
Hay tres formas de convertir una respuesta JSON en interfaces TypeScript. Puedes escribirlas a mano, puedes preguntarle a un LLM, o puedes pasar el JSON por un convertidor determinista. He usado las tres. Dos de ellas tienen modos de falló en los que la mayoría no piensa hasta que sube un bug a producción.
El enfoque manual: lento y preciso hasta que deja de serlo
Escribir interfaces a mano funciona cuando tienes tres campos. Deja de funcionar alrededor del campo quince. Un objeto charge de Stripe tiene más de 40 propiedades. La respuesta de un pull request de GitHub supera los 100 campos una vez que cuentas los objetos anidados. Nadie los tipa a mano sin cometer errores.
El modo de falló es sutil. Abres la documentación de la API, empiezas a escribir, y para el campo veinte ya estas leyendo por encima. Era merged_at un string o un Date? Es labels un array de objetos o de strings? Adivinas, continuas, y el compilador de TypeScript confia en lo que escribiste. El sistema de tipos solo detecta errores si los tipos son correctos de entrada.
La documentación de TypeScript lo dice claro: any desactiva la verificación de tipos para ese valor. Pero una interfaz incorrecta es discutiblemente peor que any, porque te da falsa confianza. Tu IDE autocompleta campos que no existen. Tu código compila. El crash ocurre en runtime.
El enfoque LLM: rápido y probabilístico
Pegar un blob JSON en ChatGPT o Claude y pedir interfaces TypeScript es tentador. Es rápido. Maneja el anidamiento. Incluso nombra las interfaces de manera razonable la mayor parte del tiempo.
El problema es que los LLMs son probabilísticos. Dale el mismo JSON al mismo modelo dos veces y podrias obtener salidas diferentes. A veces agrega ? a campos que no son opcionales. A veces inventa un tipo union que no coincide con los datos. A veces decide que id debería ser string cuando el valor es claramente 1. He visto modelos producir Date para strings de timestamp ISO; técnicamente aspiracional, pero incorrecto si no estas parseando el string a un objeto Date primero.
Estos no son bugs del modelo. Es la naturaleza de la herramienta. Un LLM genera texto plausible basado en patrones. No parsea tu JSON como lo hace un sistema de tipos. Lo lee, aproxima cuales deberían ser los tipos, y escribe algo que parece correcto. La mayoría de las veces lo es. Pero "correcto la mayoría de las veces" y "deterministicamente correcto" son cosas diferentes cuando tus definiciones de tipos protegen el comportamiento en runtime.
También está el ángulo de privacidad. Pegar una respuesta API de producción en un LLM de terceros significa enviar tus datos al servidor de otro. Si esa respuesta contiene PII de usuarios, endpoints internos, o tokens de autenticación que se filtraron en el payload, acabas de compartirlos con un servicio externo. Para proyectos personales, a nadie le importa. Para codebases de producción con requisitos de compliance, esa es una conversacion con tu equipo de seguridad que no quieres tener.
El enfoque determinista: misma entrada, misma salida, siempre
Un convertidor determinista de JSON a TypeScript no adivina. Parsea. El algoritmo recorre el árbol JSON, inspecciona el tipo JavaScript de cada valor, y lo mapea al tipo TypeScript correspondiente. No hay aleatoriedad, no hay parámetro de temperatura, no hay modelo que pueda comportarse diferente un jueves.
Las reglas son mecánicas:
"hello"es siemprestring. No a vecesstring, no ocasionalmente"hello"como tipo literal.42es siemprenumber. Noint, nofloat, nonumber | string.[1, 2, 3]es siemprenumber[]. NoArray<number>, nonumber[] | undefined.{"a": 1}siempre genera una interfaz nombrada separada cona: number.nulles siemprenull. Noundefined, no omitido.
Mismo JSON de entrada, mismo TypeScript de salida. Ejecutalo cien veces y obtienes cien resultados identicos. Esa es la propiedad que quieres de una herramienta que genera definiciones de tipos en las que tu compilador confiara.
Lo que el algoritmo realmente hace
Bajo el capo, el convertidor hace un descenso recursivo por tu estructura JSON. Por cada valor que encuentra, llama a inferType(), que devuelve el string del tipo TypeScript. Los objetos producen nuevas entradas de interfaz en un Map. Los arrays inspeccionan sus elementos y producen un tipo uniforme (string[]) o un tipo union ((string | number)[]). Los arrays vacios se convierten en unknown[] porque no hay elemento del que inferir.
Los nombres de propiedades se convierten a PascalCase para los nombres de interfaces. Las claves que no son identificadores JavaScript válidos (guiones, espacios, digitos iniciales) se entrecomillan automáticamente. La salida puede alternarse entré declaraciones interface y type.
