
2018 schrieb ich meinen ersten Blogpost über TensorFlow.js. Ich führte PoseNet in einem Browser-Tab aus; Echtzeit-Pose-Erkennung von Menschen ohne jegliche Server-Infrastruktur. Die Idee wirkte damals radikal. Leute fragten, warum ich keinen dedizierten GPU-Server nutzte. Meine Antwort war damals dieselbe wie heute: weil der Browser reicht, und es nichts kostet.
Acht Jahre später gilt dasselbe Prinzip für Objekterkennung. Ich habe YOLO nie von einem Server ausgeführt. Kein einziges Mal. Die Prämisse, Benutzerbilder auf die GPU eines anderen zu schicken, ergab für mich nie Sinn, wenn WebGL bereits da war, in jedem Laptop eingebaut.
Das Argument, das ich seit 2018 mache
In jenem TensorFlow.js-Post schrieb ich etwas, das immer noch gilt:
Vor TensorFlow.js war es unmöglich, Machine-Learning-Modelle direkt im Browser ohne API-Interaktion zu nutzen. Jetzt können wir Modelle offline trainieren und nutzen. Vorhersagen sind viel schneller, weil sie keine Anfrage an den Server brauchen. Ein weiterer Vorteil sind die niedrigen Serverkosten, weil all diese Berechnungen jetzt clientseitig stattfinden.
Drei Vorteile. Sie haben sich nicht geändert:
1. Null Serverkosten. Jede Inferenz, die auf dem Gerät des Nutzers läuft, ist eine, die du nicht bezahlst. Ich baute einen Katze/Hund-Bildklassifizierer, einen Text-Toxizitäts-Detektor, PoseNet-Demos; alles komplett im Browser laufend. Meine AWS-Rechnung für ML-Inferenz war acht Jahre lang null, weil ich nie eine gestartet habe.
2. Offline-Vorhersagen. Das Modell wird einmal heruntergeladen, vom Browser gecacht, und funktioniert für immer ohne Netzwerkverbindung. Versuch das mal mit einer Cloud-API.
3. Privatsphäre durch Architektur. Wenn es keinen Server gibt, gibt es nichts, dem man vertrauen muss. Die Daten des Nutzers bleiben auf seinem Gerät, weil es physisch nirgendwo anders hingeht. Das ist keine Policy-Entscheidung; es ist eine strukturelle Garantie.
Warum die Industrie den anderen Weg ging
Die meisten Unternehmen wählten trotzdem den Server-Weg. Die Gründe waren damals praktisch: WebGL war unreif, Wasm existierte noch nicht, Modelle waren zu groß für die Browser-Auslieferung. Die Branche konvergierte auf ein Muster; Bild hochladen, Inferenz auf GPU ausführen, JSON zurückgeben.
Dieses Muster schuf Probleme, mit denen Leute heute noch kämpfen:
Privatsphäre ist eine rechtliche Belastung. Dein Bild erreicht einen Server, wird geloggt, vielleicht für "Modellverbesserung" gespeichert. Die DSGVO und der CCPA existieren genau deshalb, weil diese Architektur standardmäßig Nutzerdaten preisgibt. Jedes Bild, das an eine Erkennungs-API gesendet wird, ist eine Belastung unter Artikel 9 DSGVO.
Latenz summiert sich. 2MB hochladen, auf Inferenz warten, Ergebnisse herunterladen. Bei guter Verbindung: 800ms-2s. Auf dem Handy: Timeout. Die Google Web Vitals Forschung zeigt, dass Nutzer Aufgaben nach 3 Sekunden abbrechen. Erkennung mit Server-Roundtrip passt gerade so.
Kosten skalieren linear. Tausend Erkennungen über eine Cloud-API bedeuten eine Rechnung. Das macht Prototyping teuer und tötet Experimentierung; genau das Gegenteil von dem, was ich 2018 wollte, als ich einfach nur versuchte, PoseNet mit einer Webcam zum Laufen zu bringen.
