
Il y a trois façons de transformer une réponse JSON en interfaces TypeScript. On peut les écrire à la main, demander à un LLM, ou passer le JSON dans un convertisseur déterministe. J'ai utilisé les trois. Deux d'entre elles ont des modes de defaillance auxquels la plupart des gens ne pensent pas jusqu'a ce qu'ils deployent un bug.
L'approche manuelle : lente et précise jusqu'a ce qu'elle ne le soit plus
Écrire des interfaces à la main fonctionne quand on a trois champs. Ça s'arrete vers le quinzieme. Un objet charge Stripe a plus de 40 propriétés. Une réponse de pull request GitHub dépasse les 100 champs une fois qu'on compte les objets imbriqués. Personne ne les type à la main sans faire d'erreurs.
Le mode de defaillance est subtil. On ouvre la doc API, on commencé a écrire, et au vingtieme champ on survole. merged_at etait un string ou un Date ? labels est un tableau d'objets ou de strings ? On devine, on continue, et le compilateur TypeScript fait confiance à ce qu'on a écrit. Le système de types ne détecte les erreurs que si les types sont corrects au depart.
La documentation TypeScript le dit clairement : any désactivé la vérification de types pour cette valeur. Mais une interface incorrecte est sans doute pire que any, parce qu'elle donne une fausse confiance. L'IDE autocomplete des champs qui n'existent pas. Le code compile. Le crash arrive au runtime.
L'approche LLM : rapide et probabiliste
Coller un bloc JSON dans ChatGPT ou Claude et demander des interfaces TypeScript est tentant. C'est rapide. Ça gère l'imbrication. Ça nomme même les interfaces de manière raisonnable la plupart du temps.
Le problème est que les LLMs sont probabilistes. Donne le même JSON au même modèle deux fois et tu pourrais obtenir des sorties différentes. Parfois il ajoute ? a des champs qui ne sont pas optionnels. Parfois il invente un type union qui ne correspond pas aux données. Parfois il decide que id devrait être string alors que la valeur est clairement 1. J'ai vu des modèles produire Date pour des strings de timestamp ISO ; techniquement aspirationnel, mais incorrect si on ne parse pas le string en objet Date d'abord.
Ce ne sont pas des bugs du modèle. C'est la nature de l'outil. Un LLM généré du texte plausible base sur des patterns. Il ne parse pas ton JSON comme le fait un système de types. Il le lit, approxime ce que les types devraient être, et écrit quelque chose qui à l'air correct. La plupart du temps ça l'est. Mais "correct la plupart du temps" et "deterministiquement correct" sont des choses différentes quand tes définitions de types protegent le comportement au runtime.
Il y a aussi l'angle vie privée. Coller une réponse API de production dans un LLM tiers signifie envoyer tes données au serveur de quelqu'un d'autre. Si cette réponse contient des PII utilisateur, des endpoints internes, ou des tokens d'authentification qui se sont glisses dans le payload, tu viens de les partager avec un service externe. Pour des projets perso, personne ne s'en soucie. Pour des codebases de production avec des exigences de conformite, c'est une conversation avec ton équipe sécurité que tu ne veux pas avoir.
L'approche déterministe : même entrée, même sortie, à chaque fois
Un convertisseur déterministe JSON vers TypeScript ne devine pas. Il parse. L'algorithme parcourt l'arbre JSON, inspecte le type JavaScript de chaque valeur, et le mappe au type TypeScript correspondant. Pas d'aléatoire, pas de paramètre de temperature, pas de modèle qui pourrait se comporter differemment un jeudi.

Les regles sont mecaniques :
"hello"est toujoursstring. Pas parfoisstring, pas occasionnellement"hello"comme type litteral.42est toujoursnumber. Pasint, pasfloat, pasnumber | string.[1, 2, 3]est toujoursnumber[]. PasArray<number>, pasnumber[] | undefined.{"a": 1}généré toujours une interface nommee séparée aveca: number.nullest toujoursnull. Pasundefined, pas omis.
Même JSON en entrée, même TypeScript en sortie. Execute-le cent fois et tu obtiens cent résultats identiques. C'est la propriété que tu veux d'un outil qui généré des définitions de types auxquelles ton compilateur fera confiance.
Ce que l'algorithme fait vraiment
Sous le capot, le convertisseur effectue une descente recursive dans ta structure JSON. Pour chaque valeur rencontree, il appelle inferType(), qui retourne la chaine du type TypeScript. Les objets produisent de nouvelles entrées d'interface dans un Map. Les tableaux inspectent leurs éléments et produisent soit un type uniforme (string[]) soit un type union ((string | number)[]). Les tableaux vides deviennent unknown[] car il n'y a pas d'élément pour inferer.
Les noms de propriétés sont convertis en PascalCase pour les noms d'interfaces. Les clés qui ne sont pas des identifiants JavaScript valides (tirets, espaces, chiffres en début) sont automatiquement entre guillemets. La sortie peut basculer entre declarations interface et type.
