
Suspendí mi primera entrevista de algoritmos porque dije "depende" cuando me preguntaron por la complejidad temporal de una función de búsqueda. El entrevistador quería O(log n). Yo sabía que era una búsqueda binaria. Incluso sabía que era logarítmica. Pero entré en pánico y empecé a divagar sobre líneas de caché, predicción de saltos y si el array cabía en L1. Los ojos del entrevistador se quedaron en blanco. "Depende" es técnicamente correcto y prácticamente inútil cuando alguien quiere saber si tu solución seguirá funcionando cuando la entrada crezca de 1.000 a 1.000.000.
Esa entrevista me enseñó algo que tardé años en interiorizar del todo: la notación Big O no va de precisión. Va de la forma del crecimiento. Te dice cómo se comporta un algoritmo cuando la entrada se hace grande; no el número exacto de operaciones, no el tiempo real de ejecución, sino la curva.
Y una vez que ves las curvas, todo encaja.
Por qué Big O importa fuera de las entrevistas
Voy a ser directo: la mayoría de los programadores que conozco aprendieron Big O para las entrevistas y lo olvidaron al instante. Eso es un error.
El año pasado tenía un servicio en producción que funcionaba perfectamente con 500 usuarios y se caía con 5.000. El culpable era un bucle anidado en el que nadie reparó durante la revisión de código. Dos llamadas a .filter() dentro de un .map(). Se veía limpió. Se leía de maravilla. Era O(n^3). Con 500 elementos tardaba 120ms. Con 5.000 elementos; 12 segundos. Con 50.000 elementos habría tardado 20 minutos.
La complejidad temporal es la diferencia entre "funciona en mi máquina" y "funciona en producción". Es la razón por la que algunos sistemas escalan con elegancia y otros chocan contra un muro. No es algo académico. Es lo más práctico de la informática.
Las ocho clases de complejidad; código real, consecuencias reales
Vamos a recorrer cada clase con código que puedes ejecutar. Usaré JavaScript porque se lee como pseudocódigo para la mayoría de los desarrolladores, pero los conceptos son independientes del lenguaje.
O(1); tiempo constante
function getFirst(arr) {
return arr[0];
}
Da igual si el array tiene 10 elementos o 10 millones. Una operación. Las búsquedas en tablas hash también son O(1) de media; por eso recurres a un Map o un objeto cuando necesitas acceso rápido por clave. La parte de "de media" importa (las colisiones hash existen), pero en la práctica este es el estándar de oro.
O(log n); logarítmico
function binarySearch(sorted, target) {
let lo = 0, hi = sorted.length - 1;
while (lo <= hi) {
const mid = Math.floor((lo + hi) / 2);
if (sorted[mid] === target) return mid;
if (sorted[mid] < target) lo = mid + 1;
else hi = mid - 1;
}
return -1;
}
La búsqueda binaria reduce el problema a la mitad en cada pasó. ¿Buscar entré 1.000 millones de elementos ordenados? Unas 30 comparaciones. Esa es la magia de los logaritmos. Cada vez que duplicas la entrada, solo añades un paso más. Los índices de bases de datos funcionan con este principio (los B-trees son esencialmente búsqueda binaria multidireccional).
O(n); lineal
function findMax(arr) {
let max = arr[0];
for (const val of arr) {
if (val > max) max = val;
}
return max;
}
Tocas cada elemento una vez. Duplicas la entrada, duplicas el tiempo. A menudo es lo mejor que puedes hacer cuando necesitas examinar todos los datos. Si alguien te dice que "optimices" un recorrido lineal que genuinamente necesita ver cada elemento, te está pidiendo magia.
