
Desplegamos una funcionalidad un martes. Para el jueves, la API estaba dando timeouts. El panel de monitorización mostraba la latencia p99 escalando de 80ms a 14 segundos en 48 horas. Nada había cambiado excepto el número de usuarios.
El culpable eran tres líneas de código que parecían completamente razonables durante la revisión:
const results = users.map(user => {
const match = permissions.find(p => p.userId === user.id);
return { ...user, role: match?.role ?? 'viewer' };
});
Limpio. Legible. Estilo funcional. También O(n * m), que en nuestro caso era O(n^2) porque usuarios y permisos crecían al mismo ritmo. Con 200 usuarios, 40.000 comparaciones. Con 2.000 usuarios, 4.000.000. Con 20.000 usuarios, 400.000.000. La solución fue una sola línea; construir un Map primero:
const permMap = new Map(permissions.map(p => [p.userId, p.role]));
const results = users.map(user => ({
...user,
role: permMap.get(user.id) ?? 'viewer',
}));
O(n + m) en lugar de O(n * m). Problema resuelto. Pero la verdadera pregunta es: ¿por qué nadie lo detectó?
La trampa del O(n^2) se esconde a plena vista
La complejidad cuadrática es la clase de rendimiento más peligrosa en software en producción. No porque sea la más lenta; O(2^n) y O(n!) son mucho peores. Sino porque parece correcta. Pasa la revisión de código. Funciona en desarrollo. Incluso funciona en staging si tu conjunto de datos de prueba es lo suficientemente pequeño. Luego llega a producción con volúmenes de datos reales y todo se desmorona.
El patrón es casi siempre el mismo: una operación de búsqueda anidada dentro de una iteración. Array.prototype.find(), Array.prototype.includes(), Array.prototype.indexOf(); todas son operaciones O(n). Ponlas dentro de un bucle y tienes O(n^2). Ponlas dentro de dos bucles anidados y tienes O(n^3). Los expresivos métodos de arrays de JavaScript hacen que esto sea especialmente fácil de pasar por alto, porque el código se lee como si fuera lenguaje natural en vez de parecer bucles for anidados.
Aquí van cinco patrones reales que he visto romper sistemas en producción.
Patrón 1: El inocente .includes() dentro de .filter()
// Looks clean, but O(n * m)
const activeUsers = allUsers.filter(u => activeIds.includes(u.id));
Si activeIds es un array con 10.000 entradas y allUsers tiene 50.000 entradas, estás haciendo 500.000.000 de comparaciones. Convierte activeIds a un Set y baja a 50.000:
const activeSet = new Set(activeIds);
const activeUsers = allUsers.filter(u => activeSet.has(u.id));
Set.has() es O(1). Ese único cambio te lleva de O(n * m) a O(n + m).
Patrón 2: Deduplicación por comparación
// O(n^2) deduplication
const unique = items.filter((item, i) =>
items.findIndex(x => x.id === item.id) === i
);
Veo este patrón cada semana en revisiones de código. El findIndex recorre desde el inicio para cada elemento. Con 10.000 elementos, son hasta 100 millones de comparaciones. La solución:
const seen = new Set();
const unique = items.filter(item => {
if (seen.has(item.id)) return false;
seen.add(item.id);
return true;
});
O aún más simple con un Map si necesitas los objetos completos:
const unique = [...new Map(items.map(i => [i.id, i])).values()];
Patrón 3: El .map().filter().map() en cascada
Este es sutil. Cada método individual es O(n), y encadenar tres operaciones O(n) sigue siendo O(n); 3n es simplemente n con un factor constante. Pero se convierte en O(n^2) cuando una de esas operaciones esconde una búsqueda:
const enriched = orders
.map(order => ({
...order,
customer: customers.find(c => c.id === order.customerId), // O(n) inside O(n)
}))
.filter(order => order.customer?.active)
.map(order => formatForDisplay(order));
El pipeline funcional parece elegante. El .find() anidado lo hace cuadrático. Una tabla de búsqueda preconstruida lo soluciona sin perder legibilidad.