Was gereift ist: WebAssembly hat WebGL eingeholt
2018 war ML im Browser limitiert. TensorFlow.js nutzte WebGL für GPU-Zugang, aber das Ökosystem war klein und die Modelle einfach. Seitdem:
WebAssembly erreichte nahezu native Ausführungsgeschwindigkeit. Das ONNX Runtime Team hat ein Wasm-Backend veröffentlicht, das vollständige neuronale Netzwerk-Graphen im Browser ausführt. Das bedeutet, dass Modelle, die keine GPU brauchen (oder auf Geräten mit schwachen GPUs laufen), trotzdem in akzeptabler Geschwindigkeit arbeiten.
WebGL ist deutlich gereift, und WebGPU landet jetzt in Browsern mit echtem Compute-Shader-Support. Matrixmultiplikationen, die 2018 auf der CPU Sekunden brauchten, sind jetzt in Millisekunden auf integrierten GPUs erledigt.
Das Modell-Ökosystem ist explodiert. 2018 hatte ich PoseNet und MobileNet. Heute kannst du YOLO, Whisper, Stable Diffusion, LLMs ausführen; alles clientseitig. Der ONNX Model Zoo hat Hunderte produktionsreife Modelle, optimiert für Browser-Inferenz.
Die These von 2018 war richtig. Sie brauchte nur, dass die Werkzeuge nachzogen.
Wie YOLO funktioniert (und warum es ideal für Browser-Inferenz ist)
YOLO ("You Only Look Once") ist architektonisch perfekt für clientseitige Nutzung, weil es das gesamte Bild in einem einzigen Forward Pass verarbeitet. Traditionelle Detektoren wie R-CNN machten zwei Stufen; Regionen vorschlagen, dann jede klassifizieren. Langsam und sequenziell. YOLO macht alles auf einmal:
- Das Bild in ein S x S Gitter aufteilen
- Jede Zelle sagt gleichzeitig Bounding Boxes + Konfidenz + Klassenwahrscheinlichkeiten voraus
- Non-Maximum-Suppression entfernt Duplikate
- Ausgabe: Objekte mit Koordinaten, Labels und Konfidenzwerten
Das originale Paper von 2016 von Redmon et al. erreichte 45 FPS. Die Architektur hat sich über YOLOv5, YOLOv8 und darüber hinaus entwickelt. Das Modell erkennt 80 Objektkategorien aus dem COCO-Datensatz: Personen, Fahrzeuge, Tiere, Möbel, Elektronik, Lebensmittel.
Einmal-Durchlauf-Inferenz bedeutet vorhersagbare Latenz. Keine iterativen Regionsvorschläge, kein variabler Rechenaufwand. Ein Bild rein, ein Satz Erkennungen raus. Diese Vorhersagbarkeit macht es im Browser machbar, wo du nicht davon ausgehen kannst, dass eine 3090 wartet.
