
J'ai échoué a mon premier entretien technique sur les algorithmes parce que j'ai répondu "ca depend" quand on m'a demande la complexité temporelle d'une fonction de recherche. L'examinateur attendait O(log n). Je savais que c'etait une recherche binaire. Je savais même que c'etait logarithmique. Mais j'ai panique et je me suis mis a divaguer sur les lignes de cache, la prediction de branchement et la question de savoir si le tableau tenait dans le L1. Les yeux de l'examinateur se sont vitrifies. "Ça depend" est techniquement correct, mais pratiquement inutile quand quelqu'un veut savoir si votre solution fonctionnera encore lorsque l'entrée passera de 1 000 a 1 000 000.
Cet entretien m'a appris quelque chose qu'il m'a fallu des années pour interioriser pleinement : la notation Big O ne vise pas la précision. Elle décrit la forme de la croissance. Elle vous dit comment un algorithme se comporte lorsque l'entrée augmente ; pas le nombre exact d'operations, pas le temps reel d'exécution, mais la courbe.
Et une fois que vous voyez les courbes, tout devient limpide.
Pourquoi Big O compte au-dela des entretiens
Soyons directs : la plupart des développeurs en poste que je connais ont appris Big O pour les entretiens et l'ont aussitot oublie. C'est une erreur.
L'année dernière, j'avais un service en production qui fonctionnait parfaitement avec 500 utilisateurs et s'effondrait a 5 000. Le coupable etait une boucle imbriquée que personne n'avait remarquee lors de la revue de code. Deux appels .filter() à l'interieur d'un .map(). Le code avait l'air propre. Se lisait agreablement. Et sa complexité etait O(n^3). Avec 500 éléments, l'exécution prenait 120 ms. Avec 5 000 éléments ; 12 secondes. Avec 50 000 éléments, cela aurait pris 20 minutes.
La complexité temporelle fait la différence entre "ca marche sur ma machine" et "ca marche en production". C'est la raison pour laquelle certains systèmes montent en charge avec elegance tandis que d'autres heurtent un mur. Ce n'est pas academique. C'est la chose la plus pratique en informatique.
Les huit classes de complexité ; du vrai code, de vraies consequences
Passons en revue chaque classe avec du code reel que vous pouvez exécuter. J'utilisé JavaScript parce que la plupart des développeurs le lisent comme du pseudocode, mais les concepts sont independants du langage.
O(1) ; temps constant
function getFirst(arr) {
return arr[0];
}
Peu importe que le tableau contienne 10 éléments ou 10 millions. Une seule operation. Les recherches dans les tables de hachage sont aussi O(1) en moyenne ; c'est pourquoi vous utilisez un Map ou un objet quand vous avez besoin d'un accès rapide par clé. Le "en moyenne" a son importance (les collisions de hachage existent), mais en pratique c'est la référence absolue.
O(log n) ; logarithmique
function binarySearch(sorted, target) {
let lo = 0, hi = sorted.length - 1;
while (lo <= hi) {
const mid = Math.floor((lo + hi) / 2);
if (sorted[mid] === target) return mid;
if (sorted[mid] < target) lo = mid + 1;
else hi = mid - 1;
}
return -1;
}
La recherche binaire divise le problème par deux à chaque étape. Chercher parmi 1 milliard d'éléments tries ? Environ 30 comparaisons. C'est la magie des logarithmes. Chaque fois que vous doublez l'entrée, vous n'ajoutez qu'une seule étape supplémentaire. Les index de bases de données fonctionnent sur ce principe (les B-trees sont essentiellement une recherche binaire multidirectionnelle).
O(n) ; lineaire
function findMax(arr) {
let max = arr[0];
for (const val of arr) {
if (val > max) max = val;
}
return max;
}
On parcourt chaque élément une fois. Doublez l'entrée, doublez le temps. C'est souvent le mieux que vous puissiez faire quand vous devez examiner toutes les données. Si quelqu'un vous demande d'"optimiser" un parcours lineaire qui a reellement besoin de voir chaque élément, il vous demande un miracle.
