
I failed my first algorithm interview because I said "it depends" when asked about the time complexity of a search function. The interviewer wanted O(log n). I knew it was a binary search. I even knew it was logarithmic. But I panicked and started rambling about cache lines and branch prediction and whether the array fit in L1. The interviewer's eyes glazed over. "It depends" is technically correct and practically useless when someone wants to know if your solution will still work when the input grows from 1,000 to 1,000,000.
That interview taught me something that took years to fully internalize: Big O notation isn't about precision. It's about the shape of growth. It tells you how an algorithm behaves as the input gets large; not the exact number of operations, not the wall-clock time, but the curve.
And once you see the curves, everything clicks.
Why Big O matters outside of interviews
Let me be direct: most working programmers I know learned Big O for interviews and promptly forgot it. That's a mistake.
Last year I had a production service that worked perfectly with 500 users and fell over at 5,000. The culprit was a nested loop that nobody thought twice about during code review. Two .filter() calls inside a .map(). Looked clean. Read beautifully. Was O(n^3). At 500 items it ran in 120ms. At 5,000 items; 12 seconds. At 50,000 items it would have taken 20 minutes.
Time complexity is the difference between "works on my machine" and "works in production." It's the reason some systems scale gracefully and others hit a wall. It's not academic. It's the most practical thing in computer science.
The eight complexity classes; real code, real consequences
Let me walk through each class with actual code you can run. I'll use JavaScript because it reads like pseudocode for most developers, but the concepts are language-agnostic.
O(1); constant time
function getFirst(arr) {
return arr[0];
}
Doesn't matter if the array has 10 elements or 10 million. One operation. Hash table lookups are O(1) on average too; that's why you reach for a Map or an object when you need fast access by key. The "on average" part matters (hash collisions exist), but in practice this is the gold standard.
O(log n); logarithmic
function binarySearch(sorted, target) {
let lo = 0, hi = sorted.length - 1;
while (lo <= hi) {
const mid = Math.floor((lo + hi) / 2);
if (sorted[mid] === target) return mid;
if (sorted[mid] < target) lo = mid + 1;
else hi = mid - 1;
}
return -1;
}
Binary search cuts the problem in half every step. Search through 1 billion sorted items? About 30 comparisons. That's the magic of logarithms. Every time you double the input, you add just one more step. Database indexes work on this principle (B-trees are essentially multi-way binary search).
O(n); linear
function findMax(arr) {
let max = arr[0];
for (const val of arr) {
if (val > max) max = val;
}
return max;
}
Touch every element once. Double the input, double the time. This is often the best you can do when you need to examine all the data. If someone tells you to "optimize" a linear scan that genuinely needs to see every element, they're asking for magic.
O(n log n); linearithmic
This is where efficient comparison sorts live. Merge sort, quicksort (average case), heapsort. There's a proven lower bound here; you cannot sort n items by comparing pairs in fewer than O(n log n) comparisons. It's a mathematical impossibility, proven via decision trees.
function mergeSort(arr) {
if (arr.length <= 1) return arr;
const mid = Math.floor(arr.length / 2);
const left = mergeSort(arr.slice(0, mid));
const right = mergeSort(arr.slice(mid));
return merge(left, right);
}
function merge(a, b) {
const result = [];
let i = 0, j = 0;
while (i < a.length && j < b.length) {
result.push(a[i] <= b[j] ? a[i++] : b[j++]);
}
return result.concat(a.slice(i), b.slice(j));
}
Merge sort's time complexity is O(n log n) in all cases; worst, average, and best. That's why it's the default sort in many standard libraries. Its space complexity is O(n) though; you need that auxiliary array. Trade-offs everywhere.
O(n^2); quadratic
function bubbleSort(arr) {
const n = arr.length;
for (let i = 0; i < n; i++) {
for (let j = 0; j < n - i - 1; j++) {
if (arr[j] > arr[j + 1]) {
[arr[j], arr[j + 1]] = [arr[j + 1], arr[j]];
}
}
}
return arr;
}
Two nested loops over the input. 1,000 items means ~1,000,000 operations. 10,000 items means ~100,000,000. This is where the "works fine in development" bugs live. That nested .filter() inside .map() I mentioned earlier? Classic quadratic trap dressed up in functional syntax.
O(2^n); exponential
function fibonacci(n) {
if (n <= 1) return n;
return fibonacci(n - 1) + fibonacci(n - 2);
}
The naive recursive Fibonacci. Every call branches into two more. At n=30 you're making over a billion function calls. At n=50 your machine gives up. The fix is memoization (bringing it down to O(n)) or an iterative approach. But the naive version is the canonical example of why exponential algorithms are effectively unusable for anything beyond tiny inputs.