O(n log n); linearítmico
Aquí es donde viven los algoritmos de ordenación por comparación eficientes. Merge sort, quicksort (caso promedio), heapsort. Existe un límite inferior demostrado; no se pueden ordenar n elementos comparando pares en menos de O(n log n) comparaciones. Es una imposibilidad matemática, demostrada mediante árboles de decisión.
function mergeSort(arr) {
if (arr.length <= 1) return arr;
const mid = Math.floor(arr.length / 2);
const left = mergeSort(arr.slice(0, mid));
const right = mergeSort(arr.slice(mid));
return merge(left, right);
}
function merge(a, b) {
const result = [];
let i = 0, j = 0;
while (i < a.length && j < b.length) {
result.push(a[i] <= b[j] ? a[i++] : b[j++]);
}
return result.concat(a.slice(i), b.slice(j));
}
La complejidad temporal de merge sort es O(n log n) en todos los casos; peor, promedio y mejor. Por eso es la ordenación por defecto en muchas bibliotecas estándar. Su complejidad espacial es O(n); necesitas ese array auxiliar. Compromisos por todas partes.
O(n^2); cuadrático
function bubbleSort(arr) {
const n = arr.length;
for (let i = 0; i < n; i++) {
for (let j = 0; j < n - i - 1; j++) {
if (arr[j] > arr[j + 1]) {
[arr[j], arr[j + 1]] = [arr[j + 1], arr[j]];
}
}
}
return arr;
}
Dos bucles anidados sobre la entrada. 1.000 elementos significan ~1.000.000 de operaciones. 10.000 elementos significan ~100.000.000. Aquí es donde viven los bugs de "funciona bien en desarrolló". Ese .filter() anidado dentro de .map() que mencioné antes? La clásica trampa cuadrática disfrazada de sintaxis funcional.
O(2^n); exponencial
function fibonacci(n) {
if (n <= 1) return n;
return fibonacci(n - 1) + fibonacci(n - 2);
}
El Fibonacci recursivo ingenuo. Cada llamada se bifurca en dos más. Con n=30 estás haciendo más de mil millones de llamadas a funciones. Con n=50 tu máquina se rinde. La solución es la memoización (reduciéndolo a O(n)) o un enfoque iterativo. Pero la versión ingenua es el ejemplo canónico de por qué los algoritmos exponenciales son efectivamente inutilizables para cualquier cosa más allá de entradas diminutas.
O(n!); factorial
function permutations(arr) {
if (arr.length <= 1) return [arr];
const result = [];
for (let i = 0; i < arr.length; i++) {
const rest = [...arr.slice(0, i), ...arr.slice(i + 1)];
for (const perm of permutations(rest)) {
result.push([arr[i], ...perm]);
}
}
return result;
}
Generar todas las permutaciones. 10 elementos = 3.628.800 permutaciones. 15 elementos = más de 1,3 billones. 20 elementos = más que el número de segundos desde que comenzó el universo. El problema del viajante vive aquí (fuerza bruta). Por eso los problemas NP-hard son difíciles; si encuentras una solución eficiente para uno de ellos, recoge tu premio del milenio.
Ver las curvas lo hace real
Construí un Comparador de Complejidad Big O porque mirar la notación en una página no transmite la diferencia visceral entré estas clases. Cuando ploteas O(n), O(n log n) y O(n^2) en el mismo gráfico, la curva cuadrática se dispara tan agresivamente que la lineal parece plana en comparación. Y O(2^n) y O(n!) hacen que O(n^2) parezca plana.
