
La semaine dernière, un ami m'a envoye un memo vocal. "J'ai trouve une ligne de basse incroyable dans un vieux morceau soul," a-t-il dit, "mais je ne peux pas l'isoler sans payer 30 dollars par mois pour un service cloud qui veut mon email, ma carte de credit et probablement mon premier-ne."
Il n'a pas tort. Le paysage de la séparation de stems audio en 2026 est un bazar de murs d'abonnement et d'envois vers le cloud. La plupart des outils envoient votre audio vers un GPU distant, le traitént et renvoient les stems. Vous obtenez des résultats en minutes, certes, mais votre idée de remix inedite vit désormais sur le serveur de quelqu'un d'autre.
Je voulais voir si tout le pipeline pouvait tourner localement, dans un onglet de navigateur, avec zero requêtes réseau après le chargement initial de la page.
Il s'avere que oui.
Ce qu'est reellement la séparation de stems
Pour ceux qui ne connaissent pas : la séparation de sources (aussi appelee demixing ou unmixing) est le processus de decomposition d'un signal audio mixe en ses sources constitutives. Un morceau pop typique est la somme des voix, de la batterie, de la basse et de tout le reste (guitares, synthetiseurs, claviers, cordes). Le travail de l'IA est d'inverser cette somme.
L'état de l'art remonte a Demucs de Meta, un modèle hybride qui opéré simultanement dans le domaine temporel et frequentiel. Il a été entraine sur des milliers d'enregistrements multipistes ou les stems individuels sont connus, apprenant ainsi les empreintes spectrales qui distinguent une grosse caisse d'une basse d'une voix humaine.
Le point interessant est que Demucs v4 (htdemucs) utilisé une architecture transformer fusionnee avec un U-Net convolutionnel. Le transformer gère les dependances a longue distance (comme une note vocale soutenue pendant un fill de batterie), tandis que le U-Net capture les motifs spectraux locaux. Le résultat est significativement moins de "saignement" entre les stems compare aux approches précédentes.
L'exécuter dans le navigateur avec ONNX + WebAssembly
Le Audio Stem Splitter sur Kitmul charge une version ONNX exportee du modèle Demucs et exécuté l'inference entièrement via ONNX Runtime Web supporte par WebAssembly. Pas de serveur. Pas d'envoi. Les octets audio ne quittent jamais votre machine.
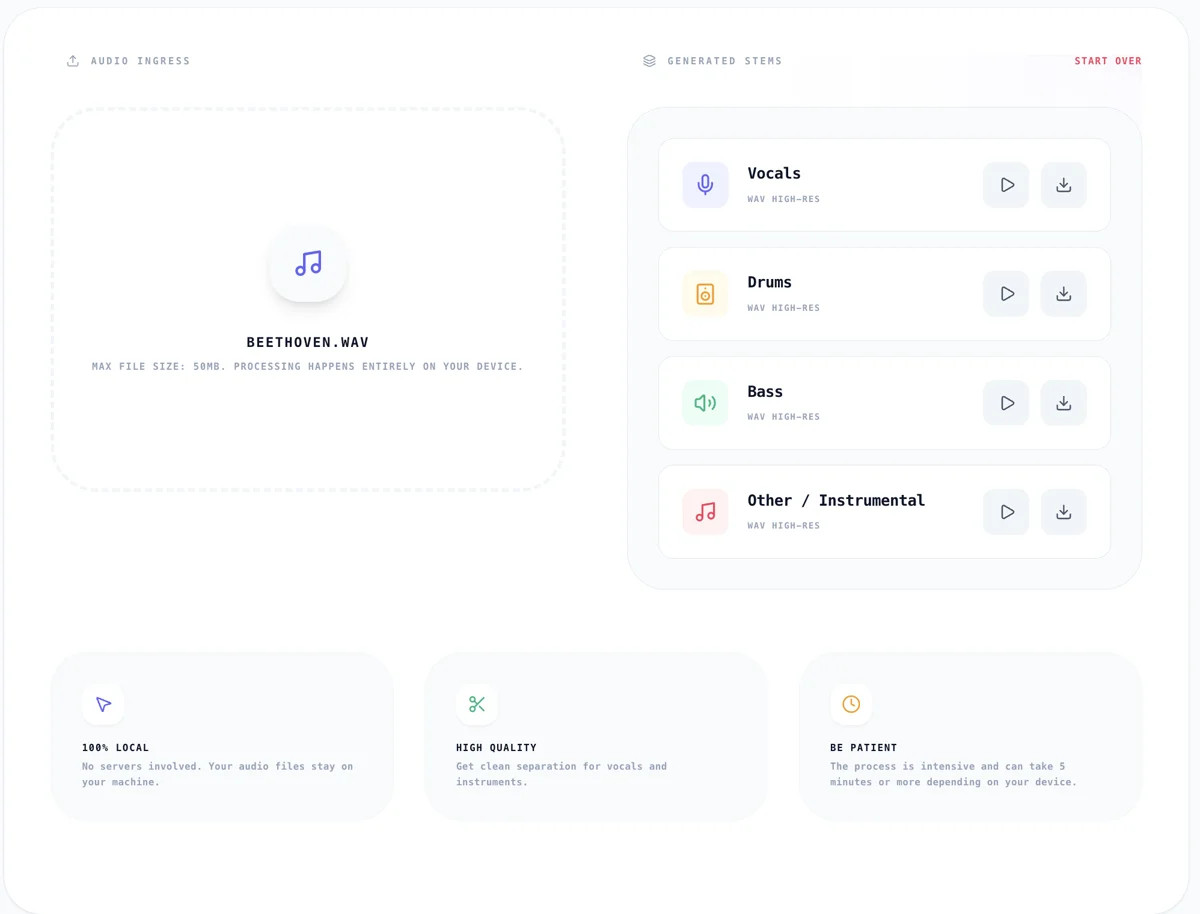
Voici ce qui se passe quand vous deposez un fichier audio :