O(n!); factorial
function permutations(arr) {
if (arr.length <= 1) return [arr];
const result = [];
for (let i = 0; i < arr.length; i++) {
const rest = [...arr.slice(0, i), ...arr.slice(i + 1)];
for (const perm of permutations(rest)) {
result.push([arr[i], ...perm]);
}
}
return result;
}
Generating all permutations. 10 items = 3,628,800 permutations. 15 items = over 1.3 trillion. 20 items = more than the number of seconds since the universe began. The travelling salesman problem lives here (brute force). This is why NP-hard problems are hard; if you find an efficient solution to one of them, collect your millennium prize.
Seeing the curves makes it real
I built a Big O Complexity Comparator because staring at notation on a page doesn't convey the visceral difference between these classes. When you plot O(n), O(n log n), and O(n^2) on the same chart, the quadratic curve shoots up so aggressively that the linear one looks flat by comparison. And O(2^n) and O(n!) make O(n^2) look flat.
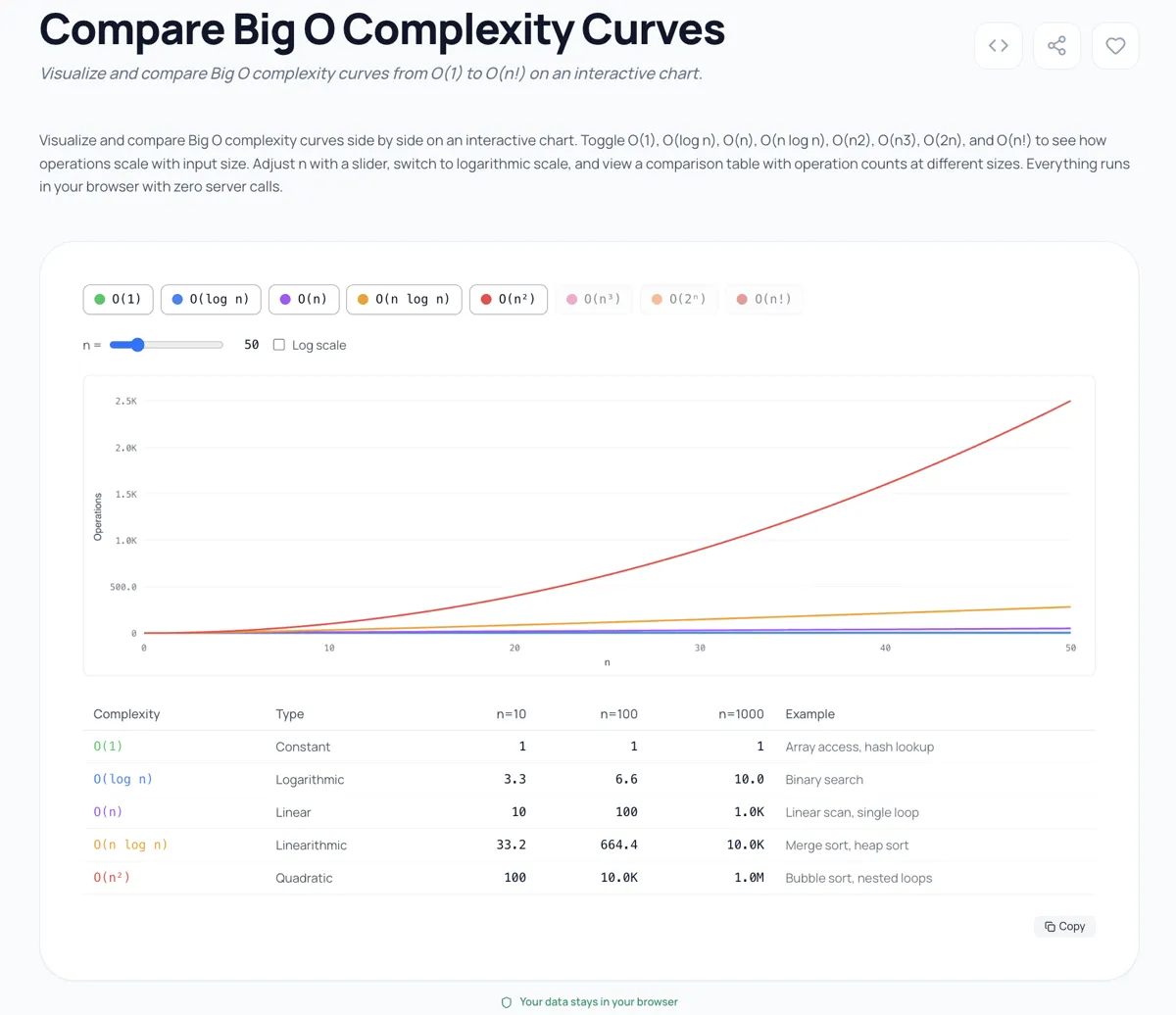
The tool plots all eight classes simultaneously on a logarithmic scale so you can see the relationships. Play with the input size slider and watch what happens above n=20. The exponential and factorial curves leave the chart entirely. That's not an exaggeration for visual effect; those are the actual values. At n=25, O(n!) is 15,511,210,043,330,985,984,000,000. Your O(n^2) solution suddenly looks fast by comparison.
