
We shipped a feature on a Tuesday. By Thursday the API was timing out. The monitoring dashboard showed p99 latency climbing from 80ms to 14 seconds over 48 hours. Nothing had changed except the number of users.
The culprit was three lines of code that looked completely reasonable during review:
const results = users.map(user => {
const match = permissions.find(p => p.userId === user.id);
return { ...user, role: match?.role ?? 'viewer' };
});
Clean. Readable. Functional style. Also O(n * m), which in our case was O(n^2) because users and permissions grew at the same rate. At 200 users, 40,000 comparisons. At 2,000 users, 4,000,000. At 20,000 users, 400,000,000. The fix was a one-liner; build a Map first:
const permMap = new Map(permissions.map(p => [p.userId, p.role]));
const results = users.map(user => ({
...user,
role: permMap.get(user.id) ?? 'viewer',
}));
O(n + m) instead of O(n * m). Problem solved. But the real question is: why did nobody catch it?
The O(n^2) trap hides in plain sight
Quadratic complexity is the most dangerous performance class in production software. Not because it's the slowest; O(2^n) and O(n!) are far worse. But because it looks fine. It passes code review. It works in development. It even works in staging if your test dataset is small enough. Then it hits production with real data volumes and everything falls apart.
The pattern is almost always the same: a lookup operation nested inside an iteration. Array.prototype.find(), Array.prototype.includes(), Array.prototype.indexOf(); these are all O(n) operations. Put them inside a loop and you've got O(n^2). Put them inside two nested loops and you've got O(n^3). JavaScript's expressive array methods make this especially easy to miss because the code reads like English instead of looking like nested for loops.
Here are five real patterns I've seen break production systems.
Pattern 1: The innocent .includes() inside .filter()
// Looks clean, but O(n * m)
const activeUsers = allUsers.filter(u => activeIds.includes(u.id));
If activeIds is an array with 10,000 entries and allUsers has 50,000 entries, you're doing 500,000,000 comparisons. Convert activeIds to a Set and it drops to 50,000:
const activeSet = new Set(activeIds);
const activeUsers = allUsers.filter(u => activeSet.has(u.id));
Set.has() is O(1). That one change takes you from O(n * m) to O(n + m).
Pattern 2: Deduplication by comparison
// O(n^2) deduplication
const unique = items.filter((item, i) =>
items.findIndex(x => x.id === item.id) === i
);
I see this pattern weekly in code reviews. The findIndex scans from the start for every element. For 10,000 items, that's up to 100 million comparisons. The fix:
const seen = new Set();
const unique = items.filter(item => {
if (seen.has(item.id)) return false;
seen.add(item.id);
return true;
});
Or even simpler with a Map if you need the full objects:
const unique = [...new Map(items.map(i => [i.id, i])).values()];
Pattern 3: The cascading .map().filter().map()
This one is subtle. Each individual method is O(n), and chaining three O(n) operations is still O(n); 3n is just n with a constant factor. But it becomes O(n^2) when one of those operations hides a lookup:
const enriched = orders
.map(order => ({
...order,
customer: customers.find(c => c.id === order.customerId), // O(n) inside O(n)
}))
.filter(order => order.customer?.active)
.map(order => formatForDisplay(order));
The functional pipeline looks elegant. The nested .find() makes it quadratic. A pre-built lookup table fixes it with zero loss of readability.
Pattern 4: The recursive tree flattener
function flattenComments(comments) {
return comments.reduce((flat, comment) => {
flat.push(comment);
if (comment.replies) {
flat.push(...flattenComments(comment.replies));
}
return flat;
}, []);
}
The spread operator inside reduce creates a new array on every recursive call. For a balanced tree with n nodes, this is O(n^2) due to array copying. The fix is flat.push(...result) or passing the accumulator through:
function flattenComments(comments, result = []) {
for (const comment of comments) {
result.push(comment);
if (comment.replies) flattenComments(comment.replies, result);
}
return result;
}
Pattern 5: The SQL query in a loop (the N+1 problem)
This one isn't JavaScript-specific. It's the most common performance antipattern in web applications:
const orders = await db.query('SELECT * FROM orders WHERE status = ?', ['active']);
for (const order of orders) {
order.items = await db.query('SELECT * FROM order_items WHERE order_id = ?', [order.id]);
}
1 query for orders + n queries for items = n+1 queries total. With 1,000 orders, that's 1,001 database round trips. The N+1 query problem is well-documented, but it keeps showing up because ORMs make it easy to trigger accidentally through lazy loading.
The fix is a JOIN or a batch query:
const orders = await db.query('SELECT * FROM orders WHERE status = ?', ['active']);
const orderIds = orders.map(o => o.id);
const items = await db.query('SELECT * FROM order_items WHERE order_id IN (?)', [orderIds]);

How to catch quadratic complexity before production does
1. Profile with realistic data sizes. If your test suite runs with 10 records and production has 100,000, your tests are measuring nothing useful. Create benchmark fixtures that match production cardinality. The difference between O(n) and O(n^2) is invisible at n=10 and catastrophic at n=10,000.
