
Nous avons déployé une fonctionnalité un mardi. Dès le jeudi, l'API renvoyait des timeouts. Le tableau de bord de monitoring montrait la latence p99 grimpant de 80 ms à 14 secondes en 48 heures. Rien n'avait changé, si ce n'est le nombre d'utilisateurs.
Le coupable : trois lignes de code qui semblaient parfaitement raisonnables lors de la revue :
const results = users.map(user => {
const match = permissions.find(p => p.userId === user.id);
return { ...user, role: match?.role ?? 'viewer' };
});
Propre. Lisible. Style fonctionnel. Mais aussi O(n * m) ; dans notre cas O(n^2), car les utilisateurs et les permissions croissaient au même rythme. À 200 utilisateurs, 40 000 comparaisons. À 2 000, 4 000 000. À 20 000, 400 000 000. La correction tenait en une ligne ; construire d'abord une Map :
const permMap = new Map(permissions.map(p => [p.userId, p.role]));
const results = users.map(user => ({
...user,
role: permMap.get(user.id) ?? 'viewer',
}));
O(n + m) au lieu de O(n * m). Problème résolu. Mais la vraie question est : pourquoi personne ne l'a détecté ?
Le piège O(n^2) se cache en pleine lumière
La complexité quadratique est la classe de performance la plus dangereuse en production. Non pas parce que c'est la plus lente ; O(2^n) et O(n!) sont bien pires. Mais parce qu'elle a l'air correcte. Elle passe la revue de code. Elle fonctionne en développement. Elle fonctionne même en pré-production si votre jeu de données de test est suffisamment petit. Puis elle arrive en production avec des volumes réels et tout s'effondre.
Le schéma est presque toujours le même : une opération de recherche imbriquée dans une itération. Array.prototype.find(), Array.prototype.includes(), Array.prototype.indexOf() ; ce sont toutes des opérations O(n). Placez-les dans une boucle et vous obtenez du O(n^2). Placez-les dans deux boucles imbriquées et vous obtenez du O(n^3). Les méthodes expressives de tableau en JavaScript rendent cela particulièrement facile à manquer, car le code se lit comme du texte naturel au lieu de ressembler à des boucles for imbriquées.
Voici cinq schémas réels que j'ai vus faire tomber des systèmes en production.
Schéma 1 : Le .includes() innocent dans un .filter()
// Looks clean, but O(n * m)
const activeUsers = allUsers.filter(u => activeIds.includes(u.id));
Si activeIds est un tableau de 10 000 entrées et allUsers en compte 50 000, vous effectuez 500 000 000 de comparaisons. Convertissez activeIds en Set et le nombre tombe à 50 000 :
const activeSet = new Set(activeIds);
const activeUsers = allUsers.filter(u => activeSet.has(u.id));
Set.has() est O(1). Ce seul changement vous fait passer de O(n * m) à O(n + m).
Schéma 2 : La déduplication par comparaison
// O(n^2) deduplication
const unique = items.filter((item, i) =>
items.findIndex(x => x.id === item.id) === i
);
Je vois ce schéma chaque semaine en revue de code. Le findIndex parcourt le tableau depuis le début pour chaque élément. Pour 10 000 éléments, cela représente jusqu'à 100 millions de comparaisons. La correction :
const seen = new Set();
const unique = items.filter(item => {
if (seen.has(item.id)) return false;
seen.add(item.id);
return true;
});
Ou encore plus simple avec une Map si vous avez besoin des objets complets :
const unique = [...new Map(items.map(i => [i.id, i])).values()];
Schéma 3 : La cascade .map().filter().map()
Celui-ci est subtil. Chaque méthode individuelle est O(n), et enchaîner trois opérations O(n) reste O(n) ; 3n n'est que n avec un facteur constant. Mais cela devient O(n^2) quand l'une de ces opérations dissimule une recherche :
const enriched = orders
.map(order => ({
...order,
customer: customers.find(c => c.id === order.customerId), // O(n) inside O(n)
}))
.filter(order => order.customer?.active)
.map(order => formatForDisplay(order));
Le pipeline fonctionnel a l'air élégant. Le .find() imbriqué le rend quadratique. Une table de correspondance pré-construite corrige le problème sans aucune perte de lisibilité.
