
Mein erstes Algorithmus-Interview habe ich vermasselt, weil ich "kommt drauf an" geantwortet habe, als man mich nach der Zeitkomplexitat einer Suchfunktion fragte. Der Interviewer wollte O(log n) hören. Ich wusste, dass es eine Binary Search war. Ich wusste sogar, dass sie logarithmisch ist. Aber ich geriet in Panik und fing an, über Cache Lines, Branch Prediction und die Frage zu reden, ob das Array in L1 passt. Die Augen des Interviewers würden glasig. "Kommt drauf an" ist technisch korrekt und praktisch nutzlos, wenn jemand wissen will, ob deine Lösung noch funktioniert, wenn der Input von 1.000 auf 1.000.000 waechst.
Dieses Interview hat mich etwas gelehrt, das Jahre brauchte, um es vollständig zu verinnerlichen: Big-O-Notation dreht sich nicht um Praezision. Es geht um die Form des Wachstums. Sie sagt dir, wie sich ein Algorithmus verhaelt, wenn der Input gross wird; nicht die exakte Anzahl der Operationen, nicht die tatsächliche Laufzeit, sondern die Kurve.
Und sobald man die Kurven sieht, macht alles Klick.
Warum Big O auch außerhalb von Interviews wichtig ist
Ich sage es direkt: Die meisten arbeitenden Programmierer, die ich kenne, haben Big O für Interviews gelernt und es danach sofort wieder vergessen. Das ist ein Fehler.
Letztes Jahr hatte ich einen Produktionsservice, der mit 500 Nutzern einwandfrei funktionierte und bei 5.000 zusammenbrach. Der Uebeltaeter war eine verschachtelte Schleife, über die beim Code Review niemand zweimal nachdachte. Zwei .filter()-Aufrufe innerhalb eines .map(). Sah sauber aus. Las sich wunderbar. War O(n^3). Bei 500 Elementen lief es in 120ms. Bei 5.000 Elementen; 12 Sekunden. Bei 50.000 Elementen haette es 20 Minuten gedauert.
Zeitkomplexitaet ist der Unterschied zwischen "funktioniert auf meinem Rechner" und "funktioniert in Produktion". Sie ist der Grund, warum manche Systeme elegant skalieren und andere an eine Wand fahren. Das ist nicht akademisch. Es ist das Praktischste in der gesamten Informatik.
Die acht Komplexitaetsklassen; echter Code, echte Konsequenzen
Lass mich jede Klasse mit tatsächlichem Code durchgehen, den du ausführen kannst. Ich verwende JavaScript, weil es sich für die meisten Entwickler wie Pseudocode liest, aber die Konzepte sind sprachunabhaengig.
O(1); konstante Zeit
function getFirst(arr) {
return arr[0];
}
Egal ob das Array 10 Elemente oder 10 Millionen hat. Eine Operation. Hash-Table-Lookups sind im Durchschnitt ebenfalls O(1); deshalb greifst du zu einer Map oder einem Objekt, wenn du schnellen Zugriff über einen Schlüssel brauchst. Der Teil "im Durchschnitt" ist wichtig (Hash-Kollisionen gibt es), aber in der Praxis ist das der Goldstandard.
O(log n); logarithmisch
function binarySearch(sorted, target) {
let lo = 0, hi = sorted.length - 1;
while (lo <= hi) {
const mid = Math.floor((lo + hi) / 2);
if (sorted[mid] === target) return mid;
if (sorted[mid] < target) lo = mid + 1;
else hi = mid - 1;
}
return -1;
}
Binary Search halbiert das Problem bei jedem Schritt. Eine Milliarde sortierte Elemente durchsuchen? Etwa 30 Vergleiche. Das ist die Magie der Logarithmen. Jedes Mal, wenn du den Input verdoppelst, kommt nur ein weiterer Schritt hinzu. Datenbankindizes funktionieren nach diesem Prinzip (B-Trees sind im Wesentlichen Mehrweg-Binary-Search).
O(n); linear
function findMax(arr) {
let max = arr[0];
for (const val of arr) {
if (val > max) max = val;
}
return max;
}
Jedes Element einmal anfassen. Doppelter Input, doppelte Zeit. Das ist oft das Beste, was du erreichen kannst, wenn du alle Daten untersuchen musst. Wenn dir jemand sagt, du sollst einen linearen Scan "optimieren", der wirklich jedes Element sehen muss, dann verlangt derjenige ein Wunder.