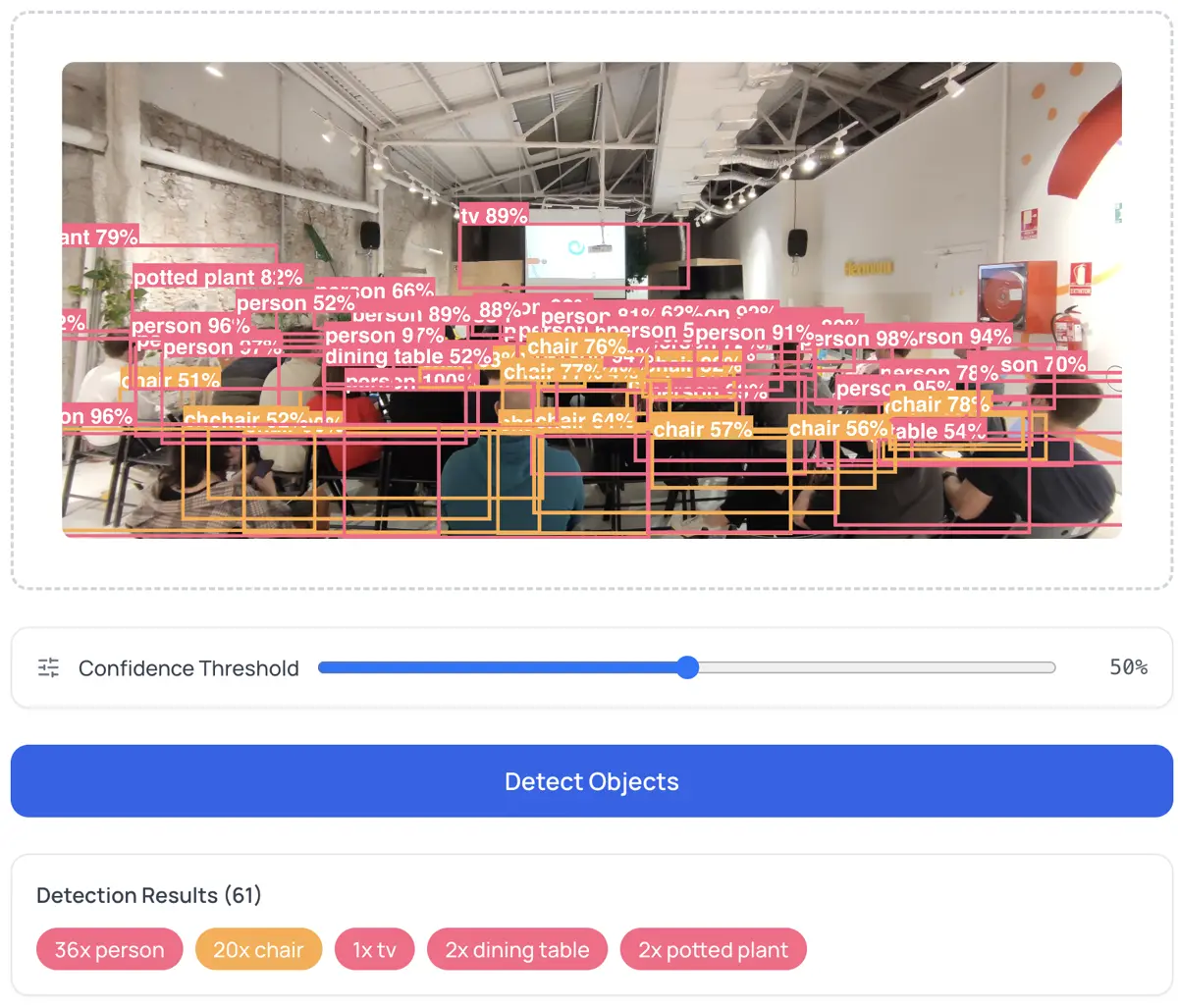
Privatsphäre ist kein Feature; es ist die Abwesenheit eines Servers
Ich komme immer wieder darauf zurück, weil es der Kern ist, warum ich Dinge so baue. Wenn ich sage "läuft in deinem Browser", meine ich: öffne die DevTools, geh zum Network-Tab, führe eine Erkennung aus. Null ausgehende Anfragen nach dem initialen Modell-Download. Dein Bild bleibt im Browser-Speicher, wird von der GPU verarbeitet, und die Ergebnisse werden auf einem Canvas-Element gerendert.
Das zählt in Fällen, wo serverseitige Verarbeitung entweder illegal oder absurd ist:
- Medizinische Bildgebung. Krankenhäuser können keine Patienten-Scans an beliebige APIs schicken. HIPAA-Verstöße beginnen bei $100 pro Datensatz.
- Überwachungsaufnahmen. Kamera-Feeds an Cloud-Dienste zu senden ist in den meisten EU-Jurisdiktionen ein rechtliches Minenfeld.