Un ejemplo concreto. Este JSON:
{
"id": 1,
"name": "Aral Roca",
"email": "aral@example.com",
"active": true,
"roles": ["admin", "editor"],
"profile": {
"bio": "Full-stack developer",
"avatar": "https://example.com/avatar.png",
"social": {
"github": "aralroca",
"twitter": "aralroca"
}
},
"posts": [
{
"id": 101,
"title": "Understanding TypeScript Interfaces",
"published": true,
"tags": ["typescript", "tutorial"]
}
],
"createdAt": "2026-04-27T10:00:00Z"
}
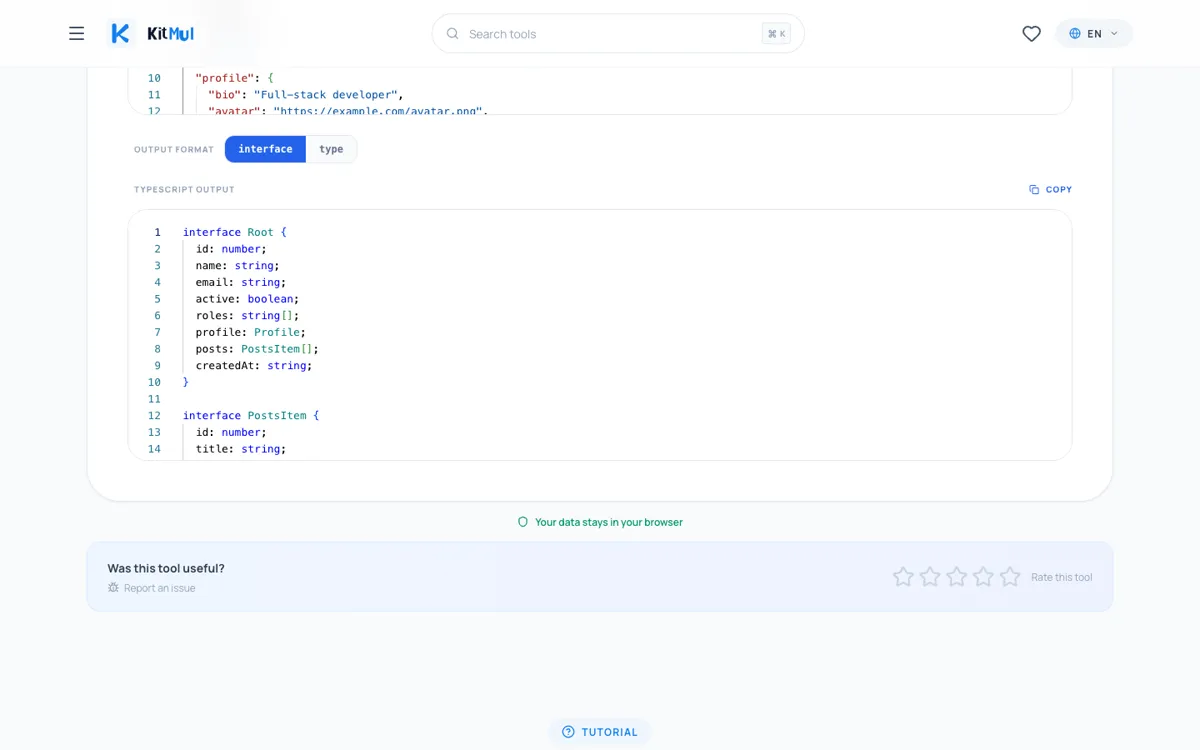
Produce exactamente esto:
interface Root {
id: number;
name: string;
email: string;
active: boolean;
roles: string[];
profile: Profile;
posts: PostsItem[];
createdAt: string;
}
interface Profile {
bio: string;
avatar: string;
social: Social;
}
interface Social {
github: string;
twitter: string;
}
interface PostsItem {
id: number;
title: string;
published: boolean;
tags: string[];
}
Cuatro interfaces. Cada campo correctamente tipado. Cada objeto anidado extraído en su propia interfaz nombrada. Sin aleatoriedad involucrada.
Interface vs. type: cuando el toggle importa
El convertidor ofrece salida tanto interface como type. La eleccion no es cosmetica.
Las interfaces soportan declaration merging; si dos interfaces comparten el mismo nombre en el mismo scope, TypeScript fusiona sus propiedades. Los types no. Para autores de bibliotecas que quieren que los consumidores extiendan tipos, las interfaces son mejor opción.
Los types manejan unions, intersecciones y mapped types de forma mas natural. Si necesitas type Result = Success | Error o componer shapes con &, la salida type te ahorra un pasó.
Para tipar respuestas API, rara vez importa. Elige lo que las reglas de linting de tu equipo impongan y sigue adelante.
Donde la inferencia determinista aún necesita revisión humana
El convertidor infiere tipos de valores, no de schemas. Eso es una feature; funciona con cualquier JSON sin requerir una spec OpenAPI ni JSON Schema. Pero significa que hay bordes donde querras ajustar:
Campos opcionales. El convertidor solo ve la muestra que proporcionas. Si un campo a veces está ausente de la respuesta, agrega ? manualmente.
