
Wir haben ein Feature an einem Dienstag ausgeliefert. Am Donnerstag lief die API in Timeouts. Das Monitoring-Dashboard zeigte, wie die p99-Latenz innerhalb von 48 Stunden von 80ms auf 14 Sekunden kletterte. Nichts hatte sich geändert; nur die Anzahl der Nutzer.
Der Übeltäter waren drei Zeilen Code, die beim Review völlig harmlos aussahen:
const results = users.map(user => {
const match = permissions.find(p => p.userId === user.id);
return { ...user, role: match?.role ?? 'viewer' };
});
Sauber. Lesbar. Funktionaler Stil. Aber auch O(n * m), was in unserem Fall O(n^2) bedeutete, weil Nutzer und Berechtigungen gleich schnell wuchsen. Bei 200 Nutzern: 40.000 Vergleiche. Bei 2.000 Nutzern: 4.000.000. Bei 20.000 Nutzern: 400.000.000. Die Lösung war ein Einzeiler; zuerst eine Map bauen:
const permMap = new Map(permissions.map(p => [p.userId, p.role]));
const results = users.map(user => ({
...user,
role: permMap.get(user.id) ?? 'viewer',
}));
O(n + m) statt O(n * m). Problem gelöst. Aber die eigentliche Frage ist: Warum hat das niemand bemerkt?
Die O(n^2)-Falle versteckt sich direkt vor deinen Augen
Quadratische Komplexität ist die gefährlichste Performance-Klasse in Produktionssoftware. Nicht weil sie die langsamste ist; O(2^n) und O(n!) sind weitaus schlimmer. Sondern weil sie normal aussieht. Sie übersteht Code Reviews. Sie funktioniert in der Entwicklung. Sie funktioniert sogar im Staging, wenn dein Testdatensatz klein genug ist. Dann trifft sie auf Produktion mit echten Datenmengen und alles bricht zusammen.
Das Muster ist fast immer dasselbe: eine Suchoperation verschachtelt in einer Iteration. Array.prototype.find(), Array.prototype.includes(), Array.prototype.indexOf(); das sind alles O(n)-Operationen. Packe sie in eine Schleife und du hast O(n^2). Packe sie in zwei verschachtelte Schleifen und du hast O(n^3). Die ausdrucksstarken Array-Methoden von JavaScript machen es besonders leicht, das zu übersehen, weil der Code sich wie natürliche Sprache liest statt wie verschachtelte for-Schleifen auszusehen.
Hier sind fünf echte Muster, die ich Produktionssysteme zum Absturz bringen sehen habe.
Muster 1: Das harmlose .includes() in .filter()
// Looks clean, but O(n * m)
const activeUsers = allUsers.filter(u => activeIds.includes(u.id));
Wenn activeIds ein Array mit 10.000 Einträgen ist und allUsers 50.000 Einträge hat, machst du 500.000.000 Vergleiche. Wandle activeIds in ein Set um und es sinkt auf 50.000:
const activeSet = new Set(activeIds);
const activeUsers = allUsers.filter(u => activeSet.has(u.id));
Set.has() ist O(1). Diese eine Änderung bringt dich von O(n * m) auf O(n + m).
Muster 2: Deduplizierung durch Vergleich
// O(n^2) deduplication
const unique = items.filter((item, i) =>
items.findIndex(x => x.id === item.id) === i
);
Ich sehe dieses Muster wöchentlich in Code Reviews. Der findIndex durchsucht für jedes Element das Array von Anfang an. Bei 10.000 Elementen sind das bis zu 100 Millionen Vergleiche. Die Lösung:
const seen = new Set();
const unique = items.filter(item => {
if (seen.has(item.id)) return false;
seen.add(item.id);
return true;
});
Oder noch einfacher mit einer Map, wenn du die vollständigen Objekte brauchst:
const unique = [...new Map(items.map(i => [i.id, i])).values()];
Muster 3: Die kaskadierende .map().filter().map()-Kette
Dieses Muster ist subtil. Jede einzelne Methode ist O(n), und drei O(n)-Operationen zu verketten ergibt immer noch O(n); 3n ist nur n mit einem konstanten Faktor. Aber es wird O(n^2), wenn eine dieser Operationen eine Suche versteckt:
const enriched = orders
.map(order => ({
...order,
customer: customers.find(c => c.id === order.customerId), // O(n) inside O(n)
}))
.filter(order => order.customer?.active)
.map(order => formatForDisplay(order));
Die funktionale Pipeline sieht elegant aus. Das verschachtelte .find() macht sie quadratisch. Eine vorbereitete Lookup-Tabelle behebt das Problem ohne Einbußen bei der Lesbarkeit.