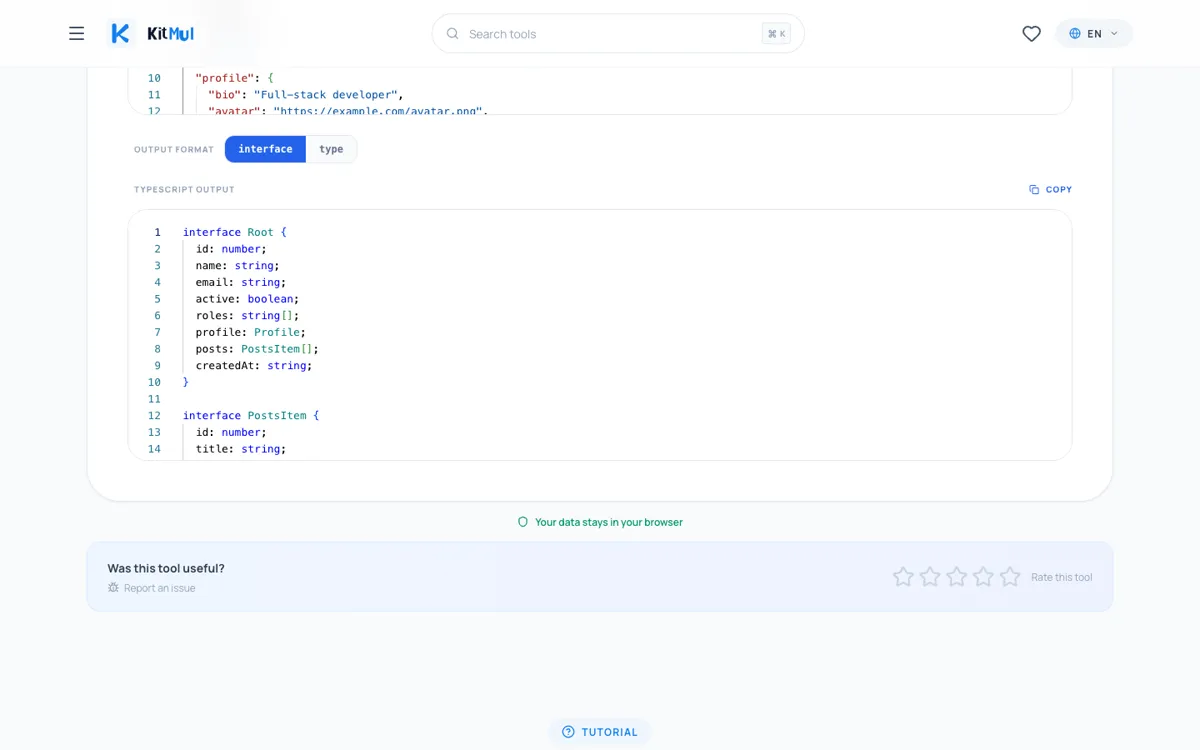
Un exemple concret. Ce JSON :
{
"id": 1,
"name": "Aral Roca",
"email": "aral@example.com",
"active": true,
"rôles": ["admin", "editor"],
"profile": {
"bio": "Full-stack developer",
"avatar": "https://example.com/avatar.png",
"social": {
"github": "aralroca",
"twitter": "aralroca"
}
},
"posts": [
{
"id": 101,
"title": "Understanding TypeScript Interfaces",
"published": true,
"tags": ["typescript", "tutorial"]
}
],
"createdAt": "2026-04-27T10:00:00Z"
}
Produit exactement ceci :
interface Root {
id: number;
name: string;
email: string;
active: boolean;
rôles: string[];
profile: Profile;
posts: PostsItem[];
createdAt: string;
}
interface Profile {
bio: string;
avatar: string;
social: Social;
}
interface Social {
github: string;
twitter: string;
}
interface PostsItem {
id: number;
title: string;
published: boolean;
tags: string[];
}
Quatre interfaces. Chaque champ correctement type. Chaque objet imbriqué extrait dans sa propre interface nommee. Aucun hasard implique.
Interface vs. type : quand la bascule compte
Le convertisseur offre les deux sorties interface et type. Le choix n'est pas cosmetique.
Les interfaces supportent le declaration merging ; si deux interfaces partagent le même nom dans le même scope, TypeScript fusionne leurs propriétés. Les types non. Pour les auteurs de bibliotheques qui veulent que les consommateurs etendent les types, les interfaces sont le meilleur choix.
Les types gérént les unions, intersections et mapped types plus naturellement. Si tu as besoin de type Result = Success | Error ou composer des shapes avec &, la sortie type t'epargne une étape.
Pour le typage de réponses API, ça compte rarement. Choisis ce qu'imposent les regles de linting de ton équipe et avance.
Ou l'inference déterministe nécessité encore une revision humaine
Le convertisseur infere les types à partir des valeurs, pas des schémas. C'est une feature ; ça fonctionne avec n'importe quel JSON sans necessiter une spec OpenAPI ni JSON Schéma. Mais ça signifie qu'il y a des cas limites ou tu voudras ajuster :
Champs optionnels. Le convertisseur ne voit que l'echantillon fourni. Si un champ est parfois absent de la réponse, ajoute ? manuellement.