Patrón 4: El aplanador recursivo de árboles
function flattenComments(comments) {
return comments.reduce((flat, comment) => {
flat.push(comment);
if (comment.replies) {
flat.push(...flattenComments(comment.replies));
}
return flat;
}, []);
}
El operador spread dentro de reduce crea un nuevo array en cada llamada recursiva. Para un árbol balanceado con n nodos, esto es O(n^2) debido a la copia de arrays. La solución es usar flat.push(...result) o pasar el acumulador como parámetro:
function flattenComments(comments, result = []) {
for (const comment of comments) {
result.push(comment);
if (comment.replies) flattenComments(comment.replies, result);
}
return result;
}
Patrón 5: La consulta SQL en un bucle (el problema N+1)
Este no es exclusivo de JavaScript. Es el antipatrón de rendimiento más común en aplicaciones web:
const orders = await db.query('SELECT * FROM orders WHERE status = ?', ['active']);
for (const order of orders) {
order.items = await db.query('SELECT * FROM order_items WHERE order_id = ?', [order.id]);
}
1 consulta para pedidos + n consultas para artículos = n+1 consultas en total. Con 1.000 pedidos, son 1.001 viajes de ida y vuelta a la base de datos. El problema de consultas N+1 está ampliamente documentado, pero sigue apareciendo porque los ORMs facilitan que se dispare accidentalmente mediante carga diferida.
La solución es un JOIN o una consulta por lotes:
const orders = await db.query('SELECT * FROM orders WHERE status = ?', ['active']);
const orderIds = orders.map(o => o.id);
const items = await db.query('SELECT * FROM order_items WHERE order_id IN (?)', [orderIds]);

Cómo detectar la complejidad cuadrática antes de que producción lo haga por ti
1. Haz profiling con tamaños de datos realistas. Si tu suite de tests se ejecuta con 10 registros y producción tiene 100.000, tus tests no están midiendo nada útil. Crea fixtures de benchmark que coincidan con la cardinalidad de producción. La diferencia entre O(n) y O(n^2) es invisible con n=10 y catastrófica con n=10.000.
2. Busca .find(), .includes(), .indexOf() dentro de .map(), .filter(), .reduce(). Esta comprobación mecánica detecta la mayoría de los patrones cuadráticos accidentales en bases de código JavaScript. Si quieres ver cómo escalan drásticamente las diferentes clases de complejidad, introduce los números en un Comparador de Complejidad Big O; traza cada clase desde O(1) hasta O(n!) en el mismo gráfico.
