Was ist die Backlog-Eingangsraten-Prognose?
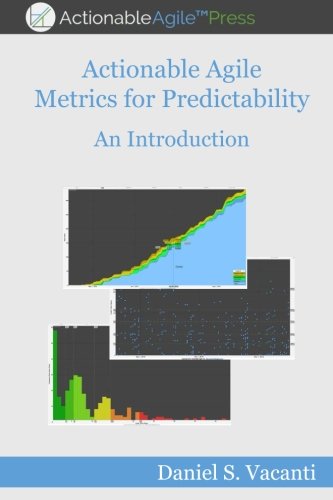
Also, die Idee ist simpel. Du nimmst deine historischen Daten — wie viele Tickets jeden Monat reingekommen sind — und das Tool zieht zwei Sachen raus. Erstens den Trend: steigt die Nachfrage, sinkt sie, oder bleibt sie gleich? Zweitens die Saisonalität: gibt es Monate die immer stärker oder schwächer sind? Mit diesen zwei Komponenten wird eine Prognose für die kommenden Monate generiert. Aber Achtung, das ist keine Magie. Das sind Mathe — lineare Regression und saisonale Zerlegung. Die Qualität der Prognose hängt direkt von der Qualität deiner Daten ab. Wenn deine Zahlen konsistent sind und du genug davon hast, wird die Prognose solide. Wenn nicht, sagt dir der R² das ganz klar. Ist halt trotzdem besser als Raten wie es die meisten Teams machen, oder?
Warum Eingangsraten-Prognose Strategisch Wesentlich ist
Ich habe so viele Teams im Feuerwehr-Modus gesehen. Ein ruhiger Monat, der nächste Monat fallen 40 Tickets auf einmal rein, alle geraten in Panik, WIP explodiert, Zykluszeiten verdoppeln sich, und am Ende wird verspätet geliefert mit haufenweise technischen Schulden. Kommt dir das bekannt vor? Das Problem ist nicht die Nachfrage. Das Problem ist dass man sie nicht vorhersieht. Mit einer zuverlässigen Prognose kannst du Einstellungen im Voraus planen (weil einen Dev zu rekrutieren mindestens 3 Monate dauert). Du kannst Lieferzusagen mit dem Business auf Faktenbasis verhandeln statt "wir geben unser Bestes" zu sagen. Du kannst saisonale Peaks antizipieren und proaktiv den Scope reduzieren. Und vor allem kannst du den Stakeholdern mit Zahlen zeigen warum du mehr Kapazität brauchst. Gegen Daten kann man schlecht argumentieren.
Die Genauigkeitsmetriken MAE und R² Verstehen
Zwei Metriken, mehr brauchst du nicht um zu wissen ob deine Prognose was taugt. Der MAE — Mean Absolute Error — sagt dir im Schnitt um wie viel die Prognose daneben liegt. Ein MAE von 5 bei einem Backlog das 100 Tickets pro Monat bekommt? Exzellent. Ein MAE von 5 bei einem Backlog von 10 Tickets pro Monat? Katastrophal. Kontext zählt halt. Der R² ist der Anteil der Variation den das Modell erklärt. Ein R² von 0.85 heißt dass 85% des Verhaltens deiner Daten erklärt wird. Die restlichen 15% sind Rauschen, einmalige Events. In der Praxis: über 0.7 ist gut. Unter 0.5 gibt es ein Problem — entweder zu wenig Daten oder Anomalien die alles verzerren. Und das Tool sagt dir das klar. Du musst kein Data Scientist sein um das zu interpretieren.
Best Practices für Zuverlässige Prognosen
Erstes Ding: sei konsistent bei der Datenerfassung. Wenn du einen Monat User Stories zählst und den nächsten Sub-Tasks, wird deine Prognose Müll. Definiere was ein Backlog-Element ist und miss immer das Gleiche. Zweites Ding: schmeiß Anomalien raus. Der Monat wo du 200 Tickets aus einem Altsystem importiert hast? Raus damit. Sonst denkt das Modell das sei normal und deine Prognose wird aufgebläht. Drittes Ding: peil 12 bis 24 Datenpunkte für Saisonalität an. Mit 6 Punkten kannst du einen Trend erkennen, aber zyklische Muster brauchen mehr Rückblick. Und viertes Ding, das Wichtigste: vergleich deine Prognose jeden Monat mit der Realität. Letzten Monat hast du 28 vorhergesagt, es waren 32? Notier es, integriere den neuen Punkt, rechne neu. So verbessert sich deine Prognose mit der Zeit. Kombinier das Ganze mit Zykluszeit- und Durchsatz-Metriken und du hast ein komplettes Bild von Nachfrage vs. Kapazität.