Three things most people get wrong about Big O
1. Constants matter in practice. Big O drops constants. O(2n) and O(n) are both "O(n)." But in real code, a constant factor of 10x is the difference between a 100ms response and a 1-second response. An algorithm with a tight inner loop and good cache locality at O(n log n) will obliterate a theoretically equivalent O(n log n) algorithm that thrashes memory. CLRS (the algorithms bible; Introduction to Algorithms by Cormen, Leiserson, Rivest, and Stein) acknowledges this; the "constant factors" it handwaves away in proofs become engineering decisions in production.
2. Amortized complexity is not average complexity. When someone says ArrayList.add() is O(1) amortized, they mean that occasionally it's O(n) (when it needs to resize), but those expensive operations are spread out so that over n operations, the total cost is O(n). That's different from saying the average case is O(1). Amortized is a guarantee over a sequence; average case depends on input distribution.
3. Space complexity is just as important. I've seen engineers optimize time complexity from O(n^2) to O(n) and celebrate; only to discover their O(n) solution uses O(n^2) space. On a server with 4GB of RAM processing 10 million records, space complexity kills you faster than time complexity. Always ask both questions: how long does it take, and how much memory does it need?
How to analyze your own code
Here's my step-by-step method. I do this every time I review code that processes variable-size input:
- Identify the input. What variable determines the size? Usually it's the length of an array, the number of rows, the number of nodes.
- Find the loops. Every loop that iterates over the input contributes at least O(n). Nested loops multiply.
- Watch for hidden loops. Array methods like
.filter(),.map(),.indexOf(),.includes()are all O(n). Chaining three of them is still O(n); nesting one inside another is O(n^2). - Check recursive calls. How many times does the function call itself? Binary recursion (two calls) is O(2^n) without memoization. If the recursion halves the problem each time, it's O(log n).
- Account for built-in operations.
Array.sort()is O(n log n).Set.has()is O(1).Array.includes()is O(n). Know your standard library.

Interview prep; five patterns that cover 80% of questions
After doing about 200 coding interviews (both sides of the table), here's my Big O cheat sheet for the patterns that come up constantly:
1. Hash map to eliminate a nested loop. If your brute force is O(n^2) because you're searching for a complement/match in an inner loop, a hash map makes it O(n). Classic example: two sum.
2. Sort first, then use binary search or two pointers. Sorting costs O(n log n) upfront but unlocks O(log n) lookups. Total: O(n log n). Almost always better than O(n^2) brute force.
3. Sliding window for subarray/substring problems. Turns O(n^2) or O(n^3) brute force into O(n) by maintaining a window that advances through the data. Maximum subarray, longest substring without repeats; all sliding window.
4. Divide and conquer for O(n log n). Split the problem, solve halves recursively, combine. Merge sort is the textbook example, but it shows up in closest pair of points, counting inversions, and matrix multiplication.
5. Dynamic programming to kill exponential recursion. Memoize overlapping subproblems to collapse O(2^n) to O(n) or O(n^2). Fibonacci, coin change, longest common subsequence. If you see overlapping subproblems and optimal substructure, reach for DP.
These five patterns won't cover everything, but they cover enough to pass most algorithm interviews. For a deeper dive, I genuinely recommend working through problems with a visual complexity comparator open. Seeing where your solution falls on the curve builds intuition faster than memorizing rules.
Explore more tools
If you found the Big O Complexity Comparator useful, check out the rest of the Visualizers & Logic collection on Kitmul. We have tools for regex visualization, AST exploration, and other computer science fundamentals. All free, all browser-based, all private; your data never leaves your machine.
Privacy: Every tool on Kitmul runs entirely in your browser. No data is sent to any server. No account required. No tracking beyond basic analytics.