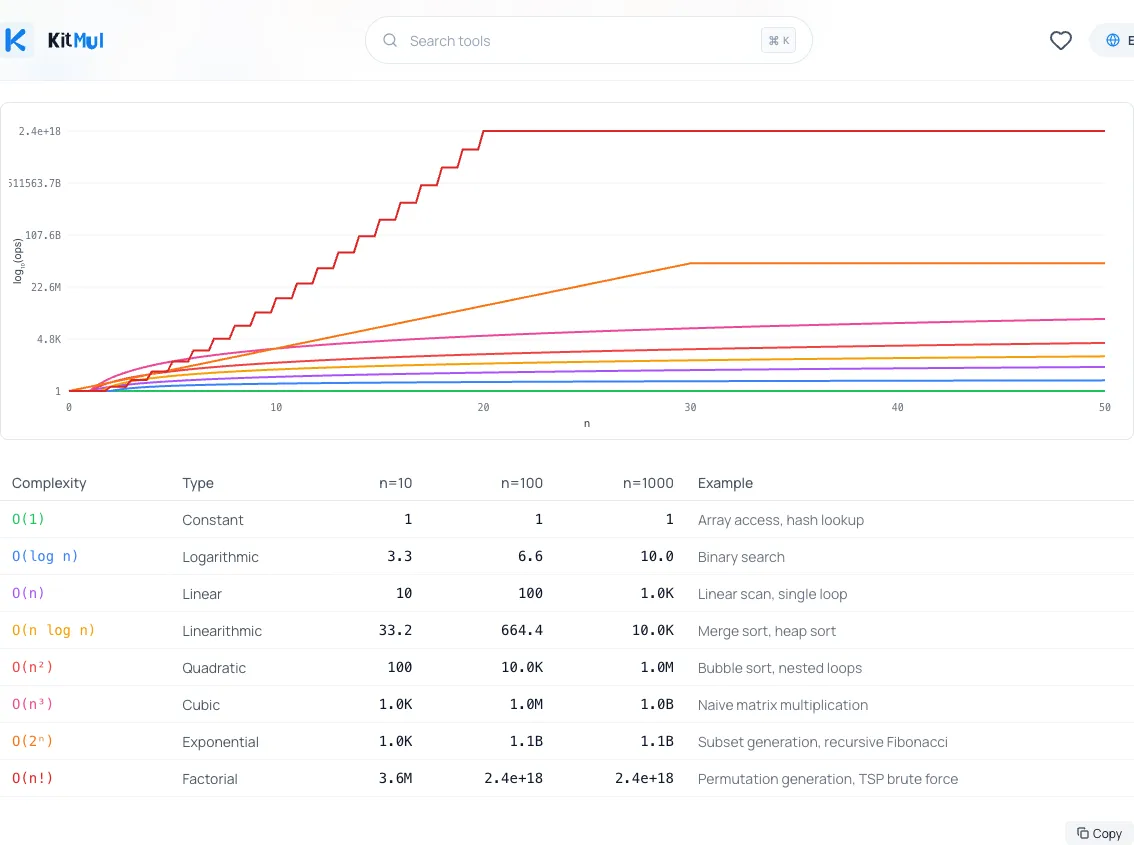
3. Añade anotaciones de complejidad en las revisiones de código. Al revisar código, pregunta: ¿qué es n? ¿Qué tan grande puede llegar a ser? ¿Cuál es la complejidad de la operación interna? Hacer esto explícito previene la sorpresa del "funciona bien en desarrollo".
4. Establece presupuestos de latencia con alertas. Si la latencia p95 de un endpoint supera los 500ms, alerta a alguien. La complejidad cuadrática suele manifestarse como una degradación gradual, no como un fallo repentino; perfecta para alertas basadas en latencia que detectan la tendencia antes de que los usuarios la noten.
5. Conoce tu biblioteca estándar. Array.sort() es O(n log n). Set.has() es O(1). Array.includes() es O(n). Map.get() es O(1). La diferencia entre recurrir a un método de Array y uno de Map/Set es a menudo la diferencia entre O(n^2) y O(n). La documentación de MDN sobre Colecciones con clave cubre cuándo usar cada una.
La verdadera lección
Lo peligroso del O(n^2) no es que sea lento. Es que es invisible hasta que deja de serlo. Todos los patrones anteriores pasaron la revisión de código porque eran legibles, idiomáticos y correctos. Simplemente no escalaban.
La complejidad de rendimiento no es algo que optimizas después. Es una decisión de diseño que tomas en el momento de escribir el código. La pregunta no es "¿funciona esto?" sino "¿funcionará esto cuando n sea 100 veces mayor de lo que estoy probando?"
Investigaciones de Google muestran consistentemente que cada 100ms de latencia adicional tiene un impacto medible en métricas de negocio. Un algoritmo cuadrático que añade 50ms con tu escala actual y 5.000ms con la escala del año que viene es una bomba de relojería.
Acostúmbrate a usar Map y Set por defecto. Cuestiona cada .find() y .includes() dentro de un bucle. Haz profiling con datos del tamaño de producción. El código que matará tu aplicación no parecerá peligroso; eso es exactamente lo que lo hace peligroso.
Profundiza más
Para una referencia completa de las ocho clases de complejidad con gráficos interactivos, código ejecutable y patrones de entrevista, lee la Guía Completa de Complejidad Big O.
Privacidad: Todas las herramientas de Kitmul se ejecutan completamente en tu navegador. No se envían datos a ningún servidor. Sin cuenta obligatoria. Sin rastreo más allá de analíticas básicas.