- Le fichier est decode en PCM brut via
decodeAudioDatade la Web Audio API - Si le taux d'echantillonnage n'est pas 44100 Hz, il est reechantillonne via un
OfflineAudioContext - L'audio est fragmente et alimente au modèle ONNX dans un Web Worker pour ne pas bloquer le fil de l'UI
- Le modèle produit quatre masques spectraux (voix, batterie, basse, autre)
- Chaque masque est applique au spectrogramme original pour produire des stems isoles
- Les stems sont encodes en WAV pour téléchargement
Tout le pipeline est embarrassingly parallel en théorie, mais en pratique vous êtes limite par le fil unique WASM et la RAM disponible. Un morceau de 4 minutes prend environ 3-5 minutes sur un laptop moderne. Pas rapide, mais pas mal pour exécuter un réseau neuronal dans un onglet de navigateur.
L'argument de confidentialité que personne ne souleve
Chaque fois que vous envoyez un morceau a LALAL.AI, Moises ou Stem Roller, vous transmettez un audio potentiellement protégé par le droit d'auteur (ou votre propre travail inedit) à un serveur tiers. Leurs politiques de confidentialité disent généralement qu'ils "ne stockent pas vos fichiers de manière permanente," mais le mot opératif est "permanente."
Avec le traitément côté client, la question de la retention des données est sans objet. Il n'y a rien a retenir. Votre navigateur téléchargé les poids du modèle une fois (mis en cache pour les visites futures), exécuté les calculs localement et produit des fichiers de sortie qui n'existent que dans la memoire de votre appareil jusqu'a ce que vous les sauvegardiez explicitement.
Cela importe particulièrement pour :
- Les producteurs travaillant avec du materiel inedit
- Les DJs preparant des sets avec des pistes protégées
- Les professeurs de musique creant des pistes de pratique pour les étudiants
- Les analystes audio judiciaire travaillant avec des enregistrements sensibles

Cas d'utilisation pratiques auxquels je ne m'attendais pas
Le cas d'utilisation evident est le karaoke (supprimer les voix, chanter par-dessus). Mais j'ai vu des gens utiliser la séparation de stems pour des choses que je n'avais pas envisagees :
Aide à la transcription. Une pianiste de jazz m'a raconte qu'elle séparé le stem de piano d'enregistrements classiques pour transcrire les voicings plus precisement. Quand on peut entendre le piano isolement, on capte des détails harmoniques qui se perdent dans le mix complet.
