
En 2018, j'ai écrit mon premier article sur TensorFlow.js. J'exécutais PoseNet dans un onglet de navigateur ; estimation de poses humaines en temps réel sans aucune infrastructure serveur. L'idée semblait radicale à l'époque. Les gens demandaient pourquoi je n'utilisais pas un serveur GPU dédié. Ma réponse était la même alors qu'aujourd'hui : parce que le navigateur suffit, et ça ne coûte rien.
Huit ans plus tard, le même principe s'applique à la détection d'objets. Je n'ai jamais exécuté YOLO depuis un serveur. Pas une seule fois. La prémisse d'envoyer les images des utilisateurs sur le GPU de quelqu'un d'autre n'a jamais eu de sens pour moi quand WebGL était déjà là, à l'intérieur de chaque portable.
L'argument que je fais depuis 2018
Dans ce post sur TensorFlow.js, j'ai écrit quelque chose qui tient toujours :
Avant TensorFlow.js, il était impossible d'utiliser des modèles de machine learning directement dans le navigateur sans interaction avec une API. Maintenant nous pouvons entraîner et utiliser des modèles hors ligne. Les prédictions sont beaucoup plus rapides car elles ne nécessitent pas la requête au serveur. Un autre avantage est le faible coût en serveur car tous ces calculs sont côté client.
Trois avantages. Ils n'ont pas changé :
1. Zéro coût serveur. Chaque inférence qui s'exécute sur l'appareil de l'utilisateur est une que tu ne paies pas. J'ai construit un classificateur d'images chat/chien, un détecteur de toxicité de texte, des démos PoseNet ; tout fonctionnant entièrement dans le navigateur. Ma facture AWS pour l'inférence ML est à zéro depuis huit ans parce que je n'en ai jamais démarré une.
2. Prédictions hors ligne. Le modèle se télécharge une fois, est mis en cache par le navigateur, et fonctionne indéfiniment sans connexion réseau. Essaie ça avec une API cloud.
3. Vie privée par architecture. Quand il n'y a pas de serveur, il n'y a rien à qui faire confiance. Les données de l'utilisateur restent sur son appareil parce qu'il n'y a physiquement nulle part ailleurs où aller. Ce n'est pas un choix de politique ; c'est une garantie structurelle.
Pourquoi l'industrie a pris l'autre chemin
La plupart des entreprises ont choisi la voie du serveur quand même. Les raisons étaient pratiques à l'époque : WebGL était immature, Wasm n'existait pas encore, les modèles étaient trop lourds pour être servis depuis le navigateur. L'industrie a convergé vers un schéma ; télécharger l'image, exécuter l'inférence sur GPU, renvoyer du JSON.
Ce schéma a créé des problèmes que les gens gèrent encore aujourd'hui :
La vie privée est un passif juridique. Ton image atteint un serveur, est loguée, peut-être stockée pour « améliorer le modèle ». Le RGPD et le CCPA existent précisément parce que cette architecture divulgue les données utilisateur par défaut. Chaque image envoyée à une API de détection est un passif sous l'Article 9 du RGPD.
La latence s'accumule. Envoyer 2 Mo, attendre l'inférence, télécharger les résultats. Avec une bonne connexion : 800ms-2s. Sur mobile : timeout. La recherche Google Web Vitals montre que les utilisateurs abandonnent les tâches après 3 secondes. La détection avec aller-retour serveur passe à peine.
Le coût évolue linéairement. Mille détections via une API cloud signifie une facture. Ça rend le prototypage cher et tue l'expérimentation ; exactement l'opposé de ce que je voulais en 2018 quand j'essayais simplement de faire marcher PoseNet avec une webcam.
Ce qui a mûri : WebAssembly a rattrapé WebGL
En 2018, le ML dans le navigateur était limité. TensorFlow.js utilisait WebGL pour l'accès GPU, mais l'écosystème était petit et les modèles basiques. Depuis :
WebAssembly a atteint une vitesse d'exécution quasi native. L'équipe ONNX Runtime a publié un backend Wasm qui exécute des graphes complets de réseaux neuronaux dans le navigateur. Cela signifie que les modèles qui n'ont pas besoin de GPU (ou qui tournent sur des appareils avec des GPU faibles) peuvent s'exécuter à des vitesses acceptables.
WebGL a mûri significativement, et WebGPU arrive dans les navigateurs avec un support approprié des compute shaders. Les multiplications matricielles qui prenaient des secondes sur CPU en 2018 se terminent maintenant en millisecondes sur les GPU intégrés.
L'écosystème de modèles a explosé. En 2018 j'avais PoseNet et MobileNet. Aujourd'hui tu peux exécuter YOLO, Whisper, Stable Diffusion, des LLMs ; tout côté client. Le zoo de modèles ONNX a des centaines de modèles prêts pour la production, optimisés pour l'inférence navigateur.