Muster 4: Der rekursive Baum-Flattener
function flattenComments(comments) {
return comments.reduce((flat, comment) => {
flat.push(comment);
if (comment.replies) {
flat.push(...flattenComments(comment.replies));
}
return flat;
}, []);
}
Der Spread-Operator innerhalb von reduce erzeugt bei jedem rekursiven Aufruf ein neues Array. Für einen balancierten Baum mit n Knoten ist das O(n^2) wegen des Array-Kopierens. Die Lösung ist flat.push(...result) oder den Akkumulator durchzureichen:
function flattenComments(comments, result = []) {
for (const comment of comments) {
result.push(comment);
if (comment.replies) flattenComments(comment.replies, result);
}
return result;
}
Muster 5: Die SQL-Abfrage in der Schleife (das N+1-Problem)
Dieses Muster ist nicht JavaScript-spezifisch. Es ist das häufigste Performance-Antimuster in Webanwendungen:
const orders = await db.query('SELECT * FROM orders WHERE status = ?', ['active']);
for (const order of orders) {
order.items = await db.query('SELECT * FROM order_items WHERE order_id = ?', [order.id]);
}
1 Abfrage für Bestellungen + n Abfragen für Positionen = n+1 Abfragen insgesamt. Bei 1.000 Bestellungen sind das 1.001 Datenbank-Roundtrips. Das N+1-Abfrageproblem ist gut dokumentiert, taucht aber immer wieder auf, weil ORMs es durch Lazy Loading leicht machen, es versehentlich auszulösen.
Die Lösung ist ein JOIN oder eine Batch-Abfrage:
const orders = await db.query('SELECT * FROM orders WHERE status = ?', ['active']);
const orderIds = orders.map(o => o.id);
const items = await db.query('SELECT * FROM order_items WHERE order_id IN (?)', [orderIds]);

Wie du quadratische Komplexität erkennst, bevor es die Produktion tut
1. Profiliere mit realistischen Datenmengen. Wenn deine Testsuite mit 10 Datensätzen läuft und die Produktion 100.000 hat, messen deine Tests nichts Brauchbares. Erstelle Benchmark-Fixtures, die der Produktionsgröße entsprechen. Der Unterschied zwischen O(n) und O(n^2) ist bei n=10 unsichtbar und bei n=10.000 katastrophal.
2. Suche nach .find(), .includes(), .indexOf() innerhalb von .map(), .filter(), .reduce(). Diese mechanische Prüfung fängt die Mehrheit der versehentlichen quadratischen Muster in JavaScript-Codebasen ab. Wenn du sehen willst, wie dramatisch unterschiedlich sich Komplexitätsklassen skalieren, gib die Zahlen in einen Big-O-Komplexitätsvergleicher ein; er plottet jede Klasse von O(1) bis O(n!) in einem Diagramm.
