
J'ai brûlé 176 millions de tokens Anthropic mercredi dernier. Vous voyez le pic dans la capture un peu plus bas. L'essentiel, c'était du travail productif avec Claude Code, mais en traquant l'anomalie j'ai trouvé un job batch qui envoyait tranquillement du HTML brut à Claude Sonnet 4.5 pour résumé. Les prompts fonctionnaient ; le budget de tokens non. Quand j'ai enfin regardé ce que mon scraper passait au modèle, environ 70% de chaque requête était de la soupe <div class="css-1f2x">. L'article réel, la partie qui m'intéressait, faisait peut-être 25% du payload.
Le correctif tenait en cinq lignes : convertir le HTML en Markdown avant d'envoyer au modèle. Le nombre de tokens a chuté de 60%. Qualité de sortie identique. J'aurais aimé apprendre ça plus tôt.
Ce post explique pourquoi ça marche, quand c'est important, et plusieurs problèmes voisins que la même astuce résout.
Pourquoi le HTML est un désastre en tokens
Les LLM tokenisent le texte. Anthropic expose un endpoint de comptage de tokens dans l'API Claude, et le tiktoken open-source d'OpenAI donne une vue similaire : la prose anglaise se découpe en environ un token tous les 3-4 caractères. Mais le HTML n'est pas de la prose. C'est un arbre imbriqué de balises, noms de classes, styles inline, attributs SVG et blobs JSON injectés dans des attributs data-* par chaque framework moderne.
Vous pouvez le vérifier vous-même. Collez un paragraphe en texte brut dans le compteur de tokens d'Anthropic et notez le chiffre. Puis enveloppez-le dans un typique <div class="prose dark:prose-invert max-w-none sm:px-6 lg:px-8"> généré par React et recomptez. Ce seul wrapper, cette ligne unique, peut vous coûter 30-40 tokens. Multipliez sur une page scrapée avec 500 divs imbriquées et vous voyez où part l'argent.
Le Markdown, à l'inverse, est presque invisible pour un tokenizer. Un titre fait deux caractères : # . Un gras quatre : **x**. Un lien s'écrit [texte](url), et le modèle le gère nativement parce que son corpus d'entraînement est saturé de Markdown venu de GitHub, Stack Overflow et Reddit.
J'ai fait un test rapide sur l'article Wikipédia du protocole HTTP :
- HTML brut (sauvegardé depuis le navigateur) : ~48 000 tokens
- HTML nettoyé (style boilerpipe) : ~22 000 tokens
- Conversion en Markdown : ~8 900 tokens
C'est une réduction de 81% face au brut, et de 60% face à un payload HTML déjà nettoyé. Sur un modèle facturé au token d'entrée, ce n'est pas une micro-optimisation. C'est la différence entre un produit viable et un chargeback Stripe.
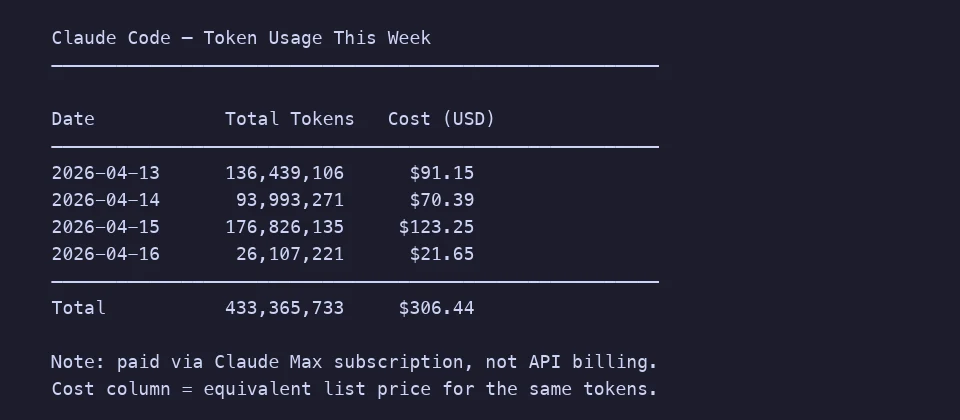
Voici une semaine de mon utilisation réelle de Claude Code en référence. Quatre jours, 433 millions de tokens, environ 306 $ aux tarifs catalogue (je suis sur un abonnement Max, mais l'équivalent en pay-as-you-go rend l'échelle lisible). L'essentiel, c'est du code productif. Imaginez ce que vous économisériez sur une année en grattant 10-15% sur le bruit structurel.