Schéma 4 : L'aplatisseur d'arbre récursif
function flattenComments(comments) {
return comments.reduce((flat, comment) => {
flat.push(comment);
if (comment.replies) {
flat.push(...flattenComments(comment.replies));
}
return flat;
}, []);
}
L'opérateur de décomposition (spread) à l'intérieur du reduce crée un nouveau tableau à chaque appel récursif. Pour un arbre équilibré à n nœuds, la complexité est O(n^2) à cause de la copie de tableaux. La correction consiste à utiliser flat.push(...result) ou à passer l'accumulateur en paramètre :
function flattenComments(comments, result = []) {
for (const comment of comments) {
result.push(comment);
if (comment.replies) flattenComments(comment.replies, result);
}
return result;
}
Schéma 5 : La requête SQL dans une boucle (le problème N+1)
Celui-ci n'est pas spécifique à JavaScript. C'est l'antipattern de performance le plus courant dans les applications web :
const orders = await db.query('SELECT * FROM orders WHERE status = ?', ['active']);
for (const order of orders) {
order.items = await db.query('SELECT * FROM order_items WHERE order_id = ?', [order.id]);
}
1 requête pour les commandes + n requêtes pour les articles = n+1 requêtes au total. Avec 1 000 commandes, cela fait 1 001 allers-retours vers la base de données. Le problème de requête N+1 est bien documenté, mais il resurgit sans cesse parce que les ORM facilitent son déclenchement accidentel via le chargement paresseux (lazy loading).
La correction : un JOIN ou une requête groupée :
const orders = await db.query('SELECT * FROM orders WHERE status = ?', ['active']);
const orderIds = orders.map(o => o.id);
const items = await db.query('SELECT * FROM order_items WHERE order_id IN (?)', [orderIds]);

Comment détecter la complexité quadratique avant qu'elle n'atteigne la production
1. Profilez avec des volumes de données réalistes. Si votre suite de tests tourne avec 10 enregistrements alors que la production en compte 100 000, vos tests ne mesurent rien d'utile. Créez des jeux de données de benchmark qui correspondent à la cardinalité de production. La différence entre O(n) et O(n^2) est invisible à n=10 et catastrophique à n=10 000.
2. Recherchez .find(), .includes(), .indexOf() à l'intérieur de .map(), .filter(), .reduce(). Cette vérification mécanique attrape la majorité des schémas quadratiques accidentels dans les bases de code JavaScript. Si vous voulez visualiser à quel point les différentes classes de complexité évoluent différemment, entrez les valeurs dans un Comparateur de complexité Big O ; il trace toutes les classes de O(1) à O(n!) sur le même graphique.