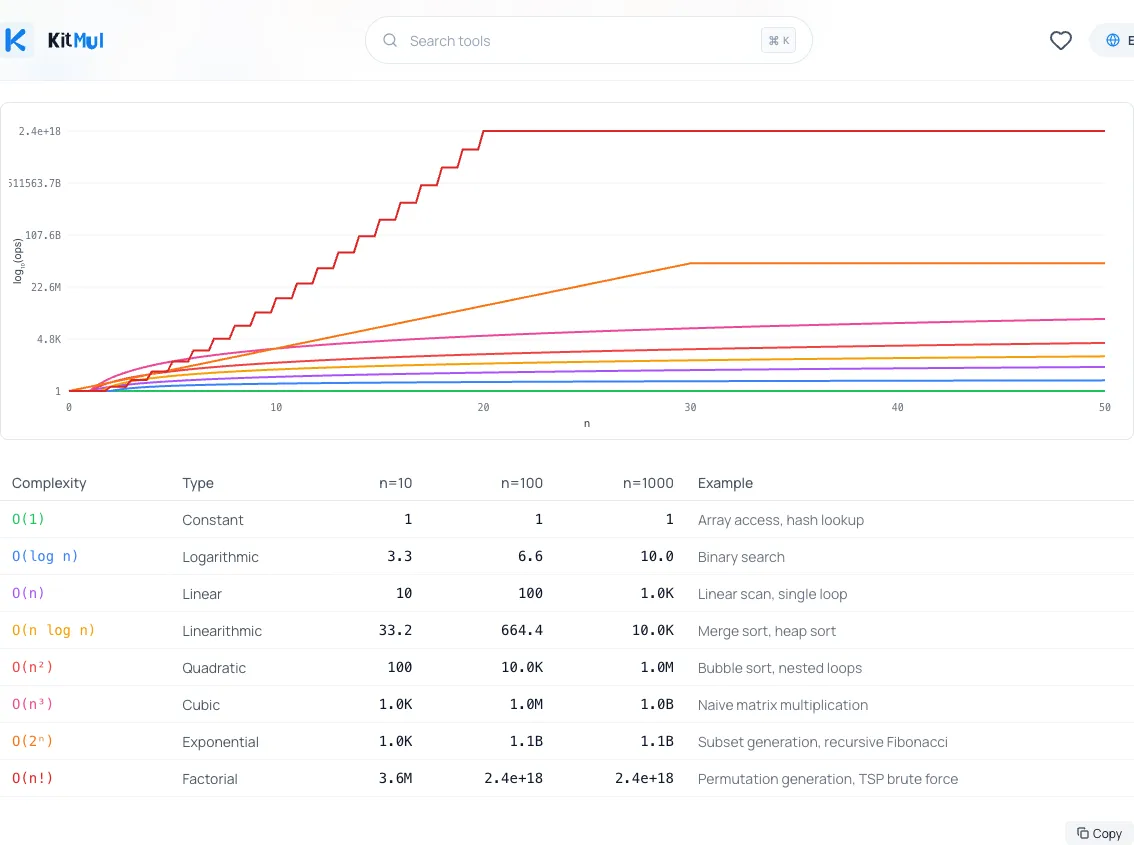
3. Füge Komplexitäts-Anmerkungen zu Code Reviews hinzu. Frage beim Reviewen: Was ist n? Wie groß kann es werden? Was ist die Komplexität der inneren Operation? Das explizit zu machen verhindert die "funktioniert doch in der Entwicklung"-Überraschung.
4. Setze Latenz-Budgets mit Alerts. Wenn die p95-Latenz eines Endpoints 500ms überschreitet, alarmiere jemanden. Quadratische Komplexität zeigt sich typischerweise als schleichende Verschlechterung, nicht als plötzlicher Ausfall; perfekt für latenzbasierte Alerts, die den Trend erkennen, bevor Nutzer es bemerken.
5. Kenne deine Standardbibliothek. Array.sort() ist O(n log n). Set.has() ist O(1). Array.includes() ist O(n). Map.get() ist O(1). Der Unterschied zwischen einer Array-Methode und einer Map/Set-Methode ist oft der Unterschied zwischen O(n^2) und O(n). Die MDN Web Docs zu Keyed Collections erklären, wann du welche verwenden solltest.
Die eigentliche Lektion
Das Gefährliche an O(n^2) ist nicht, dass es langsam ist. Es ist, dass es unsichtbar bleibt, bis es das nicht mehr ist. Jedes der oben gezeigten Muster hat Code Reviews bestanden, weil der Code lesbar, idiomatisch und korrekt war. Er skalierte nur nicht.
Performance-Komplexität ist nichts, wofür du später optimierst. Es ist eine Design-Entscheidung, die du beim Schreiben des Codes triffst. Die Frage ist nicht "funktioniert das?" sondern "funktioniert das auch, wenn n 100-mal so groß ist wie in meinen Tests?"
Untersuchungen von Google zeigen konsistent, dass jede zusätzliche 100ms Latenz messbare Geschäftsmetriken kostet. Ein quadratischer Algorithmus, der bei deiner aktuellen Skalierung 50ms und bei der Skalierung nächstes Jahr 5.000ms hinzufügt, ist eine tickende Zeitbombe.
Gewöhne dir an, standardmäßig zu Map und Set zu greifen. Hinterfrage jedes .find() und .includes() in einer Schleife. Profiliere mit produktionsgroßen Daten. Der Code, der deine App zum Absturz bringt, wird nicht gefährlich aussehen; genau das macht ihn gefährlich.
Tiefer eintauchen
Für eine vollständige Referenz zu allen acht Komplexitätsklassen mit interaktiven Diagrammen, ausführbarem Code und Interview-Mustern lies den Vollständigen Leitfaden zur Big-O-Komplexität.
Datenschutz: Alle Kitmul-Tools laufen vollständig in deinem Browser. Es werden keine Daten an einen Server gesendet. Kein Konto erforderlich. Kein Tracking über grundlegende Analysen hinaus.