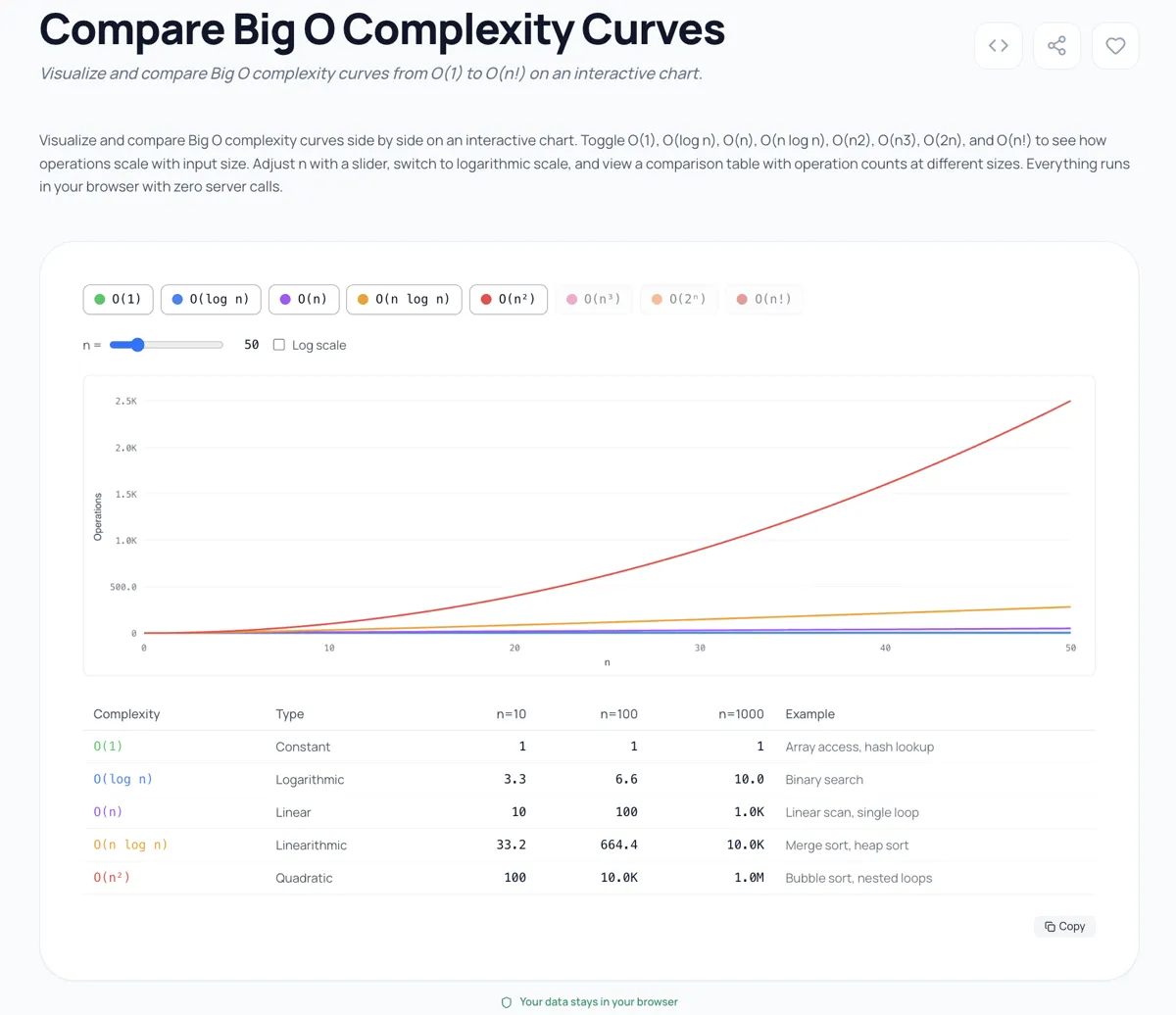
La herramienta representa las ocho clases simultáneamente en escala logarítmica para que puedas ver las relaciones. Juega con el control de tamaño de entrada y observa lo que pasa por encima de n=20. Las curvas exponencial y factorial se salen del gráfico por completó. No es una exageración para lograr efecto visual; esos son los valores reales. Con n=25, O(n!) es 15.511.210.043.330.985.984.000.000. Tu solución O(n^2) de repente parece rápida en comparación.
Tres cosas que la mayoría de la gente entiende mal sobre Big O
1. Las constantes importan en la práctica. Big O descarta las constantes. O(2n) y O(n) son ambos "O(n)". Pero en código real, un factor constante de 10x es la diferencia entre una respuesta de 100ms y una de 1 segundo. Un algoritmo con un bucle interno ajustado y buena localidad de caché a O(n log n) aplastará a un algoritmo teóricamente equivalente O(n log n) que machaque la memoria. CLRS (la biblia de los algoritmos; Introduction to Algorithms de Cormen, Leiserson, Rivest y Stein) reconoce esto; los "factores constantes" que ignora con la mano en las demostraciones se convierten en decisiones de ingeniería en producción.
