
Letzte Woche schickte mir ein Freund eine Sprachnachricht. "Ich habe eine unglaubliche Basslinie in einem alten Soul-Track gefunden," sagte er, "aber ich kann sie nicht isolieren, ohne 30 Dollar pro Monat für irgendeinen Cloud-Dienst zu zahlen, der meine E-Mail, meine Kreditkarte und wahrscheinlich mein Erstgeborenes will."
Er hat nicht Unrecht. Die Landschaft der Audio-Stem-Separation im Jahr 2026 ist ein Durcheinander aus Abo-Mauern und Cloud-Uploads. Die meisten Tools senden dein Audio an eine Remote-GPU, verarbeiten es und senden die Stems zurück. Du bekommst Ergebnisse in Minuten, klar, aber deine unveroffentlichte Remix-Idee lebt jetzt auf dem Server von jemand anderem.
Ich wollte sehen, ob die gesamte Pipeline lokal laufen kann, in einem Browser-Tab, mit null Netzwerkanfragen nach dem initialen Seitenladen.
Es stellt sich heraus: Ja, das geht.
Was Stem-Separation wirklich ist
Für Unbekannte: Quellentrennung (auch Demixing oder Unmixing genannt) ist der Prozess der Zerlegung eines gemischten Audiosignals in seine Einzelquellen. Ein typischer Pop-Track ist die Summe aus Gesang, Schlagzeug, Bass und allem anderen (Gitarren, Synthesizer, Tasten, Streicher). Die Aufgabe der KI ist es, diese Summe umzukehren.
Der Stand der Technik geht zurück auf Metas Demucs, ein Hybridmodell, das gleichzeitig im Zeit- und Frequenzbereich arbeitet. Es würde auf Tausenden von Multitrack-Aufnahmen trainiert, bei denen die einzelnen Stems bekannt sind, sodass es die spektralen Fingerabdruecke gelernt hat, die eine Bassdrum von einem Bass von einer menschlichen Stimme unterscheiden.
Das Interessante ist, dass Demucs v4 (htdemucs) eine Transformer-Architektur mit einem konvolutionalen U-Net kombiniert. Der Transformer behandelt Langzeit-Abhaengigkeiten (wie eine gehaltene Gesangsnote über einem Schlagzeug-Fill), während das U-Net lokale spektrale Muster erfasst. Das Ergebnis ist deutlich weniger "Bleeding" zwischen Stems im Vergleich zu aelteren Ansaetzen.
Im Browser ausführen mit ONNX + WebAssembly
Der Audio Stem Splitter auf Kitmul laedt eine ONNX-exportierte Version des Demucs-Modells und führt die Inferenz komplett über ONNX Runtime Web mit WebAssembly-Backend aus. Kein Server. Kein Upload. Die Audio-Bytes verlassen nie deine Maschine.
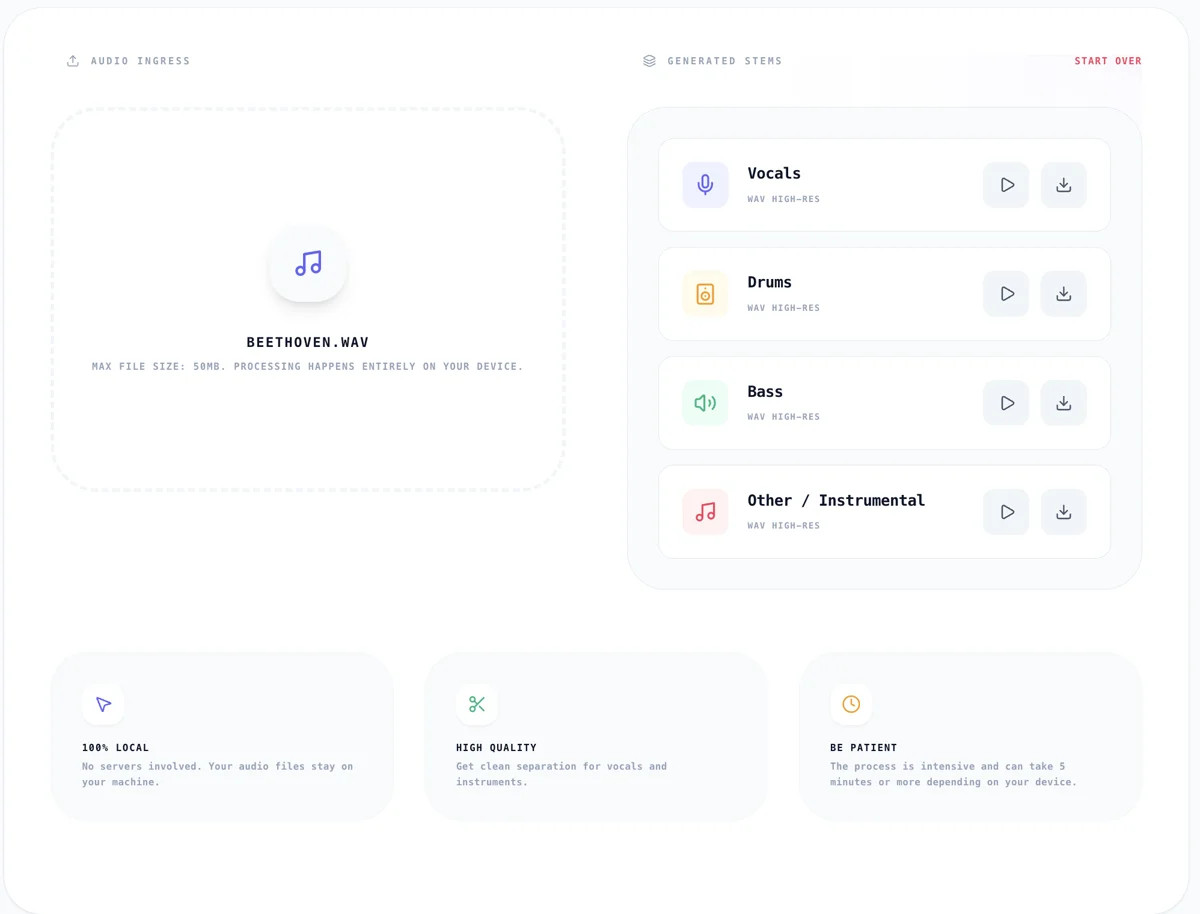
Hier ist, was passiert, wenn du eine Audiodatei ablegst:
- Die Datei wird mit
decodeAudioDatader Web Audio API in rohes PCM dekodiert - Wenn die Abtastrate nicht 44100 Hz beträgt, wird über einen
OfflineAudioContextresampled - Das Audio wird in Chunks aufgeteilt und dem ONNX-Modell in einem Web Worker zugeführt, um den UI-Thread nicht zu blockieren
- Das Modell gibt vier spektrale Masken aus (Gesang, Schlagzeug, Bass, Sonstiges)
- Jede Maske wird auf das Original-Spektrogramm angewendet, um isolierte Stems zu erzeugen
- Die Stems werden zurück in WAV kodiert zum Download
Die gesamte Pipeline ist theoretisch embarrassingly parallel, aber in der Praxis bist du durch den einzelnen WASM-Thread und den verfügbaren RAM begrenzt. Ein 4-Minuten-Song dauert etwa 3-5 Minuten auf einem modernen Laptop. Nicht schnell, aber nicht schlecht für ein neuronales Netz in einem Browser-Tab.
Das Datenschutz-Argument, das niemand macht
Jedes Mal, wenn du einen Track zu LALAL.AI, Moises oder Stem Roller hochlaedst, sendest du potenziell urheberrechtlich geschütztes Audio (oder deine eigene unveröffentlichte Arbeit) an einen Drittanbieter-Server. Deren Datenschutzrichtlinien sagen meist, dass sie "deine Dateien nicht dauerhaft speichern," aber das operative Wort ist "dauerhaft."
Bei clientseitiger Verarbeitung ist die Frage der Datenspeicherung hinfaellig. Es gibt nichts zu speichern. Dein Browser laedt die Modellgewichte einmal herunter (gecacht für kuenftige Besuche), führt die Mathematik lokal aus und erzeugt Ausgabedateien, die nur im Speicher deines Geräts existieren, bis du sie explizit speicherst.
Das ist besonders wichtig für:
- Produzenten, die mit unveröffentlichtem Material arbeiten
- DJs, die Sets mit geschützten Tracks vorbereiten
- Musiklehrer, die Uebungstracks für Schüler erstellen
- Forensische Audio-Analysten, die mit sensiblen Aufnahmen arbeiten

Praktische Anwendungsfaelle, die ich nicht erwartet hatte
Der offensichtliche Anwendungsfall ist Karaoke (Gesang entfernen, mitsingen). Aber ich habe Leute die Stem-Separation für Dinge nützen sehen, die ich nicht bedacht hatte:
Transkriptionshilfe. Eine Jazz-Pianistin erzaehlte mir, dass sie den Piano-Stem aus klassischen Aufnahmen separiert, um Voicings genauer zu transkribieren. Wenn man das Klavier isoliert hoeren kann, erfasst man harmonische Details, die im vollen Mix untergehen.