La thèse de 2018 était correcte. Elle avait juste besoin que l'outillage se mette à niveau.
Comment YOLO fonctionne (et pourquoi il est idéal pour l'inférence navigateur)
YOLO (« You Only Look Once ») est architecturalement parfait pour l'usage côté client parce qu'il traite l'image entière en un seul forward pass. Les détecteurs traditionnels comme R-CNN faisaient deux étapes ; proposer des régions, puis classifier chacune. Lent et séquentiel. YOLO fait tout d'un coup :
- Diviser l'image en une grille S x S
- Chaque cellule prédit bounding boxes + confiance + probabilités de classe simultanément
- La suppression non maximale élimine les doublons
- Sortie : objets avec coordonnées, étiquettes et scores de confiance
Le papier original de 2016 de Redmon et al. atteignait 45 FPS. L'architecture a évolué à travers YOLOv5, YOLOv8 et au-delà. Le modèle détecte 80 catégories d'objets du dataset COCO : personnes, véhicules, animaux, meubles, électronique, nourriture.
L'inférence en un seul passage signifie une latence prévisible. Pas de propositions de régions itératives, pas de calcul variable. Une image entre, un ensemble de détections sort. Cette prévisibilité est ce qui le rend viable dans un navigateur où tu ne peux pas supposer qu'une 3090 attend.
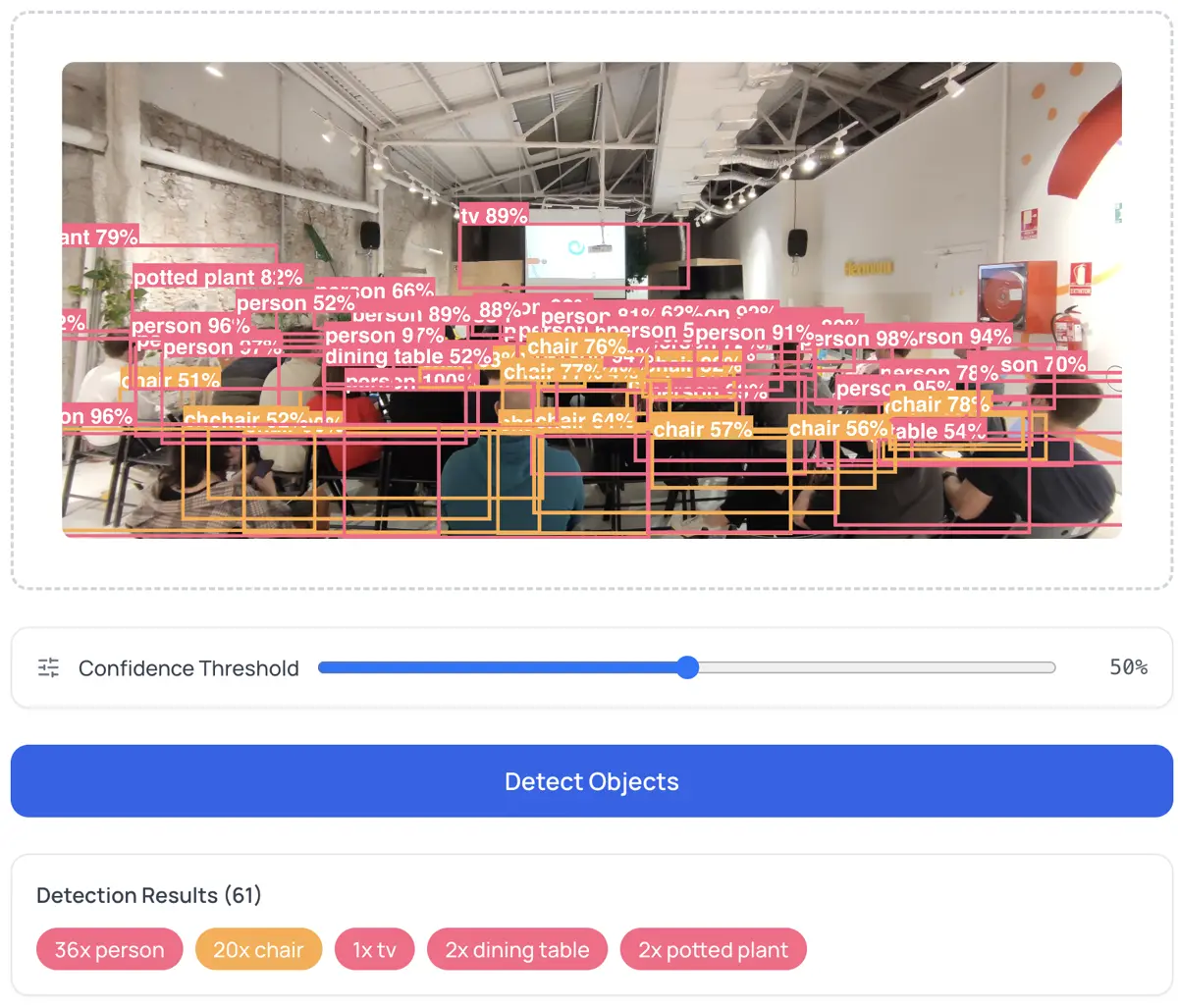
La vie privée n'est pas une fonctionnalité ; c'est l'absence d'un serveur
J'y reviens constamment parce que c'est le cœur de pourquoi je construis les choses ainsi. Quand je dis « ça s'exécute dans ton navigateur », je veux dire : ouvre les DevTools, va dans l'onglet Network, lance une détection. Zéro requête sortante après le téléchargement initial du modèle. Ton image reste dans la mémoire du navigateur, est traitée par le GPU, et les résultats sont rendus sur un élément canvas.