O(n log n); linearithmisch
Hier leben die effizienten Vergleichssortierungen. Merge Sort, Quicksort (Durchschnittsfall), Heapsort. Es gibt hier eine bewiesene untere Schranke; man kann n Elemente nicht durch Paarvergleiche in weniger als O(n log n) Vergleichen sortieren. Das ist eine mathematische Unmoglichkeit, bewiesen über Entscheidungsbaeume.
function mergeSort(arr) {
if (arr.length <= 1) return arr;
const mid = Math.floor(arr.length / 2);
const left = mergeSort(arr.slice(0, mid));
const right = mergeSort(arr.slice(mid));
return merge(left, right);
}
function merge(a, b) {
const result = [];
let i = 0, j = 0;
while (i < a.length && j < b.length) {
result.push(a[i] <= b[j] ? a[i++] : b[j++]);
}
return result.concat(a.slice(i), b.slice(j));
}
Die Zeitkomplexitaet von Merge Sort ist in allen Faellen O(n log n); Worst Case, Average Case und Best Case. Deshalb ist er in vielen Standardbibliotheken die Standard-Sortierung. Seine Speicherkomplexitaet ist allerdings O(n); man braucht dieses Hilfsarray. Überall Kompromisse.
O(n^2); quadratisch
function bubbleSort(arr) {
const n = arr.length;
for (let i = 0; i < n; i++) {
for (let j = 0; j < n - i - 1; j++) {
if (arr[j] > arr[j + 1]) {
[arr[j], arr[j + 1]] = [arr[j + 1], arr[j]];
}
}
}
return arr;
}
Zwei verschachtelte Schleifen über den Input. 1.000 Elemente bedeuten ~1.000.000 Operationen. 10.000 Elemente bedeuten ~100.000.000. Hier leben die "funktioniert in der Entwicklung einwandfrei"-Bugs. Das verschachtelte .filter() innerhalb von .map(), das ich vorhin erwaehnt habe? Eine klassische quadratische Falle, verkleidet in funktionaler Syntax.
O(2^n); exponentiell
function fibonacci(n) {
if (n <= 1) return n;
return fibonacci(n - 1) + fibonacci(n - 2);
}
Die naive rekursive Fibonacci-Berechnung. Jeder Aufruf verzweigt sich in zwei weitere. Bei n=30 macht man über eine Milliarde Funktionsaufrufe. Bei n=50 gibt dein Rechner auf. Die Lösung ist Memoization (wodurch es auf O(n) sinkt) oder ein iterativer Ansatz. Aber die naive Version ist das Paradebeispiel dafuer, warum exponentielle Algorithmen für alles jenseits winziger Inputs praktisch unbrauchbar sind.
O(n!); faktoriell
function permutations(arr) {
if (arr.length <= 1) return [arr];
const result = [];
for (let i = 0; i < arr.length; i++) {
const rest = [...arr.slice(0, i), ...arr.slice(i + 1)];
for (const perm of permutations(rest)) {
result.push([arr[i], ...perm]);
}
}
return result;
}
Alle Permutationen generieren. 10 Elemente = 3.628.800 Permutationen. 15 Elemente = über 1,3 Billionen. 20 Elemente = mehr als die Anzahl der Sekunden seit dem Urknall. Das Travelling-Salesman-Problem lebt hier (Brute Force). Deshalb sind NP-schwere Probleme schwer; wenn du eine effiziente Lösung für eines davon findest, hol dir deinen Millennium-Preis ab.
Die Kurven zu sehen macht es greifbar
Ich habe einen Big-O-Komplexitaetsvergleicher gebaut, weil das Starren auf Notation auf einer Seite den visceralen Unterschied zwischen diesen Klassen nicht vermittelt. Wenn man O(n), O(n log n) und O(n^2) im selben Diagramm plottet, schiesst die quadratische Kurve so aggressiv nach oben, dass die lineare im Vergleich flach aussieht. Und O(2^n) sowie O(n!) lassen O(n^2) flach erscheinen.