Sample-Archaeologie. Hip-Hop-Produzenten durchforsten Vinyl-Rips auf der Suche nach Loops. Den Schlagzeug-Break aus einem Funk-Track der 70er zu isolieren gibt dir ein sauberes Sample, ohne die Blaeser per Hand rausgleichen zu müssen.
Barrierefreiheit. Jemand mit eingeschraenktem Hoervermoegen erwaehnte, dass das Verstaerken des Gesangs-Stems und Absenken des Instrumentals dialoglastige Inhalte (Podcasts mit Musikbett, Filmszenen) deutlich klarer macht.
A/B-Tests von Mixes. Wenn du Mixen lernst, kannst du einen professionellen Track in Stems aufteilen, den Mix in deiner DAW von Grund auf neu aufbauen und deine Entscheidungen mit der Originalbalance vergleichen.
Die Grenzen des Modells (ehrliche Einschaetzung)
Die Separation ist nicht perfekt. Hier hat das Modell Schwierigkeiten:
- Stark komprimiertes oder niedrig-bitratiges Audio erzeugt mehr Artefakte. Starte mit 320kbps MP3 oder WAV wenn möglich.
- Dichte Arrangements mit vielen geschichteten Instrumenten bluten stärker in den "Sonstiges"-Stem. Ein Solo-Gitarre-und-Stimme-Track separiert wunderbar; eine Wall-of-Sound Phil-Spector-Produktion weniger.
- Mono-Aufnahmen verlieren die raeumlichen Hinweise, die dem Modell helfen, Quellen zu unterscheiden. Stereo ist immer besser.
- Sehr lange Dateien (>10 Minuten) werden den RAM deines Geräts herausfordern. Das 50MB-Dateilimit hat seinen Grund.
Wenn du Studioqualitaet für eine kommerzielle Veröffentlichung brauchst, willst du wahrscheinlich iZotope RX oder die volle Demucs CLI auf einer GPU. Aber für schnelle Workflows, kreative Erkundung oder Situationen, in denen Datenschutz wichtiger ist als Perfektion, ist die Browser-basierte Separation wirklich nützlich.

Wie es sich gegen die Konkurrenz schlägt
| Merkmal | Kitmul Stem Splitter | LALAL.AI | Moises | Demucs CLI |
|---|---|---|---|---|
| Verarbeitung | 100% lokal (Browser) | Cloud GPU | Cloud GPU | Lokale GPU/CPU |
| Preis | Kostenlos | $15-30/Monat | $4-17/Monat | Kostenlos (OSS) |
| Datenschutz | Kein Upload | Upload erforderlich | Upload erforderlich | Kein Upload |
| Setup | Null | Konto + Zahlung | Konto + Zahlung | Python + ffmpeg |
| Qualität | Gut (ONNX htdemucs) | Sehr gut | Sehr gut | Am besten (volles Modell) |
| Geschwindigkeit | 3-5 Min/Song | ~30 Sek | ~1 Min | ~30 Sek (GPU) |
Der Kompromiss ist klar: du opferst etwas Geschwindigkeit und marginale Qualität für null Setup, null Kosten und vollständigen Datenschutz. Für die meisten nicht-professionellen Workflows ist das die richtige Entscheidung.
Die Web Audio API ist leistungsfaehiger als du denkst
Dies zu bauen hat etwas bestaerkt, das ich immer wieder entdecke: der Audio-Stack des Browsers ist ernsthaft unterschaetzt. Zwischen AudioContext für Echtzeit-Verarbeitung, OfflineAudioContext für Offline-Rendering, AudioWorklet für benutzerdefiniertes DSP auf einem dedizierten Thread und jetzt ONNX Runtime Web für neuronale Netze, kann man legitime Audio-Produktionstools bauen, die vor fuenf Jahren native Apps erfordert haetten.
Probier es aus
Der Audio Stem Splitter ist kostenlos, funktioniert in jedem modernen Browser und verarbeitet alles lokal. Lege eine MP3 oder WAV ab, warte ein paar Minuten und lade deine isolierten Gesangs-, Schlagzeug-, Bass- und Instrumental-Tracks herunter.
Wenn dich Musikproduktion interessiert, passen der Loop Music Creator (Browser-DAW) und der YouTube Loop Mix (Doppel-Deck DJ-Tool) gut zu separierten Stems für Remix-Workflows.
Alle drei Tools laufen in deinem Browser. Keine Konten. Keine Uploads. Keine Abonnements.