Archeologie de samples. Les producteurs hip-hop fouillent dans des rips de vinyle à la recherche de boucles. Isoler le break de batterie d'un morceau funk des années 70 vous donne un sample propre sans avoir a egaliser les cuivres à la main.
Accessibilité. Quelqu'un malentendant a mentionne que renforcer le stem vocal et atténuer l'instrumental rend le contenu riche en dialogue (podcasts avec lits musicaux, scenes de films) significativement plus clair.
Tests A/B de mixages. Si vous apprenez a mixer, séparer un morceau professionnel en stems vous permet de reconstruire le mix a zero dans votre DAW et comparer vos choix avec l'équilibre original.
Les limites du modèle (avis honnete)
La séparation n'est pas parfaite. Voici ou le modèle a du mal :
- L'audio très compressé ou a faible debit produit plus d'artefacts. Commencez avec du MP3 320kbps ou du WAV si possible.
- Les arrangements denses avec de nombreux instruments superposes saignent davantage dans le stem "autre." Une piste guitare-et-voix seule se séparé a merveille ; une production wall-of-sound à la Phil Spector, moins.
- Les enregistrements mono perdent les indices spatiaux qui aident le modèle a distinguer les sources. Le stereo est toujours mieux.
- Les fichiers très longs (>10 minutes) mettront à l'epreuve la RAM de votre appareil. La limite de 50 Mo est la pour une raison.
Si vous avez besoin de résultats de qualité studio pour une sortie commerciale, vous voudrez probablement iZotope RX ou le CLI complet de Demucs sur un GPU. Mais pour des workflows rapides, l'exploration creative ou les situations ou la confidentialité compte plus que la perfection, la séparation dans le navigateur est veritablement utile.

Comment il se compare à la concurrence
| Caractéristique | Kitmul Stem Splitter | LALAL.AI | Moises | Demucs CLI |
|---|---|---|---|---|
| Traitement | 100% local (navigateur) | GPU cloud | GPU cloud | GPU/CPU local |
| Prix | Gratuit | $15-30/mois | $4-17/mois | Gratuit (OSS) |
| Confidentialité | Aucun envoi | Envoi requis | Envoi requis | Aucun envoi |
| Configuration | Zero | Compte + paiement | Compte + paiement | Python + ffmpeg |
| Qualité | Bonne (ONNX htdemucs) | Très bonne | Très bonne | La meilleure (modèle complet) |
| Vitesse | 3-5 min/morceau | ~30 sec | ~1 min | ~30 sec (GPU) |
Le compromis est clair : vous sacrifiez un peu de vitesse et de qualité marginale pour zero configuration, zero coût et une confidentialité totale. Pour la plupart des workflows non professionnels, c'est le bon choix.
La Web Audio API est plus capable que vous ne le pensez
Construire cela a renforce quelque chose que je ne cesse de découvrir : le stack audio du navigateur est sérieusement sous-estime. Entre AudioContext pour le traitément en temps reel, OfflineAudioContext pour le rendu hors-ligne, AudioWorklet pour du DSP personnalisé sur un fil dedie, et maintenant ONNX Runtime Web pour exécuter des réseaux neuronaux, vous pouvez construire des outils de production audio legitimes qui auraient nécessité des applications natives il y a cinq ans.
Essayez-le
Le Audio Stem Splitter est gratuit, fonctionne dans tout navigateur moderne et traité tout localement. Deposez un MP3 ou WAV, attendez quelques minutes et téléchargez vos pistes isolees de voix, batterie, basse et instruments.
Si la production musicale vous interesse, le Loop Music Creator (DAW dans le navigateur) et le YouTube Loop Mix (outil DJ double platine) se combinent bien avec les stems séparés pour des workflows de remix.
Les trois outils fonctionnent dans votre navigateur. Sans comptes. Sans envois. Sans abonnements.