O(n log n) ; linearithmique
C'est la ou vivent les tris par comparaison efficaces. Merge sort, quicksort (cas moyen), heapsort. Il existe une borne inferieure prouvee ici ; il est impossible de trier n éléments en comparant des paires en moins de O(n log n) comparaisons. C'est une impossibilite mathematique, demontree via les arbres de décision.
function mergeSort(arr) {
if (arr.length <= 1) return arr;
const mid = Math.floor(arr.length / 2);
const left = mergeSort(arr.slice(0, mid));
const right = mergeSort(arr.slice(mid));
return merge(left, right);
}
function merge(a, b) {
const result = [];
let i = 0, j = 0;
while (i < a.length && j < b.length) {
result.push(a[i] <= b[j] ? a[i++] : b[j++]);
}
return result.concat(a.slice(i), b.slice(j));
}
La complexité temporelle de merge sort est O(n log n) dans tous les cas ; pire, moyen et meilleur. C'est pourquoi il est le tri par défaut dans de nombreuses bibliotheques standard. Sa complexité spatiale est cependant O(n) ; il faut ce tableau auxiliaire. Des compromis partout.
O(n^2) ; quadratique
function bubbleSort(arr) {
const n = arr.length;
for (let i = 0; i < n; i++) {
for (let j = 0; j < n - i - 1; j++) {
if (arr[j] > arr[j + 1]) {
[arr[j], arr[j + 1]] = [arr[j + 1], arr[j]];
}
}
}
return arr;
}
Deux boucles imbriquées sur l'entrée. 1 000 éléments signifient environ 1 000 000 d'operations. 10 000 éléments signifient environ 100 000 000. C'est la que vivent les bugs du type "ca marche bien en développement". Le .filter() imbriqué dans un .map() que j'ai mentionne plus tot ? Le piege quadratique classique deguise en syntaxe fonctionnelle.
O(2^n) ; exponentiel
function fibonacci(n) {
if (n <= 1) return n;
return fibonacci(n - 1) + fibonacci(n - 2);
}
La suite de Fibonacci recursive naive. Chaque appel se divise en deux appels supplémentaires. A n=30, vous effectuez plus d'un milliard d'appels de fonctions. A n=50, votre machine capitule. La solution est la memoisation (qui ramene la complexité a O(n)) ou une approche iterative. Mais la version naive est l'exemple canonique illustrant pourquoi les algorithmes exponentiels sont en pratique inutilisables pour tout ce qui dépasse de petites entrées.
O(n!) ; factoriel
function permutations(arr) {
if (arr.length <= 1) return [arr];
const result = [];
for (let i = 0; i < arr.length; i++) {
const rest = [...arr.slice(0, i), ...arr.slice(i + 1)];
for (const perm of permutations(rest)) {
result.push([arr[i], ...perm]);
}
}
return result;
}
La génération de toutes les permutations. 10 éléments = 3 628 800 permutations. 15 éléments = plus de 1 300 milliards. 20 éléments = plus que le nombre de secondes depuis le début de l'univers. Le problème du voyageur de commerce vit ici (force brute). C'est pourquoi les problèmes NP-difficiles sont difficiles ; si vous trouvez une solution efficace à l'un d'entre eux, allez chercher votre prix du millenaire.
Voir les courbes rend les choses concretes
J'ai construit un Comparateur de complexité Big O parce que fixer une notation sur une page ne transmet pas la différence viscerale entre ces classes. Quand vous tracez O(n), O(n log n) et O(n^2) sur le même graphique, la courbe quadratique monte si agressivement que la lineaire semble plate en comparaison. Et O(2^n) et O(n!) font paraitre O(n^2) plat.