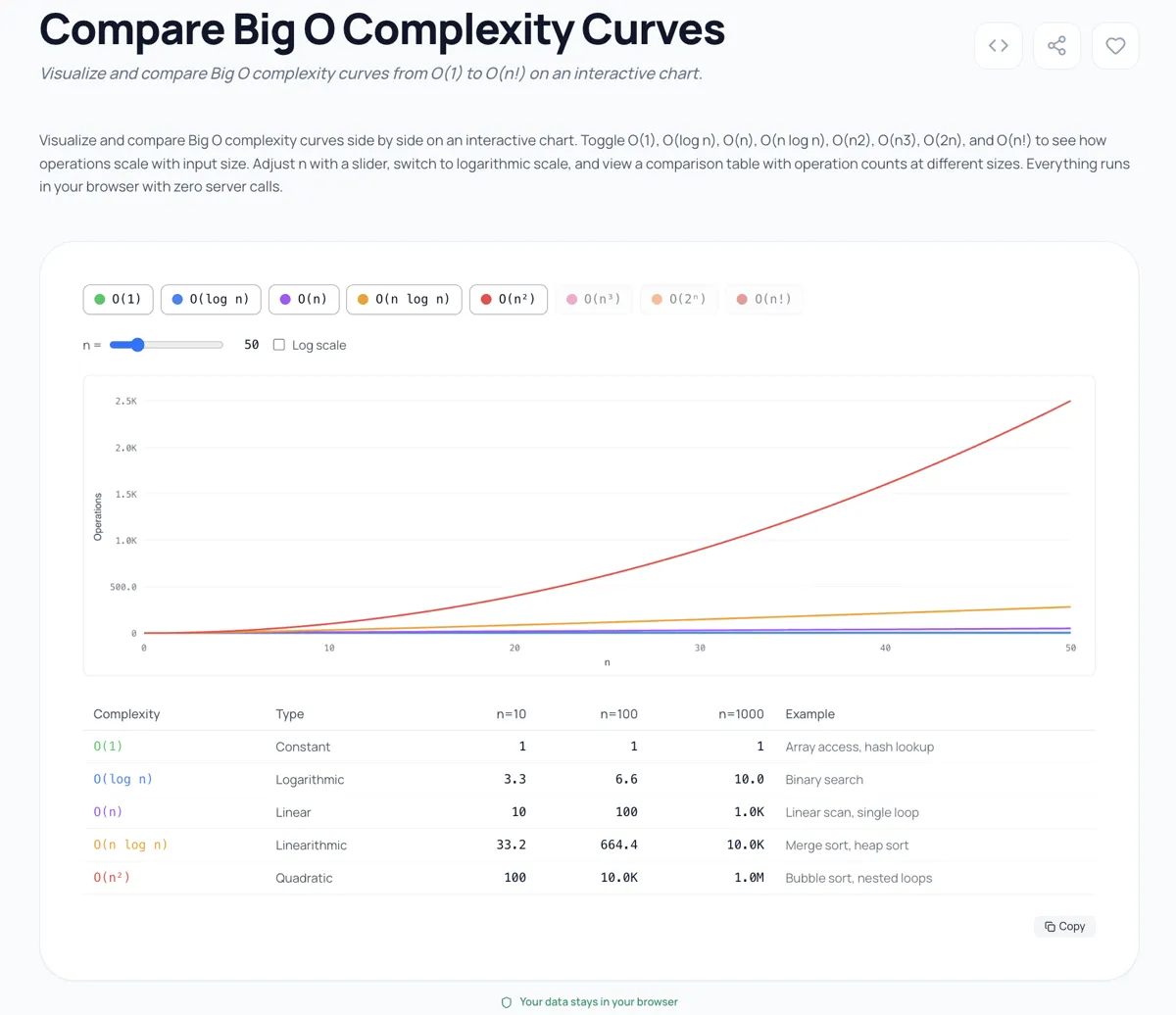
Das Tool plottet alle acht Klassen gleichzeitig auf einer logarithmischen Skala, damit du die Zusammenhaenge sehen kannst. Spiel mit dem Eingabegrößen-Slider und beobachte, was ab n=20 passiert. Die exponentiellen und faktoriellen Kurven verlassen das Diagramm vollständig. Das ist keine Übertreibung für den visuellen Effekt; das sind die tatsächlichen Werte. Bei n=25 beträgt O(n!) 15.511.210.043.330.985.984.000.000. Deine O(n^2)-Lösung sieht im Vergleich ploetzlich schnell aus.
Drei Dinge, die die meisten Leute bei Big O falsch verstehen
1. Konstanten spielen in der Praxis eine Rolle. Big O laesst Konstanten weg. O(2n) und O(n) sind beide "O(n)". Aber in echtem Code ist ein konstanter Faktor von 10x der Unterschied zwischen einer 100ms-Antwort und einer 1-Sekunde-Antwort. Ein Algorithmus mit einer engen inneren Schleife und guter Cache-Lokalitaet bei O(n log n) wird einen theoretisch aequivalenten O(n log n)-Algorithmus, der den Speicher strapaziert, deutlich schlagen. CLRS (die Algorithmen-Bibel; Introduction to Algorithms von Cormen, Leiserson, Rivest und Stein) erkennt das an; die "Konstantenfaktoren", die in Beweisen weggewischt werden, werden in der Produktion zu Engineering-Entscheidungen.
2. Amortisierte Komplexität ist nicht dasselbe wie durchschnittliche Komplexität. Wenn jemand sagt, ArrayList.add() ist amortisiert O(1), meint er damit, dass es gelegentlich O(n) ist (wenn eine Größenaenderung noetig ist), aber diese teuren Operationen so verteilt sind, dass über n Operationen hinweg die Gesamtkosten O(n) betragen. Das ist etwas anderes als zu sagen, der Durchschnittsfall sei O(1). Amortisiert ist eine Garantie über eine Sequenz; der Durchschnittsfall haengt von der Inputverteilung ab.