Enums de string. "status": "active" devient string, pas "active" | "inactive" | "suspended". Restreins-le toi-même.
Chaines de date. Les timestamps ISO 8601 comme "2026-04-27T10:00:00Z" sont string pour le convertisseur. Si tu les parses avec date-fns ou dayjs, tu voudras les changer en Date dans tes types finaux.
Wrappers de pagination. Une réponse comme { data: [...], meta: { page: 1, total: 100 } } généré une interface Root avec les deux. Renomme-la en PaginatedResponse<T> et extrais Meta comme générique.
Ces ajustements prennent des secondes. Le point est que le convertisseur déterministe te donne une ligne de base correcte ; les parties qui necessitent du jugement humain sont celles qu'une machine ne peut genuinement pas inferer d'un seul echantillon. Un LLM les raterait aussi ; la différence est que le LLM pourrait en plus se tromper sur les parties faciles.
La vie privée comme feature, pas comme slogan marketing
Le convertisseur tourne entièrement côté client. Le JSON ne quitte jamais ton navigateur. Pas d'appel serveur, pas d'analytique sur ton input, pas de compte.
Ce n'est pas un benefice abstrait. Beaucoup d'équipes ont des politiques de sécurité qui interdisent d'envoyer du code source ou des réponses API a des services tiers. Ça exclut la plupart des outils en ligne. Ça exclut coller des réponses de production dans des chatbots LLM. Un convertisseur côté client qui traité tout dans une fonction JavaScript sur ta machine a zero surface de conformite.
Ouvre l'onglet réseau de ton navigateur pendant l'utilisation. Tu ne verras rien envoye.
Un workflow pratique
1. Obtenir une vraie réponse. Utilisé curl, Postman ou l'onglet réseau de ton navigateur pour capturer une réponse API reelle.
2. Coller et convertir. Ouvre le convertisseur JSON vers TypeScript, colle le JSON, copie la sortie.
3. Renommer et affiner. Change Root en UserResponse. Ajoute ? ou c'est nécessaire. Restreins les unions de strings.
4. Co-localiser avec ton client API. Je mets les types dans un types.ts a côté du fichier qui fait l'appel fetch ou axios.
5. Ajouter la validation runtime. Utilisé Zod ou Valibot pour valider que l'API envoie vraiment ce que tes types decrivent. Le convertisseur te donne la structure ; une bibliotheque de schémas te donne des garanties runtime.
Le tout prend moins d'une minute par endpoint.
Au-dela des réponses API
Le convertisseur gère tout JSON valide :
- Fichiers de configuration. Colle
tsconfig.jsonoupackage.jsonpour un chargement de configuration type-safe. - Exports de base de données. Un document MongoDB ou une ligne PostgreSQL en JSON devient les types de ta couche ORM.
- Fixtures de test. Si tu ecris des tests avec Jest ou Vitest, convertir les fichiers fixture assure que tes mocks correspondent aux formes de production.
- Contenu CMS. Les réponses de CMS headless de Strapi, Sanity ou Contentful sont profondement imbriquées. Type-les une fois ; laisse le compilateur détecter les bugs de template.
Pour formater du JSON avant de convertir, le Formateur JSON gère le pretty-printing et la validation. Pour la direction opposee ; nettoyer du HTML en quelque chose qu'un LLM peut traitér efficacement ; il y a le convertisseur HTML vers Markdown.
La matrice des compromis
| Manuel | LLM | Déterministe | |
|---|---|---|---|
| Vitesse | Lente | Rapide | Rapide |
| Exactitude | Depend de toi | Majoritairement correcte | Toujours correcte pour l'echantillon |
| Coherence | Variable | Non déterministe | Identique à chaque fois |
| Vie privée | N/A | Données envoyées au serveur | Côté client uniquement |
| Champs optionnels | Tu decides | Devine parfois | Tu decides |
| Restriction de strings | Tu decides | Devine parfois | Tu decides |
Le convertisseur déterministe gère la partie mecanique; mapper des valeurs vers des types; parfaitement. Les parties qu'il ne peut pas gérer (optionnalité, enums de string, parsing de dates) sont les mêmes que les autres approches ne gérént pas non plus de manière fiable. La différence est qu'il n'introduit pas de nouvelles erreurs sur les parties qu'il peut gérer.
Le verdict
La sécurité des types n'est pas un spectre. Tes types sont corrects ou ils ne le sont pas. Le typage manuel est lent et source d'erreurs à l'échelle. Le typage LLM est rapide mais probabiliste. La conversion déterministe est rapide et correcte; dans les limites de ce que n'importe quel outil peut inferer d'un seul echantillon JSON.
Utilisé le convertisseur JSON vers TypeScript pour le travail mecanique. Garde ton jugement pour les champs optionnels, les unions de strings et le nommage d'interfaces; les décisions qui necessitent un contexte qu'aucun outil n'a.
Zero inscription. Zero envoi. Même entrée, même sortie. Fait partie des Utilitaires de Développement et Programmation sur Kitmul.
Photo par Florian Olivo sur Unsplash.