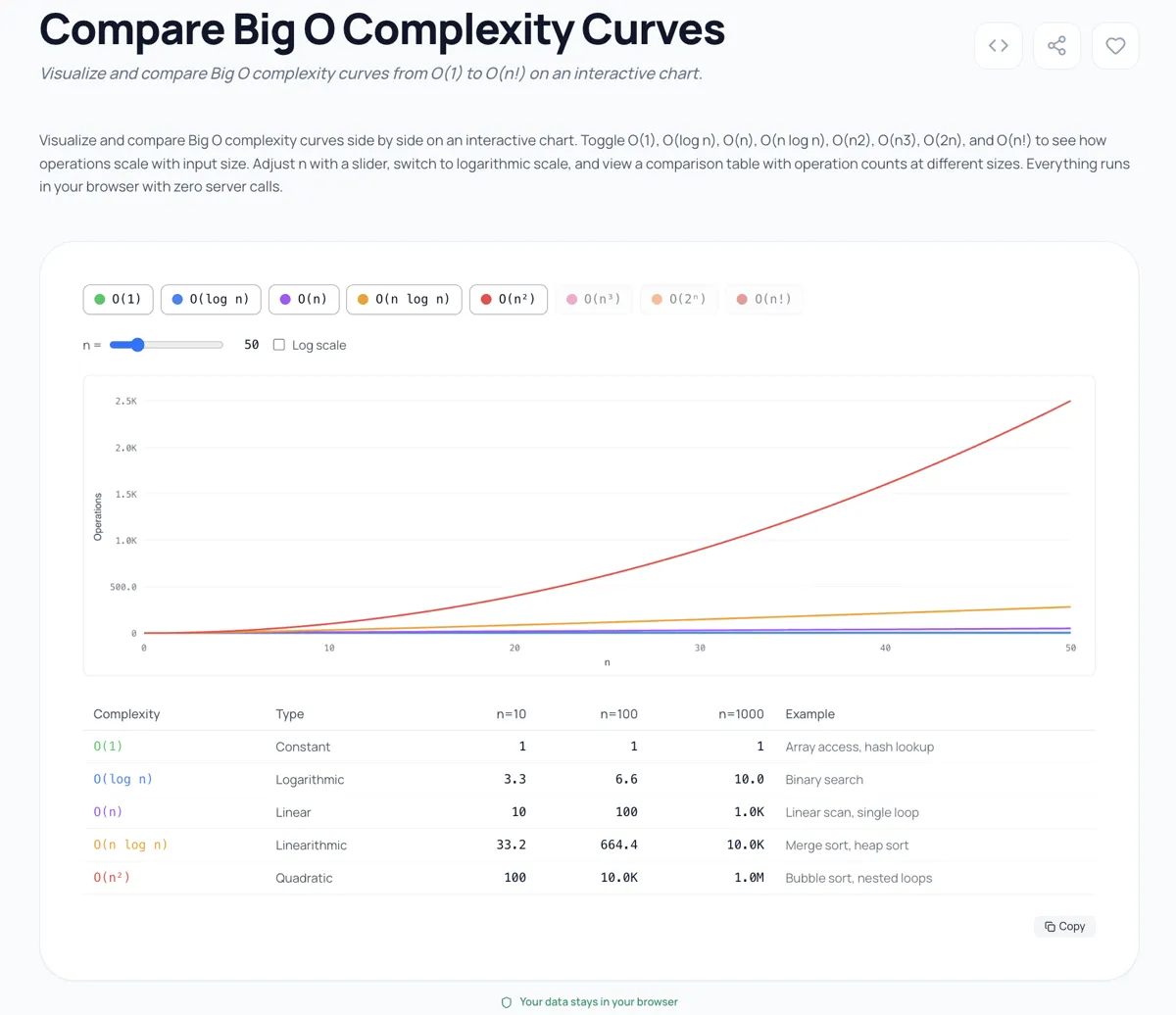
L'outil trace les huit classes simultanement sur une échelle logarithmique afin que vous puissiez voir les relations. Jouez avec le curseur de taille d'entrée et observez ce qui se passe au-dessus de n=20. Les courbes exponentielle et factorielle sortent complètement du graphique. Ce n'est pas une exageration pour l'effet visuel ; ce sont les valeurs reelles. A n=25, O(n!) vaut 15 511 210 043 330 985 984 000 000. Votre solution O(n^2) a soudainement l'air rapide en comparaison.
Trois erreurs courantes a propos de Big O
1. Les constantes comptent en pratique. Big O elimine les constantes. O(2n) et O(n) sont tous deux "O(n)". Mais dans du code reel, un facteur constant de 10x fait la différence entre une réponse de 100 ms et une réponse d'une seconde. Un algorithme avec une boucle interne serree et une bonne localite de cache en O(n log n) ecrasera un algorithme theoriquement equivalent en O(n log n) qui malmene la memoire. CLRS (la bible des algorithmes ; Introduction to Algorithms de Cormen, Leiserson, Rivest et Stein) le reconnait ; les "facteurs constants" qu'il evacue dans les preuves deviennent des décisions d'ingenierie en production.
2. La complexité amortie n'est pas la complexité moyenne. Quand on dit que ArrayList.add() est O(1) amorti, cela signifie que parfois c'est O(n) (quand il faut redimensionner), mais que ces operations couteuses sont reparties de sorte que sur n operations, le coût total est O(n). C'est différent de dire que le cas moyen est O(1). L'amortissement est une garantie sur une sequence ; le cas moyen depend de la distribution des entrées.