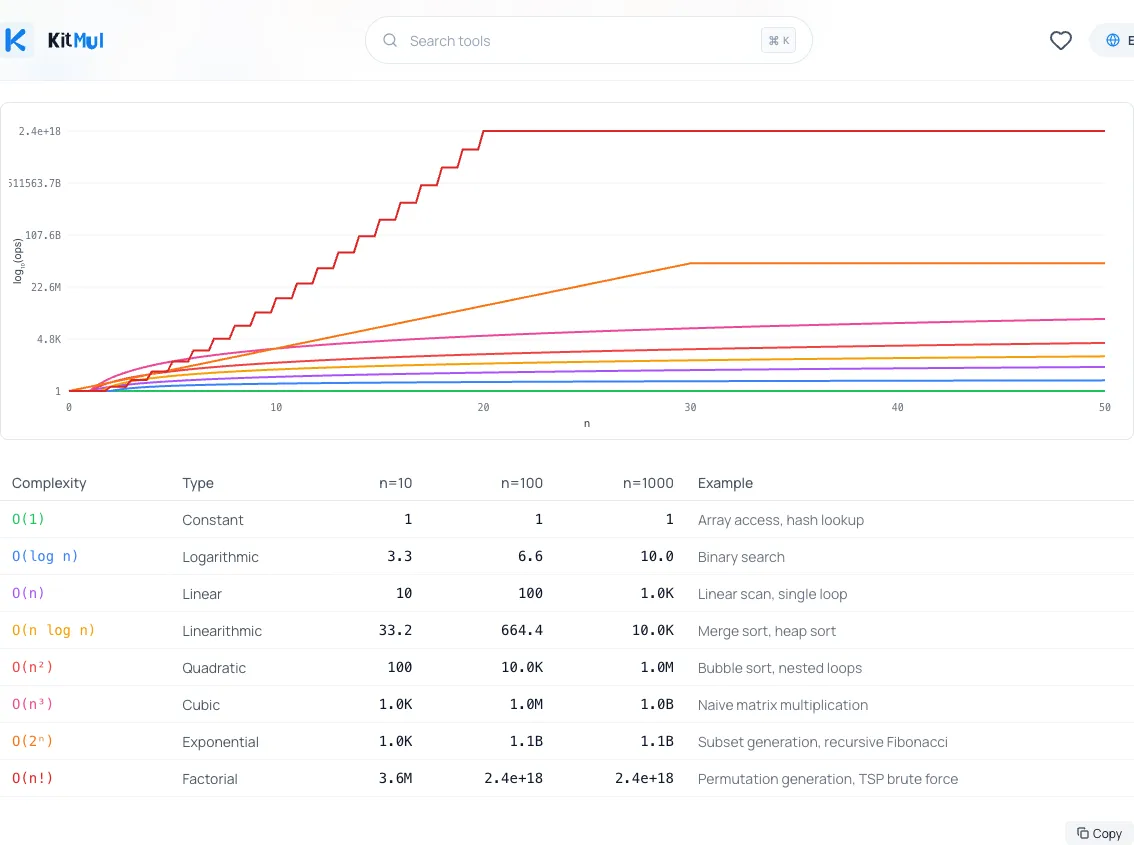
3. Ajoutez des annotations de complexité lors des revues de code. Quand vous relisez du code, posez-vous les questions : quel est n ? Quelle taille peut-il atteindre ? Quelle est la complexité de l'opération interne ? Rendre cela explicite évite la surprise du « ça marche très bien en dev ».
4. Définissez des budgets de latence avec des alertes. Si la latence p95 d'un endpoint dépasse 500 ms, prévenez quelqu'un. La complexité quadratique se manifeste généralement comme une dégradation progressive, pas comme une panne soudaine ; elle est donc parfaitement adaptée aux alertes basées sur la latence qui détectent la tendance avant que les utilisateurs ne la remarquent.
5. Connaissez votre bibliothèque standard. Array.sort() est O(n log n). Set.has() est O(1). Array.includes() est O(n). Map.get() est O(1). La différence entre utiliser une méthode d'Array et une méthode de Map/Set est souvent la différence entre O(n^2) et O(n). La documentation MDN sur les collections à clés détaille quand utiliser chacune.
La vraie leçon
Ce qui rend O(n^2) dangereux, ce n'est pas sa lenteur. C'est son invisibilité ; jusqu'au moment où il ne l'est plus. Chacun des schémas ci-dessus a passé la revue de code parce que le code était lisible, idiomatique et correct. Il ne passait simplement pas à l'échelle.
La complexité algorithmique n'est pas quelque chose que vous optimisez plus tard. C'est une décision de conception que vous prenez au moment où vous écrivez le code. La question n'est pas « est-ce que ça marche ? » mais « est-ce que ça marchera quand n sera 100 fois supérieur à mes données de test ? ».
Les recherches de Google montrent de manière constante que chaque tranche de 100 ms de latence supplémentaire a un impact mesurable sur les indicateurs métier. Un algorithme quadratique qui ajoute 50 ms à votre échelle actuelle et 5 000 ms à celle de l'année prochaine est une bombe à retardement.
Prenez l'habitude d'utiliser Map et Set par défaut. Questionnez chaque .find() et .includes() dans une boucle. Profilez avec des données de taille production. Le code qui fera tomber votre application n'aura pas l'air dangereux ; c'est précisément ce qui le rend dangereux.
Pour aller plus loin
Pour une référence complète sur les huit classes de complexité avec des graphiques interactifs, du code exécutable et des exercices d'entretien, consultez le Guide complet de la complexité Big O.
Confidentialité : Tous les outils de Kitmul fonctionnent entièrement dans votre navigateur. Aucune donnée n'est envoyée à un serveur. Pas de compte requis. Pas de suivi au-delà des analyses de base.