skalieren. IBMs aktuelle Roadmap zielt auf 100.000 Qubits bis 2033. Das ist ambitioniert, aber die Engineering-Herausforderungen bei jedem Schritt sind enorm.
- Fehlertolerante Architekturen muessen reifen. Oberflaechencodes und andere Fehlerkorrektur-Schemata funktionieren im Prinzip, erfordern aber Tausende physischer Qubits pro logischem Qubit. Der Overhead ist noch prohibitiv.
Es geht nicht nur um Geschwindigkeit. Es geht um Energie.
Rechenzentren verbrauchten rund 415 TWh im Jahr 2024; 1,5% des weltweiten Stroms. Die IEA schaetzt, dass sie bis 2026 ueber 1.000 TWh ueberschreiten, wobei KI der Hauptwachstumstreiber ist. Das Training eines Spitzenmodells verbraucht das Stromequivalent von Tausenden Haushalten fuer ein Jahr. Jede Inferenz-Anfrage verbraucht ueber 33 Wh bei langen Prompts; zehnmal so viel wie eine Google-Suche. Und das skaliert. Mehr Modelle, mehr Agenten, mehr Robotik mit eingebetteter KI; jede Schicht fuegt Energiebedarf hinzu.
Am Tag, an dem die Quanten-Fehlerkorrektur geloest wird, aendert sich diese Gleichung radikal. Aktuelle QPUs verbrauchen etwa 25 kW, das meiste davon fuer kryogene Kuehlung; nicht fuer Berechnung. Aber Quantencomputing arbeitet nativ mit dem probabilistischen Problem, anstatt es mit Billionen von Matrixmultiplikationen zu simulieren. Quanten-Kompressionsalgorithmen zeigen bereits 84% Energieeffizienzgewinne bei spezifischen KI-Aufgaben. Und partielle Fehlerkorrektur ermoeglicht es Quantenmodellen, hohe Genauigkeit mit Tausenden statt Millionen von Qubits aufrechtzuerhalten.
Wenn die Quanten-Fehlerkorrektur reift, werden wir nicht einfach schnellere KI haben. Wir werden KI haben, die Groessenordnungen weniger Energie pro Inferenz verbraucht. Das ist es, was Quantencomputing von einer Laborkuriositaet in tragfaehige Infrastruktur fuer die Milliarden von Agenten verwandelt, die die Zukunft erfordert.
Bis dahin werden wir weiterhin probabilistische KI auf deterministischer Hardware ausfuehren. Was, ehrlich gesagt, bemerkenswert gut funktioniert, wenn man bedenkt, wie grundlegend inkompatibel die Paradigmen sind.
Was das praktisch bedeutet
Das ist keine abstrakte Philosophie. Der Wechsel vom Determinismus zum Probabilismus aendert, wie man baut, wie man arbeitet und wie man ueber Werkzeuge nachdenkt.
Ein Binaersuchbaum-Labor lehrt deterministische Algorithmen. Einen Knoten einfuegen, den Baum durchlaufen, jedes Mal das gleiche Ergebnis erhalten. Diese Art von Gewissheit ist immer noch wertvoll. Datenbanken brauchen immer noch B-Trees. Routing braucht immer noch Dijkstra. Blue-Noise-Generatoren brauchen immer noch deterministische Sampling-Algorithmen, um gut verteilte zufaellige Punkte zu erzeugen.
Aber die Schicht ueber diesen deterministischen Primitiven wird zunehmend probabilistisch. Die Datenbankabfrage ist deterministisch; der KI-Agent, der entscheidet, welche Abfrage ausgefuehrt wird, ist probabilistisch. Der Algorithmus ist deterministisch; das Modell, das auswaehlt, welcher Algorithmus zum Problem passt, ist probabilistisch. Der Text ist deterministisch, sobald er geschrieben ist; das System, das Text aus Bildern extrahiert mittels OCR-neuronaler Netze, ist probabilistisch.
Wir bauen einen Stack, in dem deterministische Systeme ausfuehren und probabilistische Systeme entscheiden. Das ist neu. Und es wird sich nur beschleunigen.
Der naechste Schritt ist nicht bessere KI; es ist ein zusammensetzbarer Compute-Stack
Was als Naechstes kommt, ersetzt nicht ein Paradigma durch ein anderes. Es komponiert sie.
Denken Sie daran, wie moderne Infrastruktur bereits funktioniert. CPUs fuehren deterministische Logik aus; Datenbanktransaktionen, kryptografische Verifikation, der Kernel Ihres Betriebssystems. GPUs und TPUs loesen probabilistische Probleme; sie trainieren Modelle, fuehren Inferenz durch, verarbeiten Verteilungen ueber Millionen von Parametern. Jede Schicht tut, was die andere nicht kann. Niemand schlaegt vor, CPUs durch GPUs zu ersetzen. Man kombiniert sie.