3. Speicherkomplexitaet ist genauso wichtig. Ich habe gesehen, wie Entwickler die Zeitkomplexitaet von O(n^2) auf O(n) optimiert und gefeiert haben; nur um festzustellen, dass ihre O(n)-Lösung O(n^2) Speicher verbraucht. Auf einem Server mit 4 GB RAM, der 10 Millionen Datensaetze verarbeitet, toetet dich die Speicherkomplexitaet schneller als die Zeitkomplexitaet. Stelle immer beide Fragen: Wie lange dauert es, und wie viel Speicher braucht es?
Wie du deinen eigenen Code analysierst
Hier ist meine Schritt-für-Schritt-Methode. Ich mache das jedes Mal, wenn ich Code reviewe, der Eingaben variabler Größe verarbeitet:
- Identifiziere den Input. Welche Variable bestimmt die Größe? Meistens ist es die Länge eines Arrays, die Anzahl der Zeilen, die Anzahl der Knoten.
- Finde die Schleifen. Jede Schleife, die über den Input iteriert, trägt mindestens O(n) bei. Verschachtelte Schleifen multiplizieren sich.
- Achte auf versteckte Schleifen. Array-Methoden wie
.filter(),.map(),.indexOf(),.includes()sind alle O(n). Drei davon zu verketten ist immer noch O(n); eine innerhalb einer anderen zu verschachteln ist O(n^2). - Pruefe rekursive Aufrufe. Wie oft ruft sich die Funktion selbst auf? Binaere Rekursion (zwei Aufrufe) ist ohne Memoization O(2^n). Wenn die Rekursion das Problem jedes Mal halbiert, ist es O(log n).
- Beruecksichtige eingebaute Operationen.
Array.sort()ist O(n log n).Set.has()ist O(1).Array.includes()ist O(n). Kenne deine Standardbibliothek.

Interview-Vorbereitung; fuenf Muster, die 80% der Fragen abdecken
Nach etwa 200 Coding-Interviews (auf beiden Seiten des Tisches) ist hier mein Big-O-Spickzettel für die Muster, die ständig auftauchen:
1. Hash Map, um eine verschachtelte Schleife zu eliminieren. Wenn dein Brute-Force-Ansatz O(n^2) ist, weil du in einer inneren Schleife nach einem Komplement/Match suchst, macht eine Hash Map daraus O(n). Klassisches Beispiel: Two Sum.
2. Zuerst sortieren, dann Binary Search oder Two Pointers verwenden. Sortieren kostet O(n log n) im Voraus, ermöglicht aber O(log n)-Lookups. Gesamt: O(n log n). Fast immer besser als O(n^2) Brute Force.
3. Sliding Window für Subarray-/Substring-Probleme. Verwandelt O(n^2) oder O(n^3) Brute Force in O(n), indem ein Fenster beibehalten wird, das durch die Daten wandert. Maximum Subarray, laengster Substring ohne Wiederholungen; alles Sliding Window.
4. Divide and Conquer für O(n log n). Problem aufteilen, Haelften rekursiv lösen, zusammenfuegen. Merge Sort ist das Lehrbuchbeispiel, aber es taucht auch bei naechstem Punktepaar, Inversionen zaehlen und Matrixmultiplikation auf.
5. Dynamic Programming, um exponentielle Rekursion zu beseitigen. Überlappende Teilprobleme memoisieren, um O(2^n) auf O(n) oder O(n^2) zu reduzieren. Fibonacci, Coin Change, Longest Common Subsequence. Wenn du überlappende Teilprobleme und optimale Teilstruktur siehst, greif zu DP.
Diese fuenf Muster decken nicht alles ab, aber genug, um die meisten Algorithmus-Interviews zu bestehen. Für einen tieferen Einblick empfehle ich ehrlich, Aufgaben mit einem visuellen Komplexitaetsvergleicher offen durchzuarbeiten. Zu sehen, wo deine Lösung auf der Kurve liegt, baut Intuition schneller auf als Regeln auswendig zu lernen.
Weitere Tools entdecken
Wenn du den Big-O-Komplexitaetsvergleicher nützlich fandest, schau dir den Rest der Visualizers & Logic-Sammlung auf Kitmul an. Wir haben Tools für Regex-Visualisierung, AST-Exploration und andere Informatik-Grundlagen. Alle kostenlos, alle browserbasiert, alle privat; deine Daten verlassen niemals deinen Rechner.
Datenschutz: Jedes Tool auf Kitmul läuft vollständig in deinem Browser. Keine Daten werden an irgendeinen Server gesendet. Kein Konto erforderlich. Kein Tracking über grundlegende Analysen hinaus.