3. La complexité spatiale est tout aussi importante. J'ai vu des ingenieurs optimiser la complexité temporelle de O(n^2) a O(n) et celebrer ; pour découvrir ensuite que leur solution O(n) utilisait O(n^2) en espace. Sur un serveur avec 4 Go de RAM traitant 10 millions d'enregistrements, la complexité spatiale vous acheve plus vite que la complexité temporelle. Posez toujours les deux questions : combien de temps cela prend-il, et combien de memoire cela nécessité-t-il ?
Comment analyser votre propre code
Voici ma méthode étape par étape. Je l'applique à chaque fois que je relis du code qui traité des entrées de taille variable :
- Identifiez l'entrée. Quelle variable détermine la taille ? En général, c'est la longueur d'un tableau, le nombre de lignes, le nombre de nœuds.
- Reperer les boucles. Chaque boucle qui itere sur l'entrée contribue au minimum a O(n). Les boucles imbriquées multiplient.
- Attention aux boucles cachees. Les méthodes de tableaux comme
.filter(),.map(),.indexOf(),.includes()sont toutes O(n). En chainer trois reste O(n) ; en imbriquer une dans une autre donne O(n^2). - Vérifiez les appels recursifs. Combien de fois la fonction s'appelle-t-elle elle-même ? Une recursion binaire (deux appels) est O(2^n) sans memoisation. Si la recursion divise le problème par deux à chaque fois, c'est O(log n).
- Tenez compte des operations natives.
Array.sort()est O(n log n).Set.has()est O(1).Array.includes()est O(n). Connaissez votre bibliotheque standard.

Preparation aux entretiens ; cinq schémas qui couvrent 80 % des questions
Après avoir passe environ 200 entretiens de programmation (des deux cotes de la table), voici mon aide-memoire Big O pour les schémas qui reviennent constamment :
1. Table de hachage pour eliminer une boucle imbriquée. Si votre approche brute force est O(n^2) parce que vous cherchez un complement ou une correspondance dans une boucle interne, une table de hachage la rend O(n). Exemple classique : two sum.
2. Trier d'abord, puis utiliser une recherche binaire ou deux pointeurs. Le tri coute O(n log n) en amont mais deverrouille des recherches en O(log n). Total : O(n log n). Presque toujours meilleur que la force brute en O(n^2).
3. Fenêtre glissante pour les problèmes de sous-tableau ou sous-chaine. Transforme une force brute O(n^2) ou O(n^3) en O(n) en maintenant une fenêtre qui avance dans les données. Sous-tableau maximal, plus longue sous-chaine sans repetition ; tout cela releve de la fenêtre glissante.
4. Diviser pour regner pour O(n log n). Divisez le problème, resolvez les moities recursivement, combinez. Merge sort est l'exemple du manuel, mais ce schéma apparait dans la paire de points la plus proche, le comptage d'inversions et la multiplication matricielle.
5. Programmation dynamique pour eliminer la recursion exponentielle. Memoisez les sous-problèmes chevauchants pour faire passer O(2^n) a O(n) ou O(n^2). Fibonacci, rendu de monnaie, plus longue sous-sequence commune. Si vous reperer des sous-problèmes chevauchants et une sous-structure optimale, pensez à la programmation dynamique.
Ces cinq schémas ne couvrent pas tout, mais ils couvrent suffisamment pour réussir la plupart des entretiens algorithmiques. Pour aller plus loin, je recommandé sincèrement de travailler les problèmes avec un comparateur visuel de complexité ouvert. Voir ou votre solution se situe sur la courbe construit l'intuition plus vite que la mémorisation de regles.
Explorez d'autres outils
Si vous avez trouve le Comparateur de complexité Big O utile, découvrez le reste de la collection Visualiseurs et Logique sur Kitmul. Nous proposons des outils de visualisation de regex, d'exploration d'AST et d'autres fondamentaux de l'informatique. Tous gratuits, tous dans le navigateur, tous prives ; vos données ne quittent jamais votre machine.
Confidentialité : Chaque outil sur Kitmul fonctionne entièrement dans votre navigateur. Aucune donnée n'est envoyée à un serveur. Aucun compte requis. Aucun suivi au-dela des statistiques de base.