2. La complejidad amortizada no es la complejidad promedio. Cuando alguien dice que ArrayList.add() es O(1) amortizado, quiere decir que ocasionalmente es O(n) (cuando necesita redimensionarse), pero esas operaciones costosas se reparten de modo que, a lo largo de n operaciones, el coste total es O(n). Eso es diferente de decir que el caso promedio es O(1). Amortizado es una garantía sobre una secuencia; caso promedio depende de la distribución de la entrada.
3. La complejidad espacial es igual de importante. He visto ingenieros optimizar la complejidad temporal de O(n^2) a O(n) y celebrar; solo para descubrir que su solución O(n) usa O(n^2) de espacio. En un servidor con 4GB de RAM procesando 10 millones de registros, la complejidad espacial te mata más rápido que la temporal. Pregunta siempre ambas cosas: cuánto tarda y cuánta memoria necesita.
Cómo analizar tu propio código
Este es mi método pasó a pasó. Lo aplicó cada vez que reviso código que procesa entradas de tamaño variable:
- Identifica la entrada. ¿Qué variable determina el tamaño? Normalmente es la longitud de un array, el número de filas, el número de nodos.
- Encuentra los bucles. Cada bucle que itera sobre la entrada contribuye al menos O(n). Los bucles anidados se multiplican.
- Cuidado con los bucles ocultos. Métodos de array como
.filter(),.map(),.indexOf(),.includes()son todos O(n). Encadenar tres de ellos sigue siendo O(n); anidar uno dentro de otro es O(n^2). - Revisa las llamadas recursivas. ¿Cuántas veces se llama la función a sí misma? La recursión binaria (dos llamadas) es O(2^n) sin memoización. Si la recursión reduce el problema a la mitad cada vez, es O(log n).
- Ten en cuenta las operaciones integradas.
Array.sort()es O(n log n).Set.has()es O(1).Array.includes()es O(n). Conoce tu biblioteca estándar.

Preparación para entrevistas; cinco patrones que cubren el 80% de las preguntas
Después de realizar unas 200 entrevistas de programación (en ambos lados de la mesa), está es mi hoja de trucos de Big O para los patrones que aparecen constantemente:
1. Hash map para eliminar un bucle anidado. Si tu fuerza bruta es O(n^2) porque buscas un complemento o coincidencia en un bucle interno, un hash map lo convierte en O(n). Ejemplo clásico: two sum.
2. Ordenar primero, luego usar búsqueda binaria o dos punteros. Ordenar cuesta O(n log n) de entrada pero desbloquea búsquedas en O(log n). Total: O(n log n). Casi siempre mejor que fuerza bruta O(n^2).
3. Ventana deslizante para problemas de subarrays o subcadenas. Convierte fuerza bruta O(n^2) o O(n^3) en O(n) manteniendo una ventana que avanza por los datos. Subarray máximo, subcadena más larga sin repeticiones; todo ventana deslizante.
4. Divide y vencerás para O(n log n). Divide el problema, resuelve las mitades recursivamente, combina. Merge sort es el ejemplo de libro de texto, pero aparece en par de puntos más cercano, conteo de inversiones y multiplicación de matrices.
5. Programación dinámica para eliminar la recursión exponencial. Memoiza subproblemas solapados para colapsar O(2^n) a O(n) o O(n^2). Fibonacci, cambió de monedas, subsecuencia común más larga. Si ves subproblemas solapados y subestructura óptima, recurre a DP.
Estos cinco patrones no cubren todo, pero cubren lo suficiente para superar la mayoría de las entrevistas de algoritmos. Para profundizar, recomiendo de verdad trabajar los problemas con un comparador visual de complejidad abierto. Ver dónde cae tu solución en la curva construye intuición más rápido que memorizar reglas.
Explora más herramientas
Si el Comparador de Complejidad Big O te resultó útil, echa un vistazo al resto de la colección de Visualizadores y Lógica en Kitmul. Tenemos herramientas para visualización de regex, exploración de AST y otros fundamentos de informática. Todas gratuitas, todas en el navegador, todas privadas; tus datos nunca salen de tu máquina.
Privacidad: Todas las herramientas de Kitmul se ejecutan completamente en tu navegador. No se envían datos a ningún servidor. No se requiere cuenta. Sin rastreo más allá de analíticas básicas.