- Persönliche Fotos. Menschen wollen ihre Familienfotos nicht auf dem Computer eines anderen. Die Tatsache, dass das gesagt werden muss, ist das Problem.
Mit Browser-basierter Erkennung ist die Vertrauensfrage irrelevant. Es gibt keinen Server, dem man vertrauen muss.
Was du damit machen kannst
Objekte zählen. Lade ein Parkplatzfoto hoch und erhalte eine Fahrzeugzählung. Lagerregal; zähle Kartons. Eventfoto; zähle Personen. Kein Code, keine Einrichtung.
Computer-Vision-Pipelines prototypen. Bevor du Python schreibst, teste wie YOLO auf deinen spezifischen Bildern performt. Exportiere die JSON-Erkennungen und füttere sie in deine Pipeline. Der Objekt-Detektor lässt dich Konfidenzschwellen anpassen und sowohl annotierte PNGs als auch strukturiertes JSON exportieren.
Barrierefreiheits-Metadaten generieren. Führe Erkennung auf Produktbildern aus, um beschreibenden Alt-Text zu produzieren. "Bild enthält: 2 Personen, 1 Laptop, 1 Kaffeetasse" schlägt ein leeres alt-Attribut. Die Web Accessibility Initiative des W3C empfiehlt das für alle informativen Bilder.
Qualitätskontrolle vom Tablet. Fertigungsteams können Fehlererkennung auf Produktfotos im Browser ausführen. Keine dedizierte Hardware. Keine Cloud-Abhängigkeit.
Der Konfidenzschwellenwert
Jede Erkennung hat einen Score zwischen 0 und 1. Der Schwellenwert steuert, was du siehst:
- 0.3: Mehr Erkennungen, mehr Rauschen. Gut zum Erkunden, was das Modell findet.
- 0.7: Weniger Erkennungen, hohe Präzision. Gut für den Produktiveinsatz.
- 0.5: Vernünftige Balance für die meisten Fälle.
Das ist der Precision-vs-Recall-Trade-off. Stanfords CS231n erklärt das mAP-Framework zur Bewertung von Detektoren im Detail.
Ehrliche Grenzen
Browser-Inferenz ersetzt nicht alles. Die Einschränkungen:
Geschwindigkeit. Eine dedizierte GPU führt YOLOv8 in 5-10ms aus. Ein Browser braucht 100-500ms pro Bild. Reicht für Einzelbilder; zu langsam für Echtzeit-Video bei 30 FPS.
Modellgröße. YOLO-Gewichte sind 20-50MB. Der erste Ladevorgang erfordert den Download. Danach kümmert sich der Browser-Cache darum.
Feste Kategorien. Das COCO-Modell kennt 80 Klassen. Benutzerdefinierte Objekte (spezifische Maschinenteile, seltene Arten) brauchen feinabgestimmte Modelle. Du kannst dein eigenes ONNX-Modell mitbringen, aber das Training erfordert weiterhin eine GPU anderswo.
Mobil. Telefone haben schwächere GPUs. Rechne mit 2-3 Sekunden pro Erkennung auf Mittelklasse-Hardware.
Nichts davon ist ein Ausschlusskriterium für den Hauptanwendungsfall: schnelle, private Objekterkennung zum Nulltarif.
Der Kreis schließt sich
2018 schrieb ich "die niedrigen Serverkosten, weil all diese Berechnungen clientseitig stattfinden." Dieser Satz beschreibt genau, was der Objekt-Detektor tut. Lade ein YOLO-Modell im Browser, lade ein Bild hoch, erhalte Erkennungen. Keine Anmeldung, kein API-Key, kein Upload auf irgendjemandes Server.
Die Technologie ist gereift. Das Prinzip hat sich nie geändert.
Läuft auf ONNX Runtime Web, trainiert auf COCO (80 Kategorien). Architektur: YOLO von Ultralytics. Wenn du die Grundlagen verstehen willst, fang mit meinem TensorFlow.js-Post von 2018 an.