QPUs vervollstaendigen die dritte Schicht. Sie loesen eine Klasse von Problemen, die klassische Hardware schlecht simuliert: kombinatorische Optimierung, hochdimensionales Verteilungs-Sampling, Suche ueber exponentielle Raeume. KI-Inferenz wird nicht nur schneller; sie wird bei Skalen tragfaehig, die derzeit unlösbar sind.
Der Stack sieht so aus: Deterministische Systeme fuehren aus und verifizieren. Probabilistische Systeme schlagen vor und generieren. Quantensysteme optimieren, was keines der beiden anderen beruehren kann.
Aber es gibt ein Element, ueber das fast niemand spricht.
Modelle, die mit Maschinen sprechen, die mit Modellen sprechen
Bisher denken wir an KI als etwas, das einen Prompt empfaengt und Text zurueckgibt. Das ist, als wuerde man denken, das Internet sei E-Mail. Die naechste Schicht ist die Kommunikation zwischen probabilistischen Modellen; und zwischen diesen Modellen und der deterministischen Hardware, die sie steuern.
Ein Sprachmodell analysiert Sensordaten und entscheidet, dass es mehr Information aus einem bestimmten Bereich braucht. Es kommuniziert diese Entscheidung an ein Vision-Modell, das eine Drohne steuert. Die Drohne bewegt sich, sammelt Daten, verarbeitet sie durch ein anderes spezialisiertes Modell und gibt die Ergebnisse an das erste zurueck. Kein Mensch hat in den Zyklus eingegriffen. Kein Mensch hat entschieden, dass dieser Bereich interessant war. Das System hat es abgeleitet.
Das ist keine Automatisierung. Automatisierung fuehrt aus, was ein Mensch entworfen hat. Dies ist anders: Probabilistische Systeme, die entscheiden, welche Daten zu sammeln sind, wie sie zu sammeln sind und was mit dem zu tun ist, was sie finden. Roboter mit KI-Modellen, die sich entscheiden, Informationsquellen zu erkunden, an die wir nicht gedacht haetten.
Stellen Sie sich eine Meeresdrohne mit chemischen Sensoren und einem Modell vor, das auf ozeanische Biodiversitaet trainiert ist. Sie folgt keiner vorprogrammierten Route. Sie erkennt eine Anomalie in der Wasserzusammensetzung, leitet ab, dass sie auf eine unbekannte mikrobielle Gemeinschaft hindeuten koennte, passt ihre Trajektorie an und nimmt Proben. Sie findet etwas, wonach kein Meeresbiologe gesucht haette, weil keiner vorhergesagt haette, dass es dort waere. Ein anderes Modell analysiert die Proben, identifiziert Verbindungen mit pharmazeutischem Potenzial und bittet die Drohne, mit anderen Sensoren in dieselbe Zone zurueckzukehren.
Das ist genuein neues Wissen. Nicht aus bestehenden Daten extrahiert oder aus menschlichem Text abgeleitet. Generiert von einem System, das entschieden hat, danach zu suchen.
Wenn Vorhersage Nanosekunden dauert
Die aktuellen Einschraenkungen sind real. Inferenz dauert Sekunden. Die Genauigkeit liegt je nach Benchmark bei 86-95%. Aber das sind die Einschraenkungen der ersten Generation eines Paradigmas, das gerade erst beginnt. Die Trajektorie zeigt auf Modelle mit 99,99% Genauigkeit und Antwortzeiten im Nanosekundenbereich.
Wenn das passiert, reorganisiert sich die Welt auf eine Weise, die von unserem jetzigen Standpunkt schwer vorstellbar ist.
Ein selbstfahrendes Auto, das 30 Millisekunden zum Entscheiden braucht, ist ein Auto, das spaet bremst. Eines, das in Nanosekunden entscheidet, reagiert, bevor das Hindernis fertig erscheint. Ein Netzwerk medizinischer Modelle mit 99,99% Genauigkeit assistiert dem Arzt nicht; es diagnostiziert mit einer Zuverlaessigkeit, die kein Mensch erreichen kann. Eine Lieferkette, in der jeder Knoten ein Vorhersagemodell hat, das mit allen anderen kommuniziert, braucht keine Quartalsplanung; sie reoptimiert sich in Echtzeit, jede Millisekunde.
Aber das wirklich Wichtige ist, was passiert, wenn probabilistische Inferenz so schnell und genau wird, dass sie funktional nicht von deterministischer Gewissheit zu unterscheiden ist. Die Unterscheidung zwischen "Berechnen" und "Ableiten" verschwindet. Ihr Betriebssystem muss nicht zwischen einer arithmetischen Operation und einer Vorhersage unterscheiden. Der Compiler muss nicht wissen, ob das Ergebnis aus formaler Logik oder einem 400-Milliarden-Parameter-Modell kommt. Es ist alles Berechnung; teils regelbasiert, teils verteilungsbasiert, teils quantenoptimiert. Nahtlos integriert.
