
Es gibt drei Wege, eine JSON-Antwort in TypeScript-Interfaces zu verwandeln. Man kann sie von Hand schreiben, ein LLM fragen, oder das JSON durch einen deterministischen Konverter laufen lassen. Ich habe alle drei benutzt. Zwei davon haben Fehlermodi, an die die meisten nicht denken, bis sie einen Bug deployen.
Der manuelle Ansatz: langsam und präzise, bis er es nicht mehr ist
Interfaces von Hand schreiben funktioniert bei drei Feldern. Ab Feld fuenfzehn hoert es auf zu funktionieren. Ein Stripe-Charge-Objekt hat über 40 Properties. Eine GitHub-Pull-Request-Antwort kommt auf über 100 Felder, wenn man verschachtelte Objekte mitzaehlt. Niemand tippt die von Hand ohne Fehler zu machen.
Der Fehlermodus ist subtil. Man oeffnet die API-Doku, faengt an zu schreiben, und ab Feld zwanzig überfliegt man nur noch. War merged_at ein String oder ein Date? Ist labels ein Array von Objekten oder Strings? Man raet, macht weiter, und der TypeScript-Compiler vertraut dem, was man geschrieben hat. Das Typsystem faengt nur Fehler, wenn die Typen von vornherein korrekt sind.
Die TypeScript-Dokumentation sagt es deutlich: any deaktiviert die Typüberpruefung für diesen Wert. Aber ein falsches Interface ist wohl schlimmer als any, weil es falsches Vertrauen gibt. Die IDE vervollständigt Felder, die nicht existieren. Der Code kompiliert. Der Crash passiert zur Laufzeit.
Der LLM-Ansatz: schnell und probabilistisch
Einen JSON-Block in ChatGPT oder Claude einfuegen und nach TypeScript-Interfaces fragen ist verlockend. Es ist schnell. Es handhabt Verschachtelung. Es benennt Interfaces sogar meistens vernuenftig.
Das Problem ist, dass LLMs probabilistisch sind. Gib demselben Modell denselben JSON zweimal und du koenntest unterschiedliche Ausgaben bekommen. Manchmal fuegt es ? zu Feldern hinzu, die nicht optional sind. Manchmal erfindet es einen Union-Typ, der nicht zu den Daten passt. Manchmal entscheidet es, dass id ein string sein sollte, obwohl der Wert eindeutig 1 ist. Ich habe gesehen, wie Modelle Date für ISO-Timestamp-Strings produzieren; technisch ambitioniert, aber falsch, wenn man den String nicht zuerst in ein Date-Objekt parst.
Das sind keine Bugs im Modell. Es ist die Natur des Werkzeugs. Ein LLM generiert plausiblen Text basierend auf Mustern. Es parst dein JSON nicht so, wie es ein Typsystem tut. Es liest es, approximiert was die Typen sein sollten, und schreibt etwas, das richtig aussieht. Meistens stimmt es. Aber "meistens richtig" und "deterministisch korrekt" sind verschiedene Dinge, wenn deine Typdefinitionen das Laufzeitverhalten schützen.
Da ist auch der Datenschutz-Aspekt. Eine Produktions-API-Antwort in ein Drittanbieter-LLM einzufuegen bedeutet, deine Daten an den Server von jemand anderem zu senden. Wenn diese Antwort Benutzer-PII, interne Endpoints oder Auth-Tokens enthält, die in den Payload gelangt sind, hast du sie gerade mit einem externen Service geteilt. Für Nebenprojekte ist das egal. Für Produktions-Codebases mit Compliance-Anforderungen ist das ein Gespräch mit deinem Sicherheitsteam, das du nicht führen willst.
Der deterministische Ansatz: gleiche Eingabe, gleiche Ausgabe, jedes Mal
Ein deterministischer JSON-zu-TypeScript-Konverter raet nicht. Er parst. Der Algorithmus durchläuft den JSON-Baum, inspiziert den JavaScript-Typ jedes Werts und mappt ihn auf den entsprechenden TypeScript-Typ. Kein Zufall, kein Temperature-Parameter, kein Modell, das sich donnerstags anders verhalten könnte.