2. Grep for .find(), .includes(), .indexOf() inside .map(), .filter(), .reduce(). This mechanical check catches the majority of accidental quadratic patterns in JavaScript codebases. If you want to see how dramatically different complexity classes scale, plug the numbers into a Big O Complexity Comparator; it plots every class from O(1) to O(n!) on the same chart.
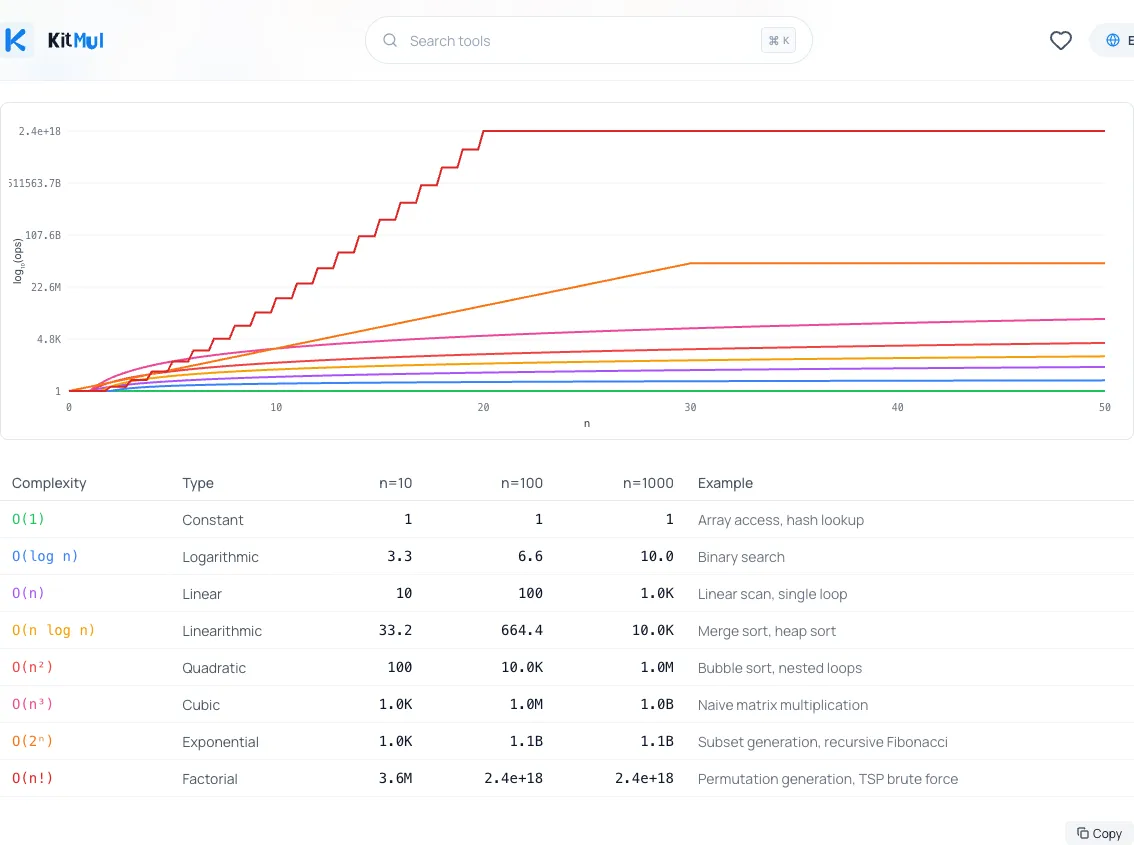
3. Add complexity annotations to code reviews. When reviewing code, ask: what is n? How big can it get? What's the complexity of the inner operation? Making this explicit prevents the "it works fine in dev" surprise.
4. Set latency budgets with alerts. If an endpoint's p95 latency crosses 500ms, page someone. Quadratic complexity typically manifests as a gradual degradation, not a sudden failure; perfect for latency-based alerts that catch the trend before users notice.
5. Know your standard library. Array.sort() is O(n log n). Set.has() is O(1). Array.includes() is O(n). Map.get() is O(1). The difference between reaching for an Array method and a Map/Set method is often the difference between O(n^2) and O(n). The MDN Web Docs on Keyed Collections cover when to use each.
The real lesson
The dangerous thing about O(n^2) isn't that it's slow. It's that it's invisible until it isn't. Every one of the patterns above passed code review because the code was readable, idiomatic, and correct. It just didn't scale.
Performance complexity isn't something you optimize for later. It's a design decision you make at the time you write the code. The question isn't "does this work?" but "does this work when n is 100x what I'm testing with?"
Research from Google consistently shows that every 100ms of added latency costs measurable business metrics. A quadratic algorithm that adds 50ms at your current scale and 5,000ms at next year's scale is a ticking time bomb.
Build the habit of reaching for Map and Set by default. Question every .find() and .includes() inside a loop. Profile with production-sized data. The code that kills your app won't look dangerous; that's exactly what makes it dangerous.
Dive deeper
For a complete reference on all eight complexity classes with interactive charts, runnable code, and interview patterns, read the Complete Guide to Big O Complexity.
Privacy: Every tool on Kitmul runs entirely in your browser. No data is sent to any server. No account required. No tracking beyond basic analytics.