Le cas du pipeline RAG
Si vous construisez du retrieval-augmented génération, l'enjeu est encore plus grand. Un système RAG typique :
- Crawl ou scrape les documents source
- Les découpe en chunks qui tiennent dans la fenêtre de contexte du modèle d'embeddings
- Embed chaque chunk dans une base vectorielle
- Au moment de la requête, récupère les top-K chunks et les injecte dans le prompt
Chacune de ces étapes empire avec du HTML. Les embeddings dérivent parce que le modèle essaie d'encoder les noms de classes CSS en même temps que le sens réel. Le découpage devient irrégulier ; soit vous coupez au milieu d'une balise et troublez le retriever, soit vous utilisez un split par caractères naïf qui coupe une phrase en deux. La latence de récupération augmente parce que l'espace vectoriel est pollué par du bruit structurel.
Convertir en Markdown avant le chunking règle les trois. L'excellente documentation LangChain le recommandé discrètement : utilisez MarkdownHeaderTextSplitter ou RecursiveCharacterTextSplitter avec des séparateurs Markdown. Leurs propres exemples passent d'abord par du HTML vers Markdown. Il y à une raison.
Quand vous ne pouvez pas lancer Python côté serveur
Beaucoup d'articles sur HTML-vers-Markdown supposent un backend avec BeautifulSoup et markdownify installés. Très bien si vous construisez un pipeline. Pénible si vous êtes rédacteur, journaliste archivant des sources, ou développeur faisant une migration one-shot à 23h.
J'ai construit Kitmul HTML to Markdown parce que je redemandais exactement ce workflow et détestais chaque option. L'outil tourne dans le navigateur. Collez la source HTML, obtenez le Markdown. Rien ne part, rien n'appelle la maison. La conversion se fait en JavaScript sur votre machine, ce qui veut dire que vous pouvez coller des exports de wiki interne, des brouillons juridiques ou du contenu client sans hésitation.
Si vous n'avez jamais inspecté le HTML d'une page, ouvrez n'importe quel article, clic droit, "Afficher le code source", copiez le corps de l'article. Passez-le à l'outil. Ce qui ressort est quelque chose que vous pouvez mettre dans un prompt, coller dans Notion ou commit dans un repo Git.
Sept endroits où ça aide vraiment
Il m'a fallu du temps pour reconnaître combien de mes problèmes se réduisent à "j'ai du HTML et j'aimerais que ce soit du Markdown". Liste partielle :
Donner un long article à un LLM. Les plus gros gains arrivent quand vous résumez, extrayez des entités ou posez des questions sur une page web longue. Le Markdown vire le chrome et laisse le fond. Le coût du prompt baisse, et ironiquement le modèle s'en sort mieux sur une entrée plus propre parce qu'il arrête d'être distrait par du CSS.
Migrer un blog depuis WordPress ou Ghost. Si vous passez à un générateur statique comme Astro, Hugo ou Jekyll, chaque post doit être un fichier .md. Exportez le XML WordPress, passez chaque bloc <content:encoded> par le convertisseur, déposez le résultat dans content/posts/. J'ai déplacé 84 posts comme ça en une soirée.
Archiver des recherches. Je tiens un wiki personnel d'articles d'ingénierie que je consulte souvent. Des pages disparaissent du web tout le temps ; la durée de vie moyenne d'une page web est inférieure à 100 jours. Les snapshots Markdown se lisent en millisecondes, diffèrent proprement dans Git, et survivent aux changements de formats bien mieux que des captures d'écran ou des PDF.
Préparer des données d'entraînement ou des exemples few-shot. Si vous curatez des exemples pour du fine-tuning ou de l'in-context learning, vous les voulez cohérents. Le Markdown est la forme cohérente. Chaque source scrapée finit avec la même forme, la même hiérarchie de titres, et sans wrappers <span> qui brouillent votre template.
Nettoyer du contenu après des éditeurs visuels. Des outils comme Notion, Medium ou CKEditor exportent un HTML techniquement correct mais plein d'imbrications <p><strong><em><u> dont personne ne veut. Un passage par Markdown collapse ça à la forme sémantique minimale, et il vous reste une source portable et diffable.