KI hoert auf, ein Werkzeug zu sein, das man oeffnet, und wird zu einer Infrastrukturschicht, die man gar nicht mehr bemerkt. Wie Strom. Wie TCP/IP. Es ist ueberall und man denkt nicht darueber nach.
Wissen jenseits des Menschlichen
Roboter mit KI-Modellen automatisieren nicht nur, was wir frueher taten. Sie nehmen wahr, was wir nicht koennen.
Ein Ultraschallsensor, gekoppelt mit einem Materialmodell, erkennt Mikrorisse in einer Windturbine, die keine visuelle Inspektion finden wuerde. Ein tragbares Spektrometer mit einem Chemiemodell identifiziert Schadstoffe in Konzentrationen, die menschliche Protokolle nicht messen. Ein Hydrophon-Array mit einem akustischen Modell klassifiziert Meeresarten nach Klangmustern, die kein Biologe bisher katalogisiert hat.
Das sind keine inkrementellen Effizienzverbesserungen. Es sind neue Wissensquellen. Daten, die in der physischen Welt existierten, aber fuer uns unsichtbar waren, weil wir nicht die richtigen Sensoren hatten, gekoppelt mit der richtigen Intelligenz, um sie zu interpretieren.
Und hier schliesst sich der Kreislauf. Diese Roboter sammeln nicht nur Daten; die Modelle in ihnen entscheiden, welche Daten es wert sind, gesammelt zu werden. Aber der Zyklus geht weiter. Eine KI, die Anomalien der Ozeantemperatur analysiert, stellt fest, dass das bestehende Sensornetz zu grob ist; sie braucht Messwerte in Tiefen und Frequenzen, die kein aktuelles Instrument abdeckt. Also entwirft sie die Spezifikation eines neuen Sensors. Ein Fertigungsroboter baut ihn. Ein Einsatzroboter installiert ihn auf einer Flotte von Unterwasserdrohnen. Diese Drohnen sammeln Daten, die kein vorheriges System erfassen konnte, und diese Daten trainieren ein besseres Modell, das die naechste Luecke in der Messfaehigkeit identifiziert, und der Zyklus beginnt von vorn.
Kein Mensch hat entschieden, was gemessen werden soll. Kein Mensch hat den Sensor entworfen. Kein Mensch hat gewaehlt, wo er eingesetzt wird. Die gesamte Kette; von der Identifizierung einer Wissensluecke bis zu ihrer Schliessung mit neuer physischer Hardware; wurde durch probabilistische Inferenz angetrieben.
Wenn Millionen solcher Systeme gleichzeitig arbeiten, jedes Sensoren fuer die anderen entwirft, Instrumente einsetzt, die einen Zyklus zuvor noch nicht existierten, und die Ergebnisse in gemeinsame Modelle zurueckfuettert, erhaelt die Menschheit Zugang zu einer Schicht der Realitaet, die sie buchstaeblich vorher nicht wahrnehmen konnte. Es ist keine Verbesserung dessen, was wir schon wussten. Es ist Zugang zu dem, von dem wir nicht wussten, dass wir es nicht wussten.
Der vollstaendige Stack
Vor dreissig Jahren war die Frage "Kannst du programmieren?". Vor zehn Jahren war es "Kannst du APIs nutzen?". Heute ist es "Kannst du Modelle lenken?". Morgen wird es irrelevant sein; Modelle werden sich gegenseitig lenken.
Deterministische Systeme fuehren aus und verifizieren. Probabilistische Systeme schlagen vor, generieren und entscheiden. Quantensysteme optimieren das Unlösbare. Sensoren und Roboter erweitern all das in die physische Welt. Und die Kommunikation zwischen Modellen schliesst die Schleife: Systeme, die entdecken, was sie nicht wissen, entscheiden, wie sie es herausfinden, und handeln, um es zu bekommen. Ohne menschliches Eingreifen. Ohne dass ihnen jemand sagt, wo sie suchen sollen.
Wenn der Uebergang von analog zu digital neu definierte, wie wir Information speichern, und der Uebergang vom Determinismus zum Probabilismus neu definiert, wie wir Wissen generieren, definiert die vollstaendige Integration; Modelle, Hardware, Sensoren, Roboter, Quantencomputing; die Grenzen dessen neu, was moeglich ist zu erfassen und zu verstehen.
Wir werden nicht bessere Werkzeuge nutzen. Wir werden von einer Intelligenz umgeben sein, die sieht, was wir nicht sehen, sucht, was wir nicht suchen, und findet, was wir nicht wussten, dass es existiert.