Die Regeln sind mechanisch:
"hello"ist immerstring. Nicht manchmalstring, nicht gelegentlich"hello"als Literal-Typ.42ist immernumber. Nichtint, nichtfloat, nichtnumber | string.[1, 2, 3]ist immernumber[]. NichtArray<number>, nichtnumber[] | undefined.{"a": 1}generiert immer ein separates benanntes Interface mita: number.nullist immernull. Nichtundefined, nicht ausgelassen.
Gleicher JSON rein, gleiches TypeScript raus. Fuehre es hundertmal aus und du bekommst hundert identische Ergebnisse. Das ist die Eigenschaft, die du von einem Tool willst, das Typdefinitionen generiert, denen dein Compiler vertraut.
Was der Algorithmus wirklich tut
Unter der Haube macht der Konverter einen rekursiven Abstieg durch deine JSON-Struktur. Für jeden Wert, den er findet, ruft er inferType() auf, das den TypeScript-Typ-String zurückgibt. Objekte erzeugen neue Interface-Eintraege in einer Map. Arrays inspizieren ihre Elemente und produzieren entweder einen einheitlichen Typ (string[]) oder einen Union-Typ ((string | number)[]). Leere Arrays werden zu unknown[], weil es kein Element zum Inferieren gibt.
Property-Namen werden in PascalCase für Interface-Namen konvertiert. Keys, die keine gueltigen JavaScript-Identifier sind (Bindestriche, Leerzeichen, führende Ziffern), werden automatisch in Anfuehrungszeichen gesetzt. Die Ausgabe kann zwischen interface- und type-Deklarationen umgeschaltet werden.
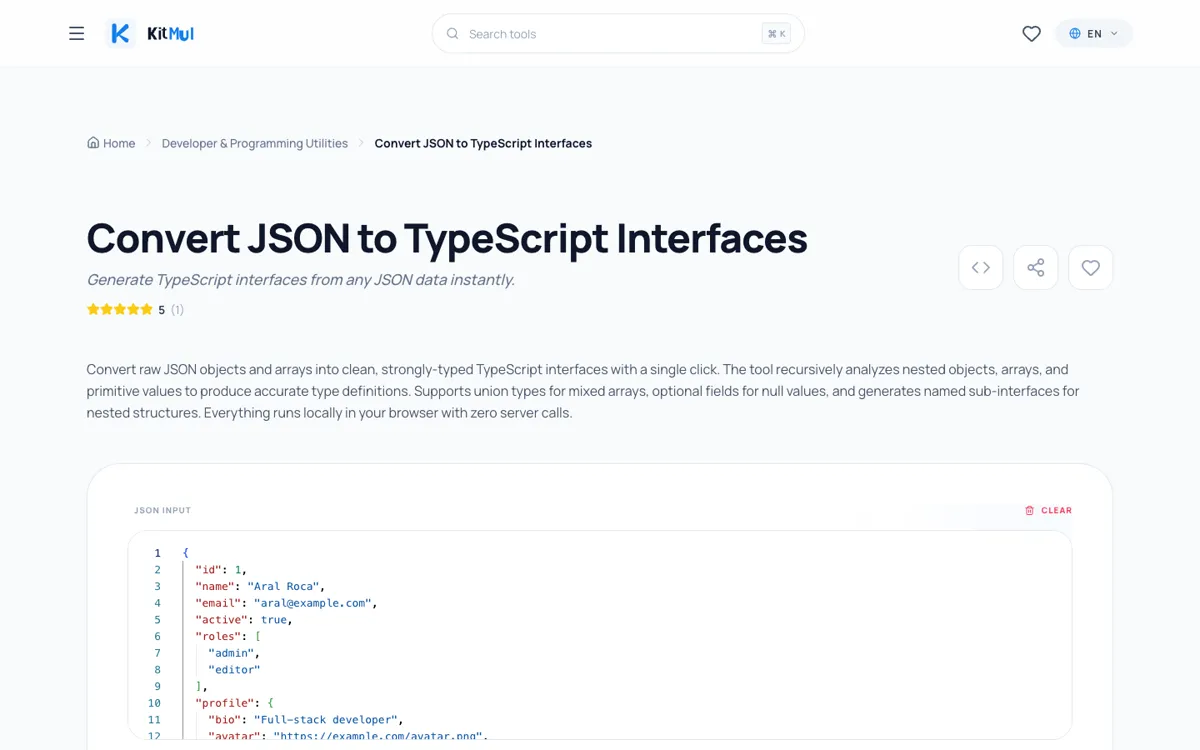
Ein konkretes Beispiel. Dieses JSON:
{
"id": 1,
"name": "Aral Roca",
"email": "aral@example.com",
"active": true,
"roles": ["admin", "editor"],
"profile": {
"bio": "Full-stack developer",
"avatar": "https://example.com/avatar.png",
"social": {
"github": "aralroca",
"twitter": "aralroca"
}
},
"posts": [
{
"id": 101,
"title": "Understanding TypeScript Interfaces",
"published": true,
"tags": ["typescript", "tutorial"]
}
],
"createdAt": "2026-04-27T10:00:00Z"
}
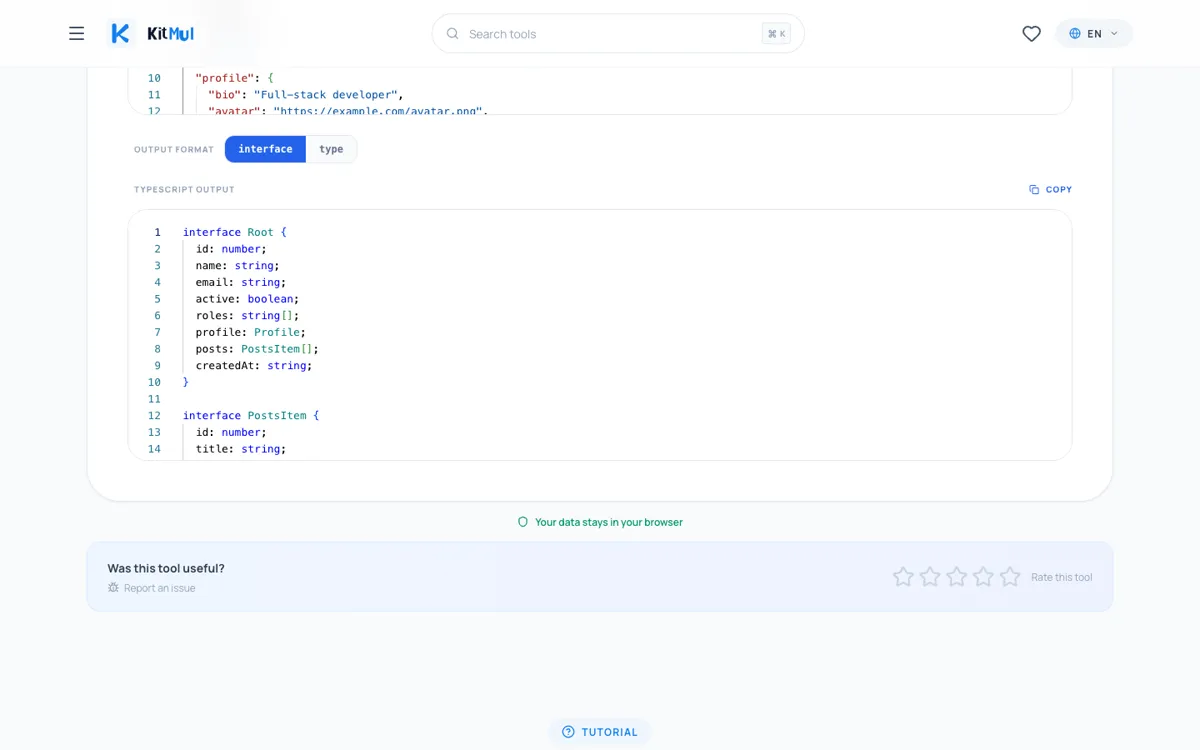
Produziert genau dies:
interface Root {
id: number;
name: string;
email: string;
active: boolean;
roles: string[];
profile: Profile;
posts: PostsItem[];
createdAt: string;
}
interface Profile {
bio: string;
avatar: string;
social: Social;
}
interface Social {
github: string;
twitter: string;
}
interface PostsItem {
id: number;
title: string;
published: boolean;
tags: string[];
}
Vier Interfaces. Jedes Feld korrekt getypt. Jedes verschachtelte Objekt in sein eigenes benanntes Interface extrahiert. Kein Zufall beteiligt.