Écrire de la documentation depuis des références API scrapées. Je l'ai fait pour trois SDK. Récupérez le HTML rendu des docs du fournisseur (beaucoup sont sur MkDocs ou Docusaurus sans source Markdown disponible), convertissez, et vous avez un point de départ éditable et commitable. C'est plus rapide que recopier chaque bloc de code à la main.
Réduire les coûts sur l'API Claude et l'API Gemini. Chaque modèle frontière facture les tokens d'entrée. Le prompt caching d'Anthropic aide, mais cacher 48K de HTML reste pire que cacher 9K de Markdown. Les caches évictent aussi. Le token le moins cher est celui que vous n'envoyez jamais.
Ce qui se perd dans la conversion
Soyez honnête sur les compromis. Certaines choses ne survivent pas :
- Le style visuel. Couleurs, polices, CSS custom. Si la mise en page est le contenu (infographies, landing pages), le Markdown est la mauvaise cible.
- Les composants interactifs. Formulaires embarqués, iframes, widgets JavaScript. Ils deviennent soit des liens bruts, soit ils disparaissent.
- Les mises en page exactes des tableaux. Le Markdown gère lignes et colonnes, mais les cellules fusionnées, colspans et tables imbriquées se simplifient ou cassent. Pour des tables riches en données, l'export CSV est souvent un meilleur chemin ; notre outil CSV vers JSON couvre le cas voisin.
- Le positionnement des images. Les images Markdown sont inline, de haut en bas. Les layouts en float ne traduisent pas.
Pour 90% des pages texte, rien de tout ça n'importe. Pour les 10% restants, vous voulez probablement garder le HTML de toute façon.
Un workflow concret
Voici la routine à laquelle je me tiens pour le travail avec les LLM :
- Scrapez la page avec
fetchou Playwright et prenez l'innerHTML du corps de l'article, pas le document entier. Un bon sélecteur CSS fait la moitié du nettoyage. - Si c'est ponctuel, collez dans le convertisseur HTML vers Markdown. Si c'est en batch, utilisez une librairie comme
turndown(sur GitHub) oumarkdownifyen Python. - Enlevez le boilerplate (bannières de cookies, "articles liés", CTAs newsletter). Le Markdown rend ça facile : le bruit se concentre en haut et en bas.
- Envoyez au modèle. Pour les documents longs, découpez par titres Markdown plutôt que par comptage de caractères.
- Cachez la version Markdown localement. La prochaine exécution ne devrait pas répéter l'étape 1.
Le tout prend généralement plus de temps à décrire qu'à exécuter.
Le propos plus large
La conversion de format, ça semble ennuyeux. Jusqu'à ce que vous voyiez votre facture API fondre de 60% parce que vous avez arrêté d'envoyer du bruit structurel ASCII à un modèle de mille milliards de paramètres. Les LLM ne sont pas chers en absolu mais au million de tokens, et le nombre de pipelines où quelqu'un envoie du HTML brut dans une fenêtre de contexte est franchement gênant.
Le Markdown est la lingua franca des données d'entraînement IA. C'est un fait sur le monde, pas une opinion. Travailler en Markdown aligne vos entrées sur ce que le modèle sait manipuler, et une forme intermédiaire en texte brut vous donne aussi une version que votre historique Git sait differ correctement, ce que vous apprécierez dans six mois en cherchant à quoi ressemblait le prompt au Q3.
Essayez
Ouvrez le convertisseur HTML vers Markdown, collez n'importe quel HTML, et voyez le compteur de tokens s'effondrer. Tout tourne dans votre navigateur, donc vos brouillons clients, sources scrapées et docs internes ne quittent jamais votre machine. Le code est inspectable dans l'onglet Network des DevTools ; zéro requête sortante pendant la conversion.
Si vous voulez publier le Markdown sur un support visuel, le convertisseur Markdown vers Medium produit une sortie prête pour l'éditeur de Medium.
Lectures associées : Comment publier du Markdown sur Medium sans perdre la mise en forme · Pourquoi les outils côté client sont plus privés que le cloud · AVIF en 2026 : le guide complet
Outils associés : Formateur JSON · CSV vers JSON · Compteur de mots · Comparateur de texte · Compresseur d'images