Ça compte dans les cas où le traitement côté serveur est illégal ou absurde :
- Imagerie médicale. Les hôpitaux ne peuvent pas envoyer des scanners de patients à des API aléatoires. Les violations HIPAA commencent à $100 par dossier.
- Séquences de surveillance. Envoyer des flux de caméras à des services cloud est un champ de mines juridique dans la plupart des juridictions de l'UE.
- Photos personnelles. Les gens ne veulent pas leurs photos de famille sur l'ordinateur de quelqu'un d'autre. Le fait que ça doive être dit est le problème.
Avec la détection dans le navigateur, la question de confiance est non pertinente. Il n'y a pas de serveur auquel faire confiance.
Ce que tu peux faire avec
Compter des objets. Télécharge une photo de parking et obtiens un décompte de véhicules. Étagère d'entrepôt ; compte les cartons. Photo d'événement ; compte les personnes. Sans code, sans configuration.
Prototyper des pipelines de vision par ordinateur. Avant d'écrire du Python, teste comment YOLO performe sur tes images spécifiques. Exporte les détections JSON et injecte-les dans ton pipeline. Le Détecteur d'Objets te permet d'ajuster les seuils de confiance et d'exporter des PNG annotés et du JSON structuré.
Générer des métadonnées d'accessibilité. Lance la détection sur des images de produits pour produire du texte alt descriptif. « L'image contient : 2 personnes, 1 ordinateur portable, 1 tasse de café » bat un attribut alt vide. L'Initiative pour l'Accessibilité du Web du W3C le recommande pour toutes les images informatives.
Contrôle qualité depuis une tablette. Les équipes de fabrication peuvent exécuter la détection de défauts sur des photos de produits dans un navigateur. Pas de matériel dédié. Pas de dépendance cloud.
Le seuil de confiance
Chaque détection a un score entre 0 et 1. Le seuil contrôle ce que tu vois :
- 0.3 : Plus de détections, plus de bruit. Bon pour explorer ce que le modèle trouve.
- 0.7 : Moins de détections, haute précision. Bon pour la production.
- 0.5 : Équilibre raisonnable pour la plupart des cas.
C'est le compromis précision-vs-rappel. CS231n de Stanford explique le framework mAP pour évaluer les détecteurs en détail.
Limitations honnêtes
L'inférence navigateur ne remplace pas tout. Les contraintes :
Vitesse. Un GPU dédié exécute YOLOv8 en 5-10ms. Un navigateur prend 100-500ms par image. Suffisant pour les images individuelles ; trop lent pour la vidéo temps réel à 30 FPS.
Taille du modèle. Les poids YOLO font 20-50 Mo. Le premier chargement nécessite de les télécharger. Après, le cache du navigateur s'en occupe.
Catégories fixes. Le modèle COCO connaît 80 classes. Les objets personnalisés (pièces de machines spécifiques, espèces rares) nécessitent des modèles fine-tunés. Tu peux apporter ton propre modèle ONNX, mais l'entraînement nécessite toujours un GPU ailleurs.
Mobile. Les téléphones ont des GPU plus faibles. Compte 2-3 secondes par détection sur du matériel milieu de gamme.
Rien de tout cela n'est rédhibitoire pour le cas d'usage principal : détection d'objets rapide, privée, à coût zéro.
Boucle bouclée
En 2018 j'ai écrit « le faible coût en serveur car tous ces calculs sont côté client ». Cette phrase décrit exactement ce que fait le Détecteur d'Objets. Charge un modèle YOLO dans le navigateur, télécharge une image, obtiens des détections. Pas d'inscription, pas de clé API, pas d'envoi sur le serveur de qui que ce soit.
La technologie a mûri. Le principe n'a jamais changé.
Tourne sur ONNX Runtime Web, entraîné sur COCO (80 catégories). Architecture : YOLO par Ultralytics. Si tu veux comprendre les fondations, commence par mon post TensorFlow.js de 2018.