Interface vs. type: wann der Toggle zaehlt
Der Konverter bietet sowohl interface- als auch type-Ausgabe. Die Wahl ist nicht kosmetisch.
Interfaces unterstützen Declaration Merging; wenn zwei Interfaces denselben Namen im selben Scope teilen, fusioniert TypeScript ihre Properties. Types nicht. Für Bibliotheksautoren, die wollen, dass Konsumenten Typen erweitern, sind Interfaces die bessere Wahl.
Types handhaben Unions, Intersections und Mapped Types natuerlicher. Wenn du type Result = Success | Error brauchst oder Shapes mit & komponieren willst, spart die type-Ausgabe einen Schritt.
Für API-Response-Typing spielt es selten eine Rolle. Waehle, was die Linting-Regeln deines Teams durchsetzen, und mach weiter.
Wo deterministische Inferenz noch menschliche Prüfung braucht
Der Konverter inferiert Typen aus Werten, nicht aus Schemas. Das ist ein Feature; es funktioniert mit jedem JSON ohne eine OpenAPI-Spec oder ein JSON Schema zu benoetigen. Aber es bedeutet, dass es Randfaelle gibt, bei denen du anpassen willst:
Optionale Felder. Der Konverter sieht nur das Sample, das du bereitstellst. Wenn ein Feld manchmal in der Antwort fehlt, fuege ? manuell hinzu.
String-Enums. "status": "active" wird zu string, nicht zu "active" | "inactive" | "suspended". Schraenke es selbst ein.
Datum-Strings. ISO 8601 Timestamps wie "2026-04-27T10:00:00Z" sind string für den Konverter. Wenn du sie mit date-fns oder dayjs parst, willst du sie in deinen finalen Typen zu Date ändern.
Paginierungs-Wrapper. Eine Antwort wie { data: [...], meta: { page: 1, total: 100 } } generiert ein Root-Interface mit beidem. Benenne es in PaginatedResponse<T> um und extrahiere Meta als Generikum.
Diese Anpassungen dauern Sekunden. Der Punkt ist, dass der deterministische Konverter dir eine korrekte Baseline gibt; die Teile, die menschliches Urteil brauchen, sind dieselben Teile, die eine Maschine genuinerweise nicht aus einem einzelnen Sample inferieren kann. Ein LLM würde diese auch falsch machen; der Unterschied ist, dass das LLM zusaetzlich die einfachen Teile falsch machen könnte.
Datenschutz als Feature, nicht als Marketing-Slogan
Der Konverter läuft vollständig clientseitig. Das JSON verlässt niemals deinen Browser. Kein Server-Call, keine Analytik über deine Eingabe, kein Konto.
Das ist kein abstrakter Vorteil. Viele Teams haben Sicherheitsrichtlinien, die das Hochladen von Quellcode oder API-Antworten zu Drittanbieter-Diensten verbieten. Das schliesst die meisten Online-Tools aus. Das schliesst das Einfuegen von Produktions-Antworten in LLM-Chatbots aus. Ein clientseitiger Konverter, der alles in einer JavaScript-Funktion auf deiner Maschine verarbeitet, hat null Compliance-Oberflaeche.
Oeffne den Netzwerk-Tab deines Browsers während der Nutzung. Du wirst nichts Gesendetes sehen.