Enums de string. "status": "active" se convierte en string, no en "active" | "inactive" | "suspended". Estrechalo tu.
Strings de fecha. Timestamps ISO 8601 como "2026-04-27T10:00:00Z" son string para el convertidor. Si los parseas con date-fns o dayjs, querras cambiarlos a Date en tus tipos finales.
Wrappers de paginación. Una respuesta como { data: [...], meta: { page: 1, total: 100 } } genera una interfaz Root con ambos. Renombrala a PaginatedResponse<T> y extrae Meta como generico.
Estos ajustes toman segundos. El punto es que el convertidor determinista te da una línea base correcta; las partes que necesitan juicio humano son las mismas que una máquina genuinamente no puede inferir de una sola muestra. Un LLM también las erraria; la diferencia es que el LLM podría además equivocarse en las partes fáciles.
Privacidad como feature, no como eslogan de marketing
El convertidor corre enteramente del lado del cliente. El JSON nunca sale de tu navegador. Sin llamadas al servidor, sin analitica sobre tu input, sin cuenta.
Este no es un beneficio abstracto. Muchos equipos tienen politicas de seguridad que prohiben subir código fuente o respuestas API a servicios de terceros. Eso descarta la mayoría de herramientas online. Descarta pegar respuestas de producción en chatbots LLM. Un convertidor del lado del cliente que procesa todo en una función JavaScript en tu máquina tiene cero superficie de compliance.
Abre la pestaña de red de tu navegador mientras lo usas. No veras nada enviado.
Un flujo de trabajó práctico
1. Obtener una respuesta real. Usa curl, Postman o la pestaña de red de tu navegador para capturar una respuesta API real.
2. Pegar y convertir. Abre el convertidor JSON a TypeScript, pega el JSON, copia la salida.
3. Renombrar y refinar. Cambia Root a UserResponse. Agrega ? donde sea necesario. Estrecha unions de strings.
4. Co-localizar con tu cliente API. Yo pongo los tipos en un types.ts juntó al archivo que hace la llamada fetch o axios.
5. Agregar validación en runtime. Usa Zod o Valibot para validar que la API realmente envía lo que tus tipos describen. El convertidor te da estructura; una biblioteca de esquemas te da garantías en runtime.
Todo toma menos de un minuto por endpoint.
Mas alla de respuestas API
El convertidor maneja cualquier JSON válido:
- Archivos de configuración. Pega
tsconfig.jsonopackage.jsonpara carga de configuración type-safe. - Exports de base de datos. Un documento MongoDB o fila PostgreSQL como JSON se convierte en los tipos de tu capa ORM.
- Fixtures de test. Si escribes tests con Jest o Vitest, convertir archivos fixture asegura que tus mocks coincidan con las formas de producción.
- Contenido CMS. Respuestas de CMS headless de Strapi, Sanity o Contentful son profundamente anidadas. Tipalas una vez; deja que el compilador detecte bugs en tus templates.
Para formatear JSON antes de convertir, el Formateador JSON maneja pretty-printing y validación. Para la dirección opuesta; limpiar HTML en algo que un LLM pueda procesar eficientemente; está el convertidor HTML a Markdown.
La matriz de trade-offs
| Manual | LLM | Determinista | |
|---|---|---|---|
| Velocidad | Lenta | Rápida | Rápida |
| Corrección | Depende de ti | Mayormente correcta | Siempre correcta para la muestra |
| Consistencia | Variable | No determinista | Identica cada vez |
| Privacidad | N/A | Datos enviados al servidor | Solo del lado del cliente |
| Campos opcionales | Tu decides | A veces adivina | Tu decides |
| Estrechamiento de strings | Tu decides | A veces adivina | Tu decides |
El convertidor determinista maneja la parte mecánica; mapear valores a tipos; perfectamente. Las partes que no puede manejar (opcionalidad, enums de string, parsing de fechas) son las mismas partes que los otros enfoques tampoco manejan de forma fiable. La diferencia es que no introduce nuevos errores en las partes que si puede manejar.
La conclusión
La seguridad de tipos no es un espectro. Tus tipos son correctos o no lo son. Tipar manualmente es lento y propenso a errores a escala. Tipar con LLM es rápido pero probabilístico. La conversión determinista es rápida y correcta; dentro de los límites de lo que cualquier herramienta puede inferir de una sola muestra JSON.
Usa el convertidor JSON a TypeScript para el trabajó mecánico. Gasta tu juicio en campos opcionales, unions de strings y nombres de interfaces; las decisiones que requieren contexto que ninguna herramienta tiene.
Sin registró. Sin subida. Misma entrada, misma salida. Parte de las Utilidades de Desarrollo y Programación en Kitmul.
Foto de Florian Olivo en Unsplash.