Ein praktischer Workflow
1. Eine echte Antwort holen. Benutze curl, Postman oder den Netzwerk-Tab deines Browsers, um eine echte API-Antwort zu erfassen.
2. Einfuegen und konvertieren. Oeffne den JSON-zu-TypeScript-Konverter, fuege das JSON ein, kopiere die Ausgabe.
3. Umbenennen und verfeinern. Aendere Root zu UserResponse. Fuege ? hinzu, wo noetig. Schraenke String-Unions ein.
4. Mit dem API-Client co-lokalisieren. Ich lege Typen in eine types.ts neben die Datei, die den fetch- oder axios-Call macht.
5. Runtime-Validierung hinzufuegen. Benutze Zod oder Valibot, um zu validieren, dass die API tatsächlich sendet, was deine Typen beschreiben. Der Konverter gibt dir Struktur; eine Schema-Bibliothek gibt dir Runtime-Garantien.
Das Ganze dauert weniger als eine Minute pro Endpoint.
Über API-Antworten hinaus
Der Konverter verarbeitet jedes gueltige JSON:
- Konfigurationsdateien. Fuege
tsconfig.jsonoderpackage.jsonein für type-sichere Konfigurationsladung. - Datenbank-Exporte. Ein MongoDB-Dokument oder eine PostgreSQL-Zeile als JSON wird zu deinen ORM-Schicht-Typen.
- Test-Fixtures. Wenn du Tests mit Jest oder Vitest schreibst, stellt das Konvertieren von Fixture-Dateien sicher, dass deine Mocks den Produktionsformen entsprechen.
- CMS-Inhalte. Headless-CMS-Antworten von Strapi, Sanity oder Contentful sind tief verschachtelt. Type sie einmal; lass den Compiler Template-Bugs fangen.
Zum Formatieren von JSON vor dem Konvertieren übernimmt der JSON-Formatierer Pretty-Printing und Validierung. Für die entgegengesetzte Richtung; HTML in etwas bereinigen, das ein LLM effizient verarbeiten kann; gibt es den HTML-zu-Markdown-Konverter.
Die Tradeoff-Matrix
| Manuell | LLM | Deterministisch | |
|---|---|---|---|
| Geschwindigkeit | Langsam | Schnell | Schnell |
| Korrektheit | Haengt von dir ab | Meistens korrekt | Immer korrekt für das Sample |
| Konsistenz | Variabel | Nicht-deterministisch | Identisch jedes Mal |
| Datenschutz | N/A | Daten an Server gesendet | Nur clientseitig |
| Optionale Felder | Du entscheidest | Raet manchmal | Du entscheidest |
| String-Einschraenkung | Du entscheidest | Raet manchmal | Du entscheidest |
Der deterministische Konverter übernimmt den mechanischen Teil; Werte auf Typen mappen; perfekt. Die Teile, die er nicht handhaben kann (Optionalitaet, String-Enums, Datum-Parsing), sind dieselben Teile, die die anderen Ansaetze auch nicht zuverlaessig handhaben. Der Unterschied ist, dass er keine neuen Fehler bei den Teilen einführt, die er handhaben kann.
Das Fazit
Typsicherheit ist kein Spektrum. Deine Typen sind entweder korrekt oder sie sind es nicht. Manuelles Tippen ist langsam und fehleranfällig im großen Massstab. LLM-Tippen ist schnell aber probabilistisch. Deterministische Konvertierung ist schnell und korrekt; innerhalb der Grenzen dessen, was jedes Tool aus einem einzelnen JSON-Sample inferieren kann.
Benutze den JSON-zu-TypeScript-Konverter für die mechanische Arbeit. Setze dein Urteilsvermoegen für optionale Felder, String-Unions und Interface-Benennung ein; die Entscheidungen, die Kontext erfordern, den kein Tool hat.
Keine Anmeldung. Kein Upload. Gleiche Eingabe, gleiche Ausgabe. Teil der Entwickler- und Programmier-Utilities auf Kitmul.
Foto